 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances of Transformer-Based Models for News Headline Generation
Paper and Code
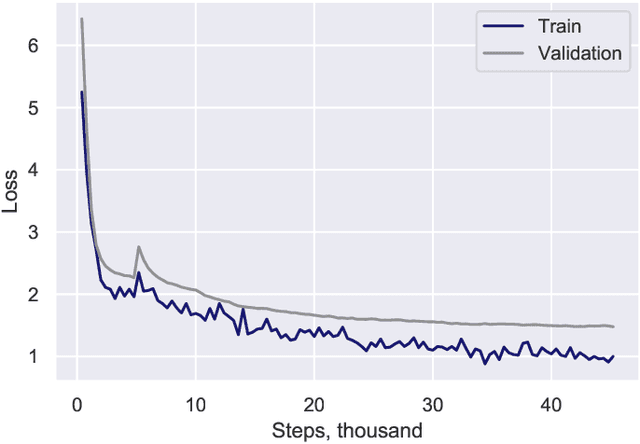
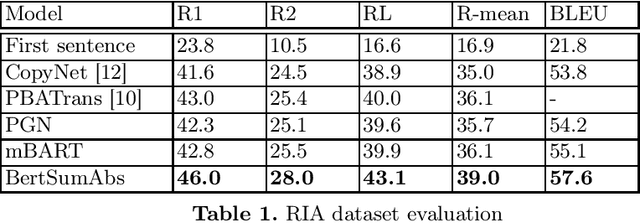

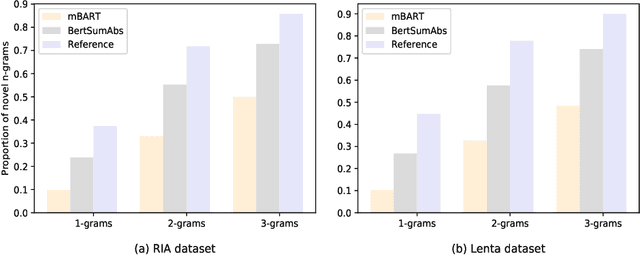
Pretrained language models based on Transformer architecture are the reason for recent breakthroughs in many areas of NLP, including sentiment analysis, question answering, named entity recognition. Headline generation is a special kind of text summarization task. Models need to have strong natural language understanding that goes beyond the meaning of individual words and sentences and an ability to distinguish essential information to succeed in it. In this paper, we fine-tune two pretrained Transformer-based models (mBART and BertSumAbs) for that task and achieve new state-of-the-art results on the RIA and Lenta datasets of Russian news. BertSumAbs increases ROUGE on average by 4.6 and 5.9 points respectively over previous best score achieved by Pointer-Generator network.