 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Learn2Hop: Learned Optimization on Rough Landscapes
Jul 20, 2021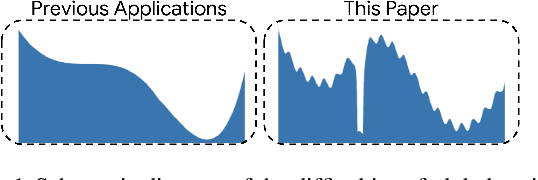

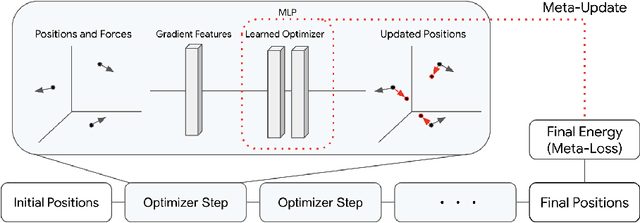
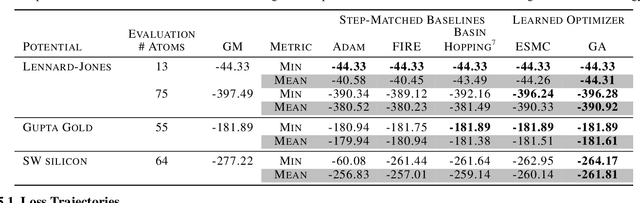
Optimization of non-convex loss surfaces containing many local minima remains a critical problem in a variety of domains, including operations research, informatics, and material design. Yet, current techniques either require extremely high iteration counts or a large number of random restarts for good performance. In this work, we propose adapting recent developments in meta-learning to these many-minima problems by learning the optimization algorithm for various loss landscapes. We focus on problems from atomic structural optimization--finding low energy configurations of many-atom systems--including widely studied models such as bimetallic clusters and disordered silicon. We find that our optimizer learns a 'hopping' behavior which enables efficient exploration and improves the rate of low energy minima discovery. Finally, our learned optimizers show promising generalization with efficiency gains on never before seen tasks (e.g. new elements or compositions). Code will be made available shortly.
Temperature check: theory and practice for training models with softmax-cross-entropy losses
Oct 14, 2020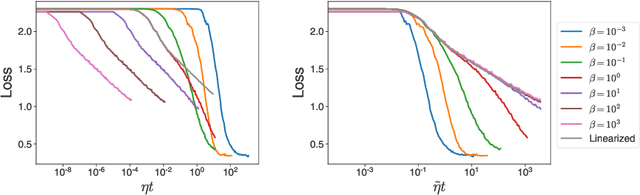
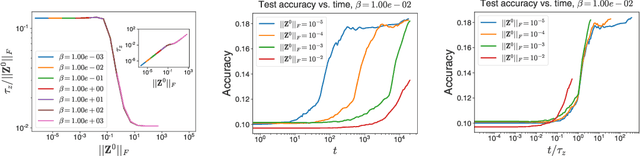

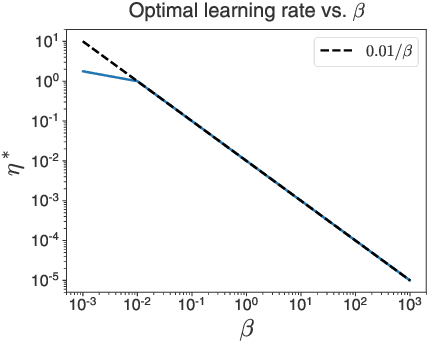
The softmax function combined with a cross-entropy loss is a principled approach to modeling probability distributions that has become ubiquitous in deep learning. The softmax function is defined by a lone hyperparameter, the temperature, that is commonly set to one or regarded as a way to tune model confidence after training; however, less is known about how the temperature impacts training dynamics or generalization performance. In this work we develop a theory of early learning for models trained with softmax-cross-entropy loss and show that the learning dynamics depend crucially on the inverse-temperature $\beta$ as well as the magnitude of the logits at initialization, $||\beta{\bf z}||_{2}$. We follow up these analytic results with a large-scale empirical study of a variety of model architectures trained on CIFAR10, ImageNet, and IMDB sentiment analysis. We find that generalization performance depends strongly on the temperature, but only weakly on the initial logit magnitude. We provide evidence that the dependence of generalization on $\beta$ is not due to changes in model confidence, but is a dynamical phenomenon. It follows that the addition of $\beta$ as a tunable hyperparameter is key to maximizing model performance. Although we find the optimal $\beta$ to be sensitive to the architecture, our results suggest that tuning $\beta$ over the range $10^{-2}$ to $10^1$ improves performance over all architectures studied. We find that smaller $\beta$ may lead to better peak performance at the cost of learning stability.