 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Properties of Finetuned Language Representation Models
Paper and Code
Oct 23, 2019
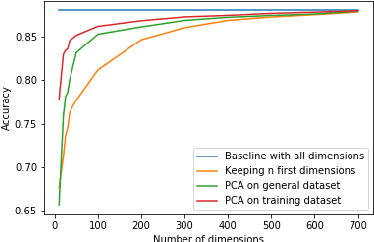
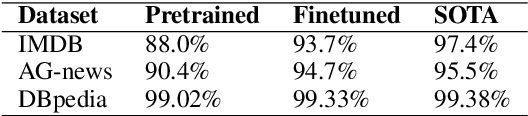
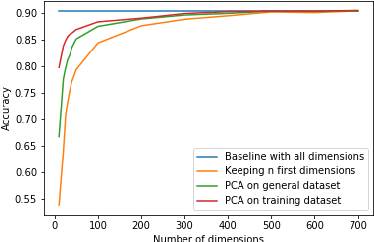
Large, self-supervised transformer-based language representation models have recently received significant amounts of attention, and have produced state-of-the-art results across a variety of tasks simply by scaling up pre-training on larger and larger corpora. Such models usually produce high dimensional vectors, on top of which additional task-specific layers and architectural modifications are added to adapt them to specific downstream tasks. Though there exists ample evidence that such models work well, we aim to understand what happens when they work well. We analyze the redundancy and location of information contained in output vectors for one such language representation model -- BERT. We show empirical evidence that the [CLS] embedding in BERT contains highly redundant information, and can be compressed with minimal loss of accuracy, especially for finetuned models, dovetailing into open threads in the field about the role of over-parameterization in learning. We also shed light on the existence of specific output dimensions which alone give very competitive results when compared to using all dimensions of output vectors.