 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Deep Learning in Open Collaborations
Jun 18, 2021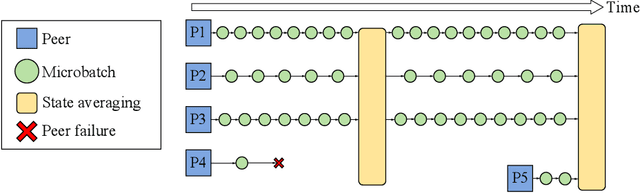
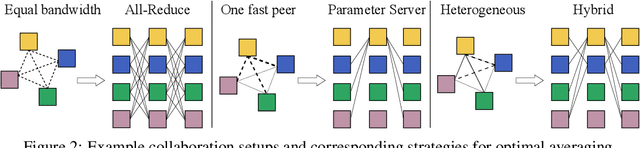
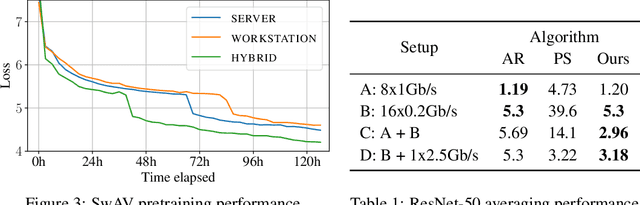

Modern deep learning applications require increasingly more compute to train state-of-the-art models. To address this demand, large corporations and institutions use dedicated High-Performance Computing clusters, whose construction and maintenance are both environmentally costly and well beyond the budget of most organizations. As a result, some research directions become the exclusive domain of a few large industrial and even fewer academic actors. To alleviate this disparity, smaller groups may pool their computational resources and run collaborative experiments that benefit all participants. This paradigm, known as grid- or volunteer computing, has seen successful applications in numerous scientific areas. However, using this approach for machine learning is difficult due to high latency, asymmetric bandwidth, and several challenges unique to volunteer computing. In this work, we carefully analyze these constraints and propose a novel algorithmic framework designed specifically for collaborative training. We demonstrate the effectiveness of our approach for SwAV and ALBERT pretraining in realistic conditions and achieve performance comparable to traditional setups at a fraction of the cost. Finally, we provide a detailed report of successful collaborative language model pretraining with 40 participants.
Advances of Transformer-Based Models for News Headline Generation
Jul 09, 2020
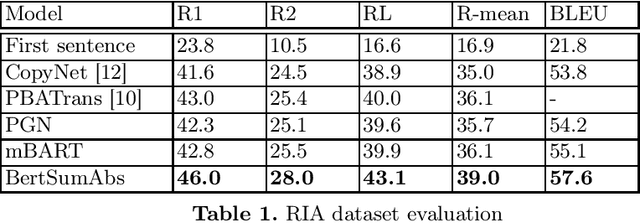

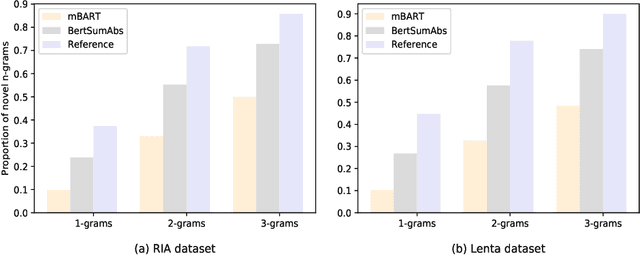
Pretrained language models based on Transformer architecture are the reason for recent breakthroughs in many areas of NLP, including sentiment analysis, question answering, named entity recognition. Headline generation is a special kind of text summarization task. Models need to have strong natural language understanding that goes beyond the meaning of individual words and sentences and an ability to distinguish essential information to succeed in it. In this paper, we fine-tune two pretrained Transformer-based models (mBART and BertSumAbs) for that task and achieve new state-of-the-art results on the RIA and Lenta datasets of Russian news. BertSumAbs increases ROUGE on average by 4.6 and 5.9 points respectively over previous best score achieved by Pointer-Generator network.