 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Distributed Training at Scale
Paper and Code
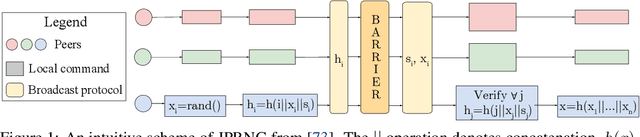
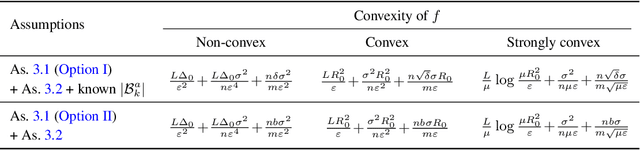
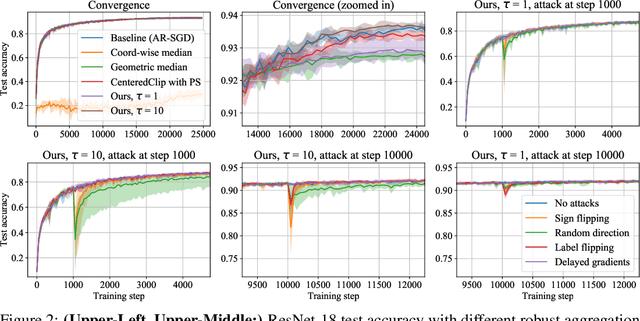
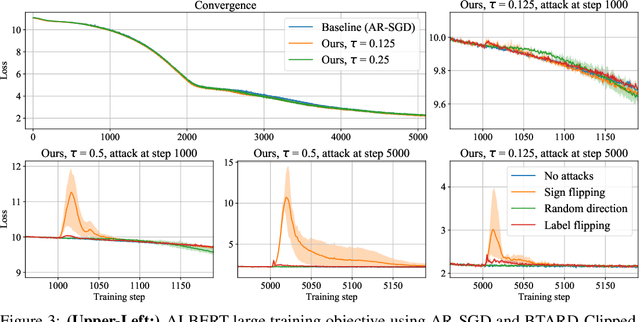
Some of the hardest problems in deep learning can be solved with the combined effort of many independent parties, as is the case for volunteer computing and federated learning. These setups rely on high numbers of peers to provide computational resources or train on decentralized datasets. Unfortunately, participants in such systems are not always reliable. Any single participant can jeopardize the entire training run by sending incorrect updates, whether deliberately or by mistake. Training in presence of such peers requires specialized distributed training algorithms with Byzantine tolerance. These algorithms often sacrifice efficiency by introducing redundant communication or passing all updates through a trusted server. As a result, it can be infeasible to apply such algorithms to large-scale distributed deep learning, where models can have billions of parameters. In this work, we propose a novel protocol for secure (Byzantine-tolerant) decentralized training that emphasizes communication efficiency. We rigorously analyze this protocol: in particular, we provide theoretical bounds for its resistance against Byzantine and Sybil attacks and show that it has a marginal communication overhead. To demonstrate its practical effectiveness, we conduct large-scale experiments on image classification and language modeling in presence of Byzantine attackers.