 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemperature check: theory and practice for training models with softmax-cross-entropy losses
Paper and Code
Oct 14, 2020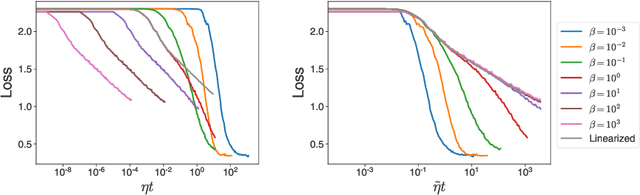
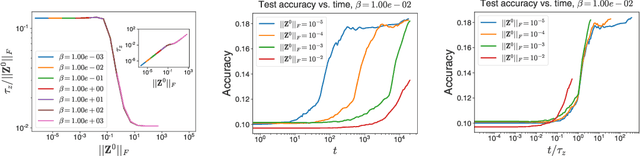

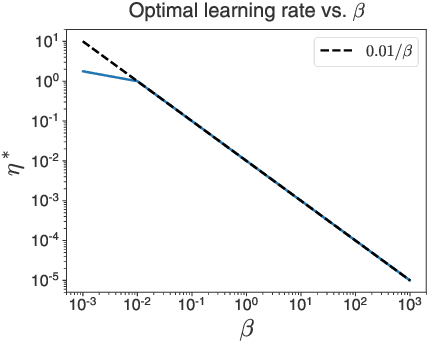
The softmax function combined with a cross-entropy loss is a principled approach to modeling probability distributions that has become ubiquitous in deep learning. The softmax function is defined by a lone hyperparameter, the temperature, that is commonly set to one or regarded as a way to tune model confidence after training; however, less is known about how the temperature impacts training dynamics or generalization performance. In this work we develop a theory of early learning for models trained with softmax-cross-entropy loss and show that the learning dynamics depend crucially on the inverse-temperature $\beta$ as well as the magnitude of the logits at initialization, $||\beta{\bf z}||_{2}$. We follow up these analytic results with a large-scale empirical study of a variety of model architectures trained on CIFAR10, ImageNet, and IMDB sentiment analysis. We find that generalization performance depends strongly on the temperature, but only weakly on the initial logit magnitude. We provide evidence that the dependence of generalization on $\beta$ is not due to changes in model confidence, but is a dynamical phenomenon. It follows that the addition of $\beta$ as a tunable hyperparameter is key to maximizing model performance. Although we find the optimal $\beta$ to be sensitive to the architecture, our results suggest that tuning $\beta$ over the range $10^{-2}$ to $10^1$ improves performance over all architectures studied. We find that smaller $\beta$ may lead to better peak performance at the cost of learning stability.