 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Refining Diffusion Samplers: Enabling Parallelization via Parareal Iterations
Dec 11, 2024In diffusion models, samples are generated through an iterative refinement process, requiring hundreds of sequential model evaluations. Several recent methods have introduced approximations (fewer discretization steps or distillation) to trade off speed at the cost of sample quality. In contrast, we introduce Self-Refining Diffusion Samplers (SRDS) that retain sample quality and can improve latency at the cost of additional parallel compute. We take inspiration from the Parareal algorithm, a popular numerical method for parallel-in-time integration of differential equations. In SRDS, a quick but rough estimate of a sample is first created and then iteratively refined in parallel through Parareal iterations. SRDS is not only guaranteed to accurately solve the ODE and converge to the serial solution but also benefits from parallelization across the diffusion trajectory, enabling batched inference and pipelining. As we demonstrate for pre-trained diffusion models, the early convergence of this refinement procedure drastically reduces the number of steps required to produce a sample, speeding up generation for instance by up to 1.7x on a 25-step StableDiffusion-v2 benchmark and up to 4.3x on longer trajectories.
Predicting emergence of crystals from amorphous matter with deep learning
Oct 02, 2023Crystallization of the amorphous phases into metastable crystals plays a fundamental role in the formation of new matter, from geological to biological processes in nature to synthesis and development of new materials in the laboratory. Predicting the outcome of such phase transitions reliably would enable new research directions in these areas, but has remained beyond reach with molecular modeling or ab-initio methods. Here, we show that crystallization products of amorphous phases can be predicted in any inorganic chemistry by sampling the crystallization pathways of their local structural motifs at the atomistic level using universal deep learning potentials. We show that this approach identifies the crystal structures of polymorphs that initially nucleate from amorphous precursors with high accuracy across a diverse set of material systems, including polymorphic oxides, nitrides, carbides, fluorides, chlorides, chalcogenides, and metal alloys. Our results demonstrate that Ostwald's rule of stages can be exploited mechanistically at the molecular level to predictably access new metastable crystals from the amorphous phase in material synthesis.
VeLO: Training Versatile Learned Optimizers by Scaling Up
Nov 17, 2022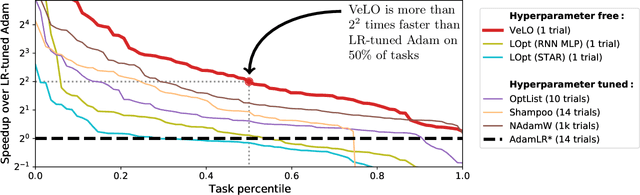
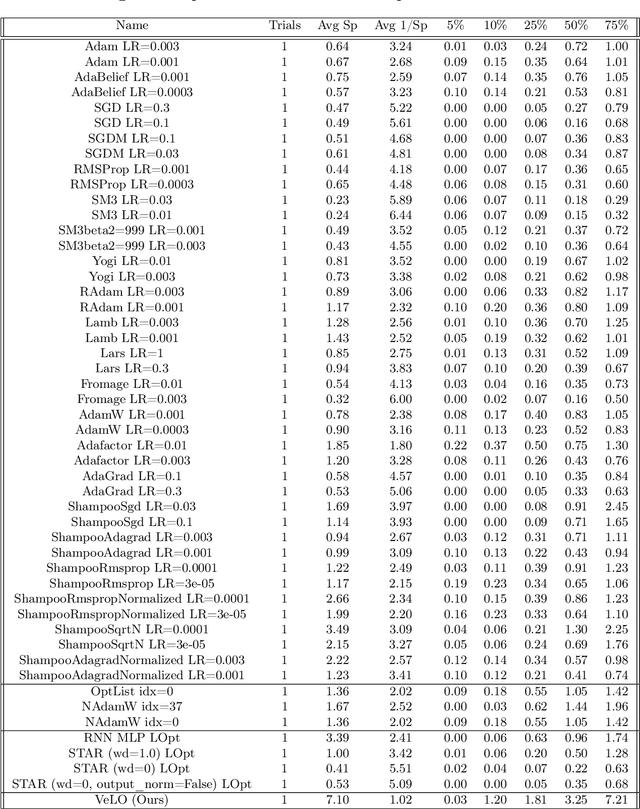
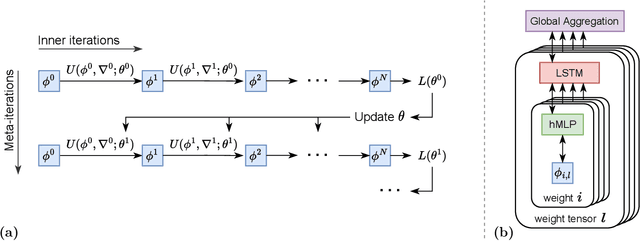
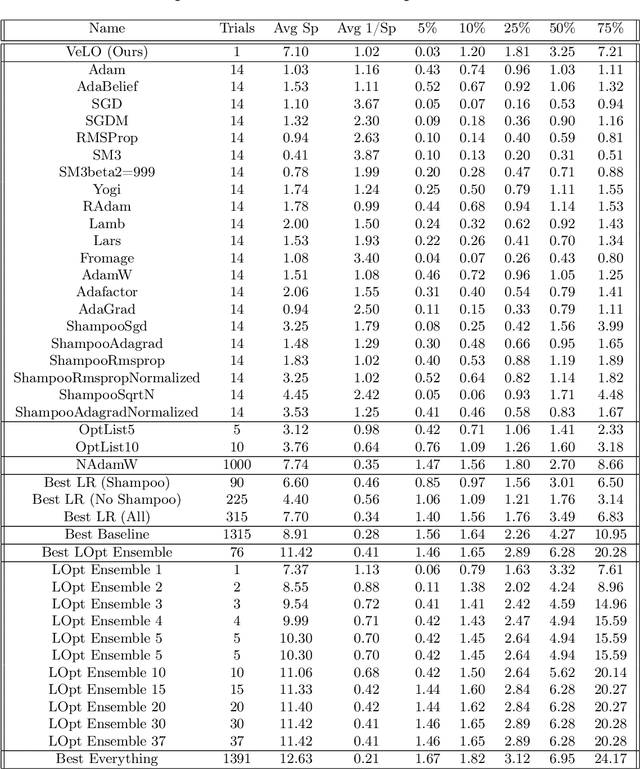
While deep learning models have replaced hand-designed features across many domains, these models are still trained with hand-designed optimizers. In this work, we leverage the same scaling approach behind the success of deep learning to learn versatile optimizers. We train an optimizer for deep learning which is itself a small neural network that ingests gradients and outputs parameter updates. Meta-trained with approximately four thousand TPU-months of compute on a wide variety of optimization tasks, our optimizer not only exhibits compelling performance, but optimizes in interesting and unexpected ways. It requires no hyperparameter tuning, instead automatically adapting to the specifics of the problem being optimized. We open source our learned optimizer, meta-training code, the associated train and test data, and an extensive optimizer benchmark suite with baselines at velo-code.github.io.
Learn2Hop: Learned Optimization on Rough Landscapes
Jul 20, 2021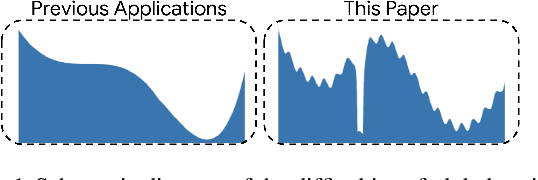

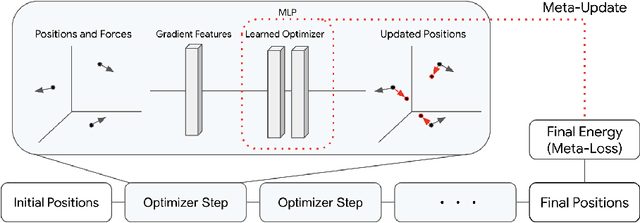
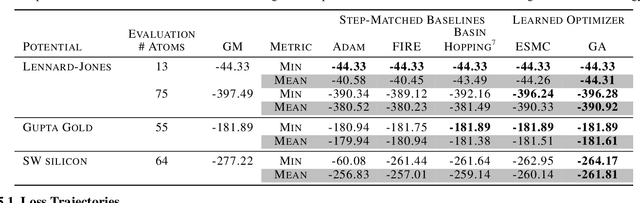
Optimization of non-convex loss surfaces containing many local minima remains a critical problem in a variety of domains, including operations research, informatics, and material design. Yet, current techniques either require extremely high iteration counts or a large number of random restarts for good performance. In this work, we propose adapting recent developments in meta-learning to these many-minima problems by learning the optimization algorithm for various loss landscapes. We focus on problems from atomic structural optimization--finding low energy configurations of many-atom systems--including widely studied models such as bimetallic clusters and disordered silicon. We find that our optimizer learns a 'hopping' behavior which enables efficient exploration and improves the rate of low energy minima discovery. Finally, our learned optimizers show promising generalization with efficiency gains on never before seen tasks (e.g. new elements or compositions). Code will be made available shortly.
Does Data Augmentation Benefit from Split BatchNorms
Oct 15, 2020


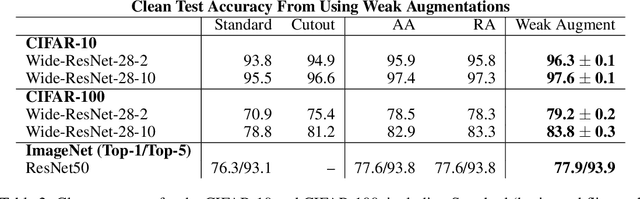
Data augmentation has emerged as a powerful technique for improving the performance of deep neural networks and led to state-of-the-art results in computer vision. However, state-of-the-art data augmentation strongly distorts training images, leading to a disparity between examples seen during training and inference. In this work, we explore a recently proposed training paradigm in order to correct for this disparity: using an auxiliary BatchNorm for the potentially out-of-distribution, strongly augmented images. Our experiments then focus on how to define the BatchNorm parameters that are used at evaluation. To eliminate the train-test disparity, we experiment with using the batch statistics defined by clean training images only, yet surprisingly find that this does not yield improvements in model performance. Instead, we investigate using BatchNorm parameters defined by weak augmentations and find that this method significantly improves the performance of common image classification benchmarks such as CIFAR-10, CIFAR-100, and ImageNet. We then explore a fundamental trade-off between accuracy and robustness coming from using different BatchNorm parameters, providing greater insight into the benefits of data augmentation on model performance.
What Happens To BERT Embeddings During Fine-tuning?
Apr 29, 2020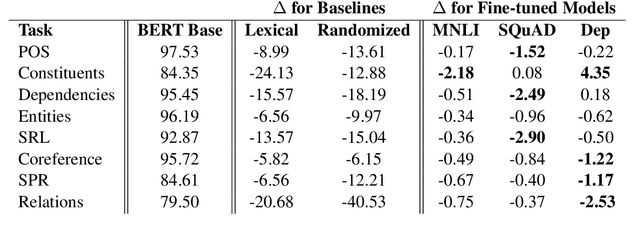
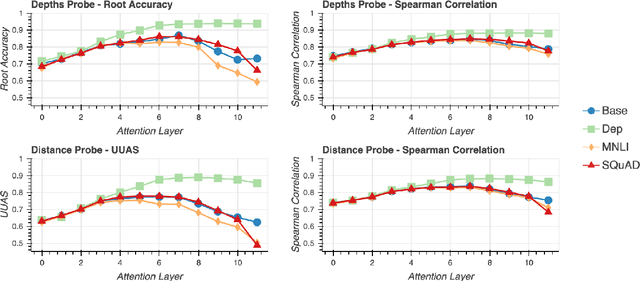

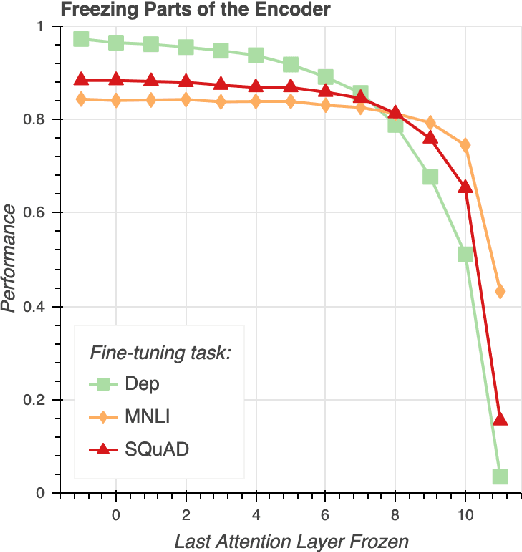
While there has been much recent work studying how linguistic information is encoded in pre-trained sentence representations, comparatively little is understood about how these models change when adapted to solve downstream tasks. Using a suite of analysis techniques (probing classifiers, Representational Similarity Analysis, and model ablations), we investigate how fine-tuning affects the representations of the BERT model. We find that while fine-tuning necessarily makes significant changes, it does not lead to catastrophic forgetting of linguistic phenomena. We instead find that fine-tuning primarily affects the top layers of BERT, but with noteworthy variation across tasks. In particular, dependency parsing reconfigures most of the model, whereas SQuAD and MNLI appear to involve much shallower processing. Finally, we also find that fine-tuning has a weaker effect on representations of out-of-domain sentences, suggesting room for improvement in model generalization.