 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Structure Measuring: Introducing PDD, an Automatic Metric for Positional Discourse Coherence
Paper and Code

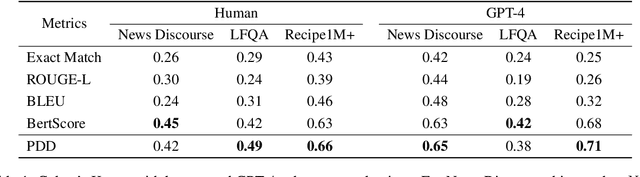
Recent large language models (LLMs) have shown remarkable performance in aligning generated text with user intentions across various tasks. When it comes to long-form text generation, there has been a growing interest in generation from a discourse coherence perspective. However, existing lexical or semantic metrics such as BLEU, ROUGE, BertScore cannot effectively capture the discourse coherence. The development of discourse-specific automatic evaluation methods for assessing the output of LLMs warrants greater focus and exploration. In this paper, we present a novel automatic metric designed to quantify the discourse divergence between two long-form articles. Extensive experiments on three datasets from representative domains demonstrate that our metric aligns more closely with human preferences and GPT-4 coherence evaluation, outperforming existing evaluation methods.