 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEGATO: Large-scale End-to-end Generalizable Approach to Typeset OMR
Jun 23, 2025We propose Legato, a new end-to-end transformer model for optical music recognition (OMR). Legato is the first large-scale pretrained OMR model capable of recognizing full-page or multi-page typeset music scores and the first to generate documents in ABC notation, a concise, human-readable format for symbolic music. Bringing together a pretrained vision encoder with an ABC decoder trained on a dataset of more than 214K images, our model exhibits the strong ability to generalize across various typeset scores. We conduct experiments on a range of datasets and demonstrate that our model achieves state-of-the-art performance. Given the lack of a standardized evaluation for end-to-end OMR, we comprehensively compare our model against the previous state of the art using a diverse set of metrics.
From One to Many: Expanding the Scope of Toxicity Mitigation in Language Models
Mar 06, 2024



To date, toxicity mitigation in language models has almost entirely been focused on single-language settings. As language models embrace multilingual capabilities, it's crucial our safety measures keep pace. Recognizing this research gap, our approach expands the scope of conventional toxicity mitigation to address the complexities presented by multiple languages. In the absence of sufficient annotated datasets across languages, we employ translated data to evaluate and enhance our mitigation techniques. We also compare finetuning mitigation approaches against retrieval-augmented techniques under both static and continual toxicity mitigation scenarios. This allows us to examine the effects of translation quality and the cross-lingual transfer on toxicity mitigation. We also explore how model size and data quantity affect the success of these mitigation efforts. Covering nine languages, our study represents a broad array of linguistic families and levels of resource availability, ranging from high to mid-resource languages. Through comprehensive experiments, we provide insights into the complexities of multilingual toxicity mitigation, offering valuable insights and paving the way for future research in this increasingly important field. Code and data are available at https://github.com/for-ai/goodtriever.
Goodtriever: Adaptive Toxicity Mitigation with Retrieval-augmented Models
Oct 11, 2023
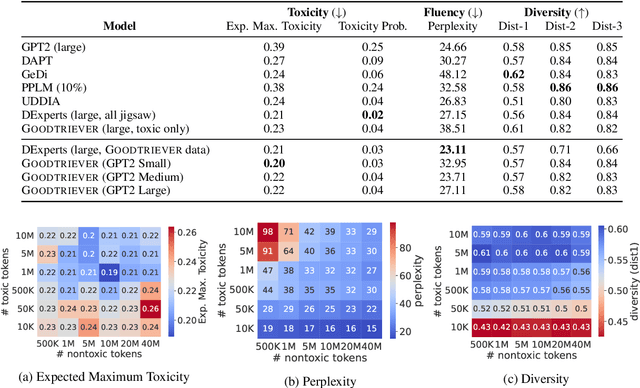


Considerable effort has been dedicated to mitigating toxicity, but existing methods often require drastic modifications to model parameters or the use of computationally intensive auxiliary models. Furthermore, previous approaches have often neglected the crucial factor of language's evolving nature over time. In this work, we present a comprehensive perspective on toxicity mitigation that takes into account its changing nature. We introduce Goodtriever, a flexible methodology that matches the current state-of-the-art toxicity mitigation while achieving 43% relative latency reduction during inference and being more computationally efficient. By incorporating a retrieval-based approach at decoding time, Goodtriever enables toxicity-controlled text generation. Our research advocates for an increased focus on adaptable mitigation techniques, which better reflect the data drift models face when deployed in the wild. Code and data are available at https://github.com/for-ai/goodtriever.
When Less is More: Investigating Data Pruning for Pretraining LLMs at Scale
Sep 08, 2023Large volumes of text data have contributed significantly to the development of large language models (LLMs) in recent years. This data is typically acquired by scraping the internet, leading to pretraining datasets comprised of noisy web text. To date, efforts to prune these datasets down to a higher quality subset have relied on hand-crafted heuristics encoded as rule-based filters. In this work, we take a wider view and explore scalable estimates of data quality that can be used to systematically measure the quality of pretraining data. We perform a rigorous comparison at scale of the simple data quality estimator of perplexity, as well as more sophisticated and computationally intensive estimates of the Error L2-Norm and memorization. These metrics are used to rank and prune pretraining corpora, and we subsequently compare LLMs trained on these pruned datasets. Surprisingly, we find that the simple technique of perplexity outperforms our more computationally expensive scoring methods. We improve over our no-pruning baseline while training on as little as 30% of the original training dataset. Our work sets the foundation for unexplored strategies in automatically curating high quality corpora and suggests the majority of pretraining data can be removed while retaining performance.
On the Challenges of Using Black-Box APIs for Toxicity Evaluation in Research
Apr 24, 2023



Perception of toxicity evolves over time and often differs between geographies and cultural backgrounds. Similarly, black-box commercially available APIs for detecting toxicity, such as the Perspective API, are not static, but frequently retrained to address any unattended weaknesses and biases. We evaluate the implications of these changes on the reproducibility of findings that compare the relative merits of models and methods that aim to curb toxicity. Our findings suggest that research that relied on inherited automatic toxicity scores to compare models and techniques may have resulted in inaccurate findings. Rescoring all models from HELM, a widely respected living benchmark, for toxicity with the recent version of the API led to a different ranking of widely used foundation models. We suggest caution in applying apples-to-apples comparisons between studies and lay recommendations for a more structured approach to evaluating toxicity over time. Code and data are available at https://github.com/for-ai/black-box-api-challenges.