Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting over/under-translation errors for determining adequacy in human translations
Apr 01, 2021
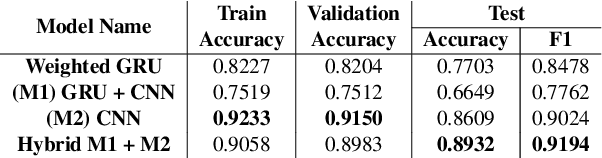

We present a novel approach to detecting over and under translations (OT/UT) as part of adequacy error checks in translation evaluation. We do not restrict ourselves to machine translation (MT) outputs and specifically target applications with human generated translation pipeline. The goal of our system is to identify OT/UT errors from human translated video subtitles with high error recall. We achieve this without reference translations by learning a model on synthesized training data. We compare various classification networks that we trained on embeddings from pre-trained language model with our best hybrid network of GRU + CNN achieving 89.3% accuracy on high-quality human-annotated evaluation data in 8 languages.
* 6 pages, 5 tables
Via