 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting over/under-translation errors for determining adequacy in human translations
Apr 01, 2021
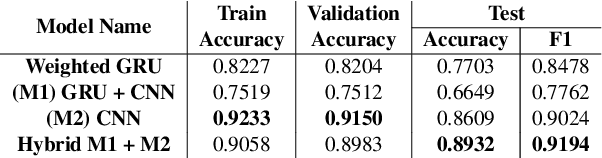

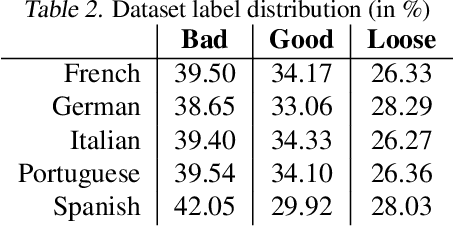
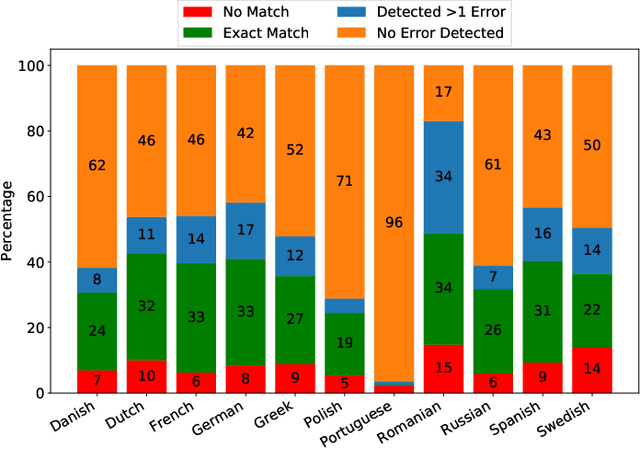
We present a novel approach to detecting over and under translations (OT/UT) as part of adequacy error checks in translation evaluation. We do not restrict ourselves to machine translation (MT) outputs and specifically target applications with human generated translation pipeline. The goal of our system is to identify OT/UT errors from human translated video subtitles with high error recall. We achieve this without reference translations by learning a model on synthesized training data. We compare various classification networks that we trained on embeddings from pre-trained language model with our best hybrid network of GRU + CNN achieving 89.3% accuracy on high-quality human-annotated evaluation data in 8 languages.
DeepSubQE: Quality estimation for subtitle translations
Apr 22, 2020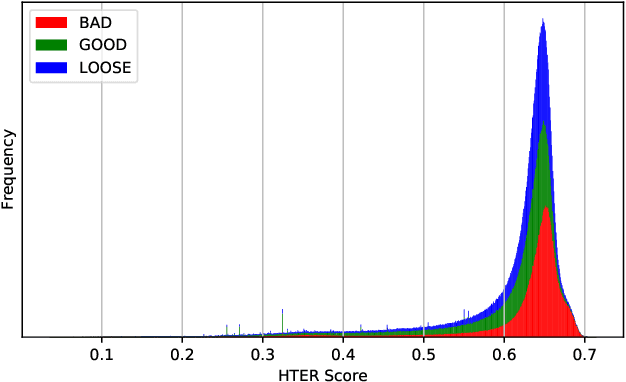
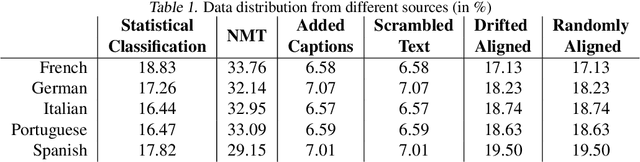
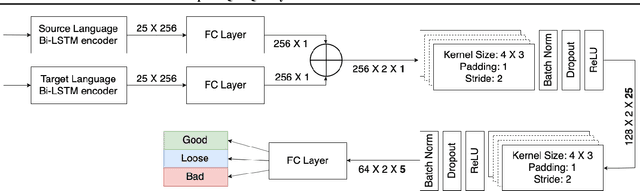
Quality estimation (QE) for tasks involving language data is hard owing to numerous aspects of natural language like variations in paraphrasing, style, grammar, etc. There can be multiple answers with varying levels of acceptability depending on the application at hand. In this work, we look at estimating quality of translations for video subtitles. We show how existing QE methods are inadequate and propose our method DeepSubQE as a system to estimate quality of translation given subtitles data for a pair of languages. We rely on various data augmentation strategies for automated labelling and synthesis for training. We create a hybrid network which learns semantic and syntactic features of bilingual data and compare it with only-LSTM and only-CNN networks. Our proposed network outperforms them by significant margin.
A context sensitive real-time Spell Checker with language adaptability
Oct 23, 2019


We present a novel language adaptable spell checking system which detects spelling errors and suggests context sensitive corrections in real-time. We show that our system can be extended to new languages with minimal language-specific processing. Available literature majorly discusses spell checkers for English but there are no publicly available systems which can be extended to work for other languages out of the box. Most of the systems do not work in real-time. We explain the process of generating a language's word dictionary and n-gram probability dictionaries using Wikipedia-articles data and manually curated video subtitles. We present the results of generating a list of suggestions for a misspelled word. We also propose three approaches to create noisy channel datasets of real-world typographic errors. We compare our system with industry-accepted spell checker tools for 11 languages. Finally, we show the performance of our system on synthetic datasets for 24 languages.
Problems with automating translation of movie/TV show subtitles
Sep 04, 2019

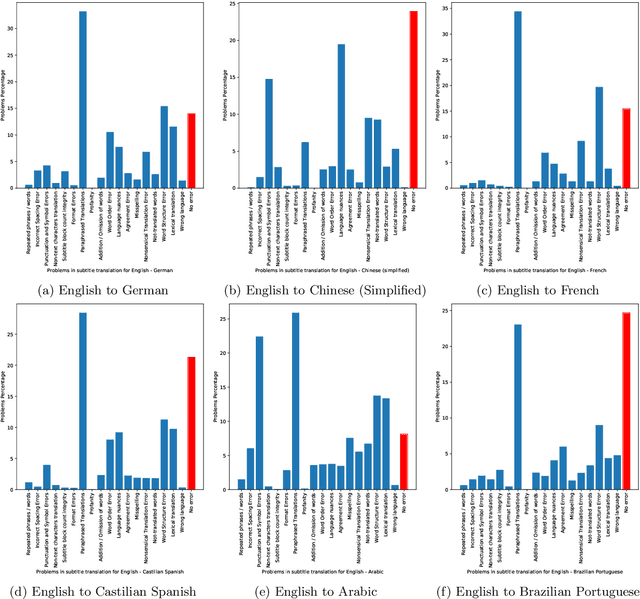

We present 27 problems encountered in automating the translation of movie/TV show subtitles. We categorize each problem in one of the three categories viz. problems directly related to textual translation, problems related to subtitle creation guidelines, and problems due to adaptability of machine translation (MT) engines. We also present the findings of a translation quality evaluation experiment where we share the frequency of 16 key problems. We show that the systems working at the frontiers of Natural Language Processing do not perform well for subtitles and require some post-processing solutions for redressal of these problems