 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Free Neural Architecture Search via Recursive Label Calibration
Paper and Code
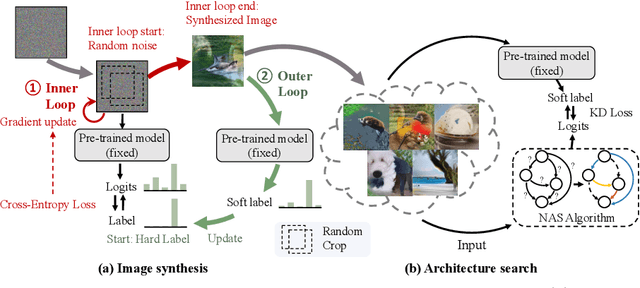
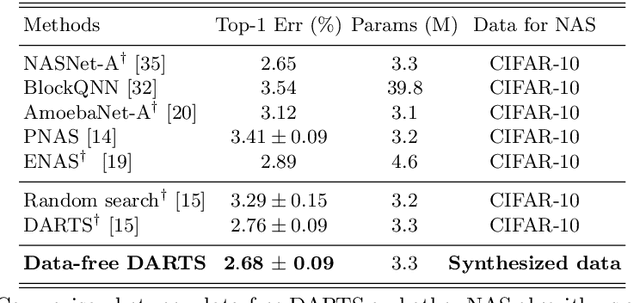
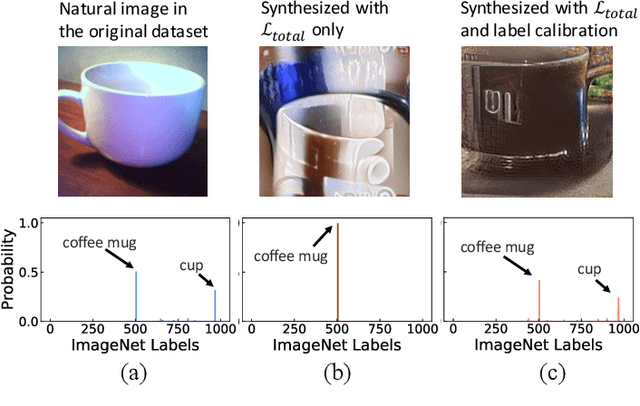
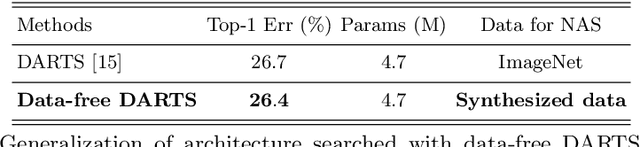
This paper aims to explore the feasibility of neural architecture search (NAS) given only a pre-trained model without using any original training data. This is an important circumstance for privacy protection, bias avoidance, etc., in real-world scenarios. To achieve this, we start by synthesizing usable data through recovering the knowledge from a pre-trained deep neural network. Then we use the synthesized data and their predicted soft-labels to guide neural architecture search. We identify that the NAS task requires the synthesized data (we target at image domain here) with enough semantics, diversity, and a minimal domain gap from the natural images. For semantics, we propose recursive label calibration to produce more informative outputs. For diversity, we propose a regional update strategy to generate more diverse and semantically-enriched synthetic data. For minimal domain gap, we use input and feature-level regularization to mimic the original data distribution in latent space. We instantiate our proposed framework with three popular NAS algorithms: DARTS, ProxylessNAS and SPOS. Surprisingly, our results demonstrate that the architectures discovered by searching with our synthetic data achieve accuracy that is comparable to, or even higher than, architectures discovered by searching from the original ones, for the first time, deriving the conclusion that NAS can be done effectively with no need of access to the original or called natural data if the synthesis method is well designed. Our code will be publicly available.