 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA nonlinear real time capable motion cueing algorithm based on deep reinforcement learning
Mar 13, 2025
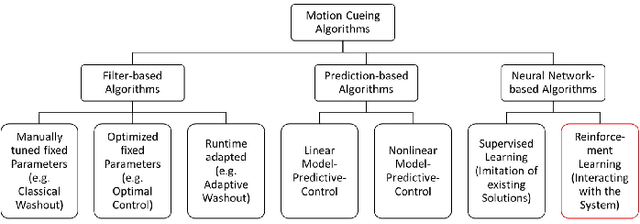
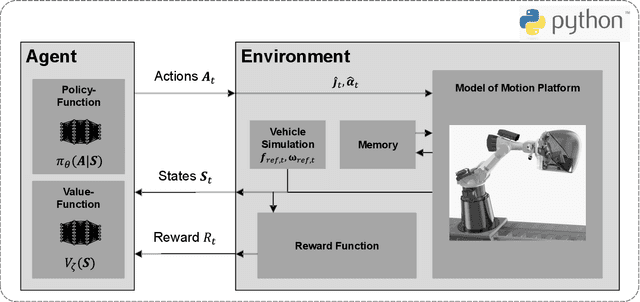
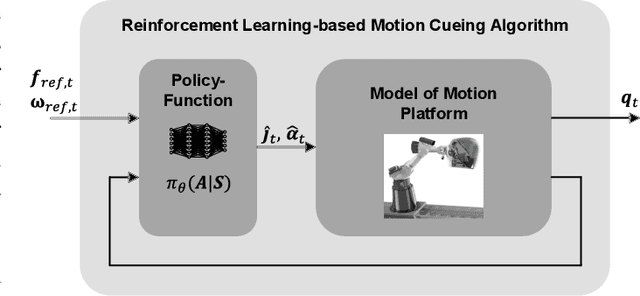
In motion simulation, motion cueing algorithms are used for the trajectory planning of the motion simulator platform, where workspace limitations prevent direct reproduction of reference trajectories. Strategies such as motion washout, which return the platform to its center, are crucial in these settings. For serial robotic MSPs with highly nonlinear workspaces, it is essential to maximize the efficient utilization of the MSPs kinematic and dynamic capabilities. Traditional approaches, including classical washout filtering and linear model predictive control, fail to consider platform-specific, nonlinear properties, while nonlinear model predictive control, though comprehensive, imposes high computational demands that hinder real-time, pilot-in-the-loop application without further simplification. To overcome these limitations, we introduce a novel approach using deep reinforcement learning for motion cueing, demonstrated here for the first time in a 6-degree-of-freedom setting with full consideration of the MSPs kinematic nonlinearities. Previous work by the authors successfully demonstrated the application of DRL to a simplified 2-DOF setup, which did not consider kinematic or dynamic constraints. This approach has been extended to all 6 DOF by incorporating a complete kinematic model of the MSP into the algorithm, a crucial step for enabling its application on a real motion simulator. The training of the DRL-MCA is based on Proximal Policy Optimization in an actor-critic implementation combined with an automated hyperparameter optimization. After detailing the necessary training framework and the algorithm itself, we provide a comprehensive validation, demonstrating that the DRL MCA achieves competitive performance against established algorithms. Moreover, it generates feasible trajectories by respecting all system constraints and meets all real-time requirements with low...
A novel approach of a deep reinforcement learning based motion cueing algorithm for vehicle driving simulation
Apr 15, 2023
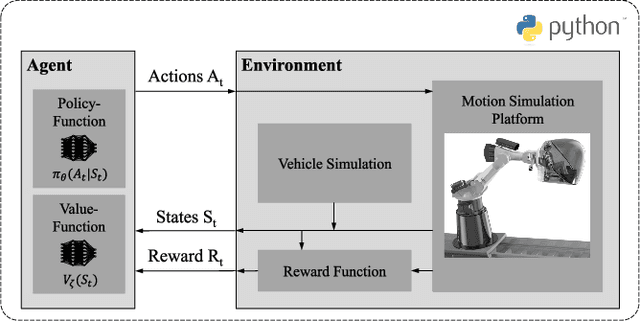
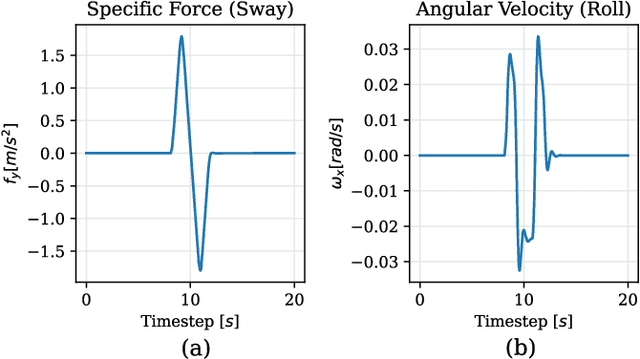
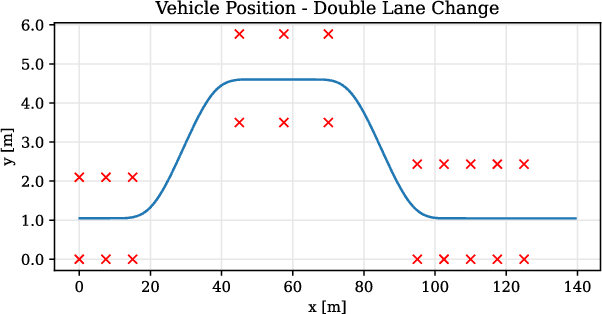
In the field of motion simulation, the level of immersion strongly depends on the motion cueing algorithm (MCA), as it transfers the reference motion of the simulated vehicle to a motion of the motion simulation platform (MSP). The challenge for the MCA is to reproduce the motion perception of a real vehicle driver as accurately as possible without exceeding the limits of the workspace of the MSP in order to provide a realistic virtual driving experience. In case of a large discrepancy between the perceived motion signals and the optical cues, motion sickness may occur with the typical symptoms of nausea, dizziness, headache and fatigue. Existing approaches either produce non-optimal results, e.g., due to filtering, linearization, or simplifications, or the required computational time exceeds the real-time requirements of a closed-loop application. In this work a new solution is presented, where not a human designer specifies the principles of the MCA but an artificial intelligence (AI) learns the optimal motion by trial and error in an interaction with the MSP. To achieve this, deep reinforcement learning (RL) is applied, where an agent interacts with an environment formulated as a Markov decision process~(MDP). This allows the agent to directly control a simulated MSP to obtain feedback on its performance in terms of platform workspace usage and the motion acting on the simulator user. The RL algorithm used is proximal policy optimization (PPO), where the value function and the policy corresponding to the control strategy are learned and both are mapped in artificial neural networks (ANN). This approach is implemented in Python and the functionality is demonstrated by the practical example of pre-recorded lateral maneuvers. The subsequent validation on a standardized double lane change shows that the RL algorithm is able to learn the control strategy and improve the quality of...