 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Learning Based on Support Vector Machines and Twin Support Vector Machines: A Comprehensive Survey
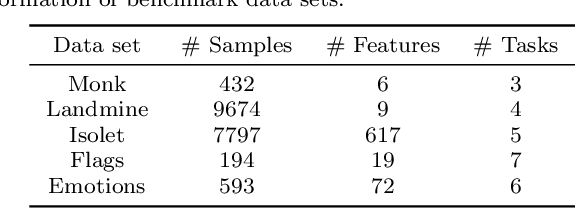
Oct 30, 2025Multi-task learning (MTL) enables simultaneous training across related tasks, leveraging shared information to improve generalization, efficiency, and robustness, especially in data-scarce or high-dimensional scenarios. While deep learning dominates recent MTL research, Support Vector Machines (SVMs) and Twin SVMs (TWSVMs) remain relevant due to their interpretability, theoretical rigor, and effectiveness with small datasets. This chapter surveys MTL approaches based on SVM and TWSVM, highlighting shared representations, task regularization, and structural coupling strategies. Special attention is given to emerging TWSVM extensions for multi-task settings, which show promise but remain underexplored. We compare these models in terms of theoretical properties, optimization strategies, and empirical performance, and discuss applications in fields such as computer vision, natural language processing, and bioinformatics. Finally, we identify research gaps and outline future directions for building scalable, interpretable, and reliable margin-based MTL frameworks. This work provides a comprehensive resource for researchers and practitioners interested in SVM- and TWSVM-based multi-task learning.
No-Reference Image Contrast Assessment with Customized EfficientNet-B0
Sep 26, 2025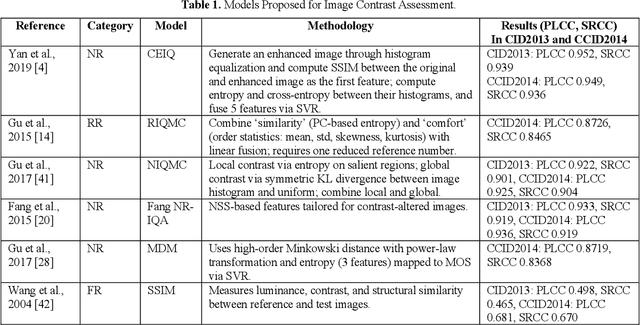
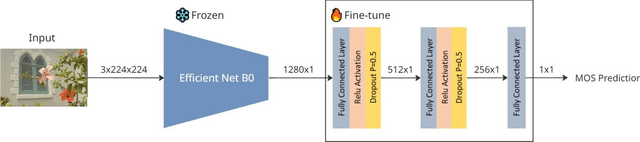
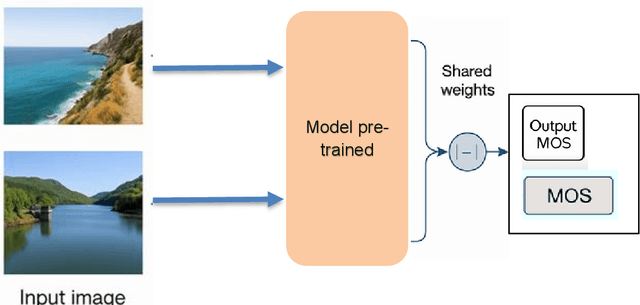

Image contrast was a fundamental factor in visual perception and played a vital role in overall image quality. However, most no reference image quality assessment NR IQA models struggled to accurately evaluate contrast distortions under diverse real world conditions. In this study, we proposed a deep learning based framework for blind contrast quality assessment by customizing and fine-tuning three pre trained architectures, EfficientNet B0, ResNet18, and MobileNetV2, for perceptual Mean Opinion Score, along with an additional model built on a Siamese network, which indicated a limited ability to capture perceptual contrast distortions. Each model is modified with a contrast-aware regression head and trained end to end using targeted data augmentations on two benchmark datasets, CID2013 and CCID2014, containing synthetic and authentic contrast distortions. Performance is evaluated using Pearson Linear Correlation Coefficient and Spearman Rank Order Correlation Coefficient, which assess the alignment between predicted and human rated scores. Among these three models, our customized EfficientNet B0 model achieved state-of-the-art performance with PLCC = 0.9286 and SRCC = 0.9178 on CCID2014 and PLCC = 0.9581 and SRCC = 0.9369 on CID2013, surpassing traditional methods and outperforming other deep baselines. These results highlighted the models robustness and effectiveness in capturing perceptual contrast distortion. Overall, the proposed method demonstrated that contrast aware adaptation of lightweight pre trained networks can yield a high performing, scalable solution for no reference contrast quality assessment suitable for real time and resource constrained applications.
Kernel-Free Universum Quadratic Surface Twin Support Vector Machines for Imbalanced Data
Dec 02, 2024
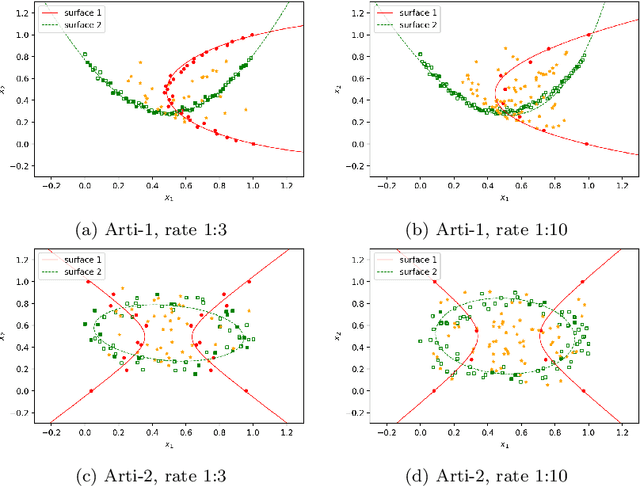
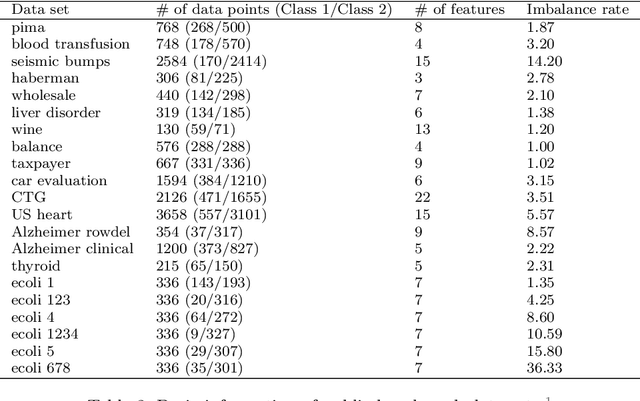
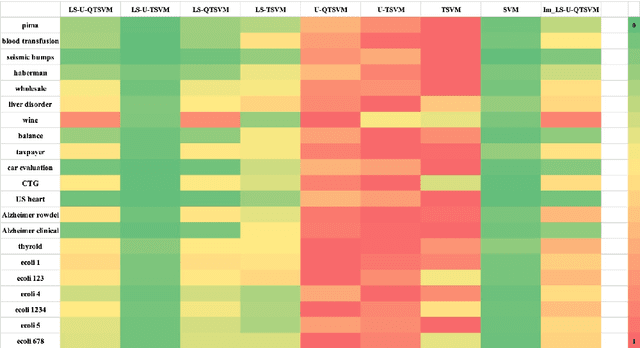
Binary classification tasks with imbalanced classes pose significant challenges in machine learning. Traditional classifiers often struggle to accurately capture the characteristics of the minority class, resulting in biased models with subpar predictive performance. In this paper, we introduce a novel approach to tackle this issue by leveraging Universum points to support the minority class within quadratic twin support vector machine models. Unlike traditional classifiers, our models utilize quadratic surfaces instead of hyperplanes for binary classification, providing greater flexibility in modeling complex decision boundaries. By incorporating Universum points, our approach enhances classification accuracy and generalization performance on imbalanced datasets. We generated four artificial datasets to demonstrate the flexibility of the proposed methods. Additionally, we validated the effectiveness of our approach through empirical evaluations on benchmark datasets, showing superior performance compared to conventional classifiers and existing methods for imbalanced classification.
A Brief Review of Explainable Artificial Intelligence in Healthcare
Apr 04, 2023



XAI refers to the techniques and methods for building AI applications which assist end users to interpret output and predictions of AI models. Black box AI applications in high-stakes decision-making situations, such as medical domain have increased the demand for transparency and explainability since wrong predictions may have severe consequences. Model explainability and interpretability are vital successful deployment of AI models in healthcare practices. AI applications' underlying reasoning needs to be transparent to clinicians in order to gain their trust. This paper presents a systematic review of XAI aspects and challenges in the healthcare domain. The primary goals of this study are to review various XAI methods, their challenges, and related machine learning models in healthcare. The methods are discussed under six categories: Features-oriented methods, global methods, concept models, surrogate models, local pixel-based methods, and human-centric methods. Most importantly, the paper explores XAI role in healthcare problems to clarify its necessity in safety-critical applications. The paper intends to establish a comprehensive understanding of XAI-related applications in the healthcare field by reviewing the related experimental results. To facilitate future research for filling research gaps, the importance of XAI models from different viewpoints and their limitations are investigated.
Multi-task twin support vector machine with Universum data
Jun 22, 2022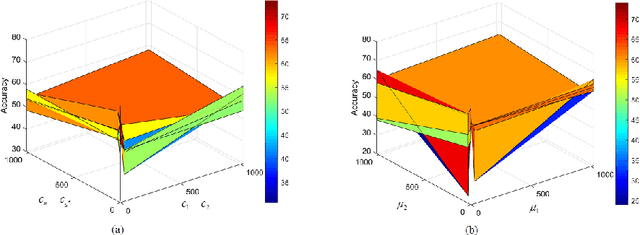
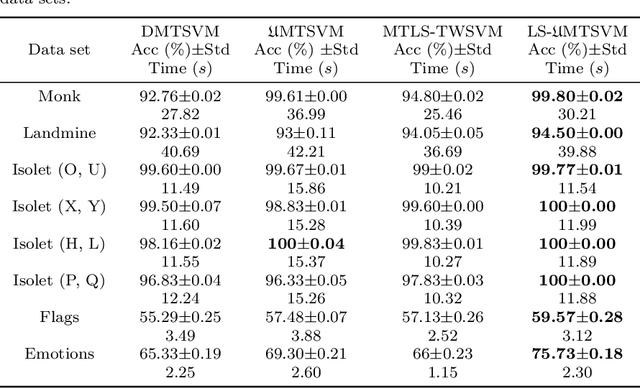

Multi-task learning (MTL) has emerged as a promising topic of machine learning in recent years, aiming to enhance the performance of numerous related learning tasks by exploiting beneficial information. During the training phase, most of the existing multi-task learning models concentrate entirely on the target task data and ignore the non-target task data contained in the target tasks. To address this issue, Universum data, that do not correspond to any class of a classification problem, may be used as prior knowledge in the training model. This study looks at the challenge of multi-task learning using Universum data to employ non-target task data, which leads to better performance. It proposes a multi-task twin support vector machine with Universum data (UMTSVM) and provides two approaches to its solution. The first approach takes into account the dual formulation of UMTSVM and tries to solve a quadratic programming problem. The second approach formulates a least-squares version of UMTSVM and refers to it as LS-UMTSVM to further increase the generalization performance. The solution of the two primal problems in LS-UMTSVM is simplified to solving just two systems of linear equations, resulting in an incredibly simple and quick approach. Numerical experiments on several popular multi-task data sets and medical data sets demonstrate the efficiency of the proposed methods.
Time Series Forecasting of New Cases and New Deaths Rate for COVID-19 using Deep Learning Methods
Apr 28, 2021
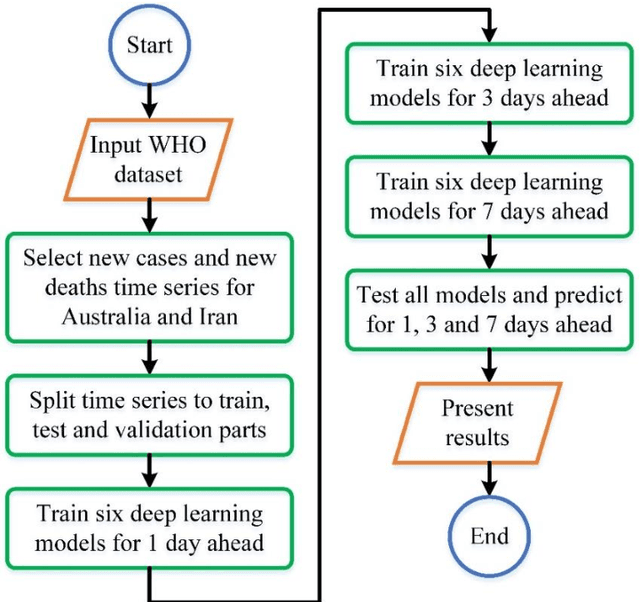

Covid-19 has been started in the year 2019 and imposed restrictions in many countries and costs organisations and governments. Predicting the number of new cases and deaths during this period can be a useful step in predicting the costs and facilities required in the future. The purpose of this study is to predict new cases and death rate for seven days ahead. Deep learning methods and statistical analysis model these predictions for 100 days. Six different deep learning methods are examined for the data adopted from the WHO website. Three methods are known as LSTM, Convolutional LSTM, and GRU. The bi-directional mode is then considered for each method to forecast the rate of new cases and new deaths for Australia and Iran countries. This study is novel as it attempts to implement the mentioned three deep learning methods, along with their Bi-directional models, to predict COVID-19 new cases and new death rate time series. All methods are compared, and results are presented. The results are examined in the form of graphs and statistical analyses. The results show that the Bi-directional models have lower error than other models. Several error evaluation metrics are presented to compare all models, and finally, the superiority of Bi-directional methods are determined. The experimental results and statistical test show on datasets to compare the proposed method with other baseline methods. This research could be useful for organisations working against COVID-19 and determining their long-term plans.
CNN AE: Convolution Neural Network combined with Autoencoder approach to detect survival chance of COVID 19 patients
Apr 18, 2021
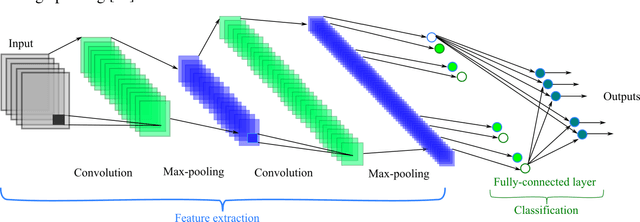
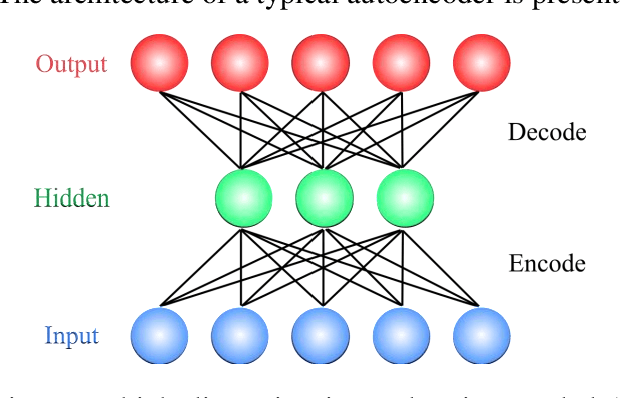
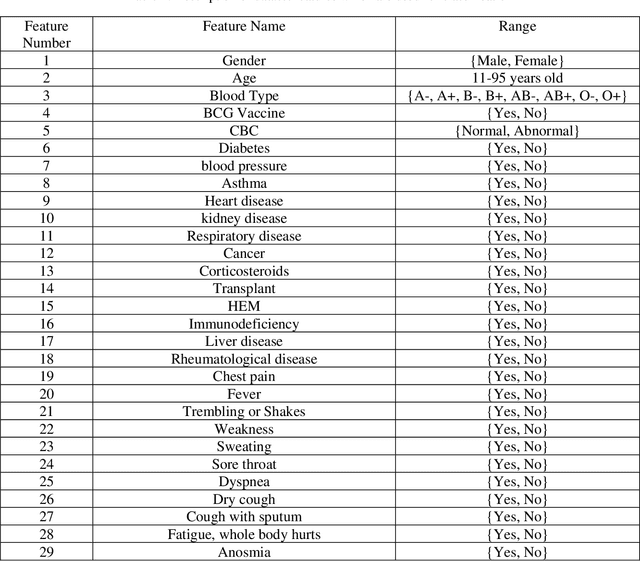
In this paper, we propose a novel method named CNN-AE to predict survival chance of COVID-19 patients using a CNN trained on clinical information. To further increase the prediction accuracy, we use the CNN in combination with an autoencoder. Our method is one of the first that aims to predict survival chance of already infected patients. We rely on clinical data to carry out the prediction. The motivation is that the required resources to prepare CT images are expensive and limited compared to the resources required to collect clinical data such as blood pressure, liver disease, etc. We evaluate our method on a publicly available clinical dataset of deceased and recovered patients which we have collected. Careful analysis of the dataset properties is also presented which consists of important features extraction and correlation computation between features. Since most of COVID-19 patients are usually recovered, the number of deceased samples of our dataset is low leading to data imbalance. To remedy this issue, a data augmentation procedure based on autoencoders is proposed. To demonstrate the generality of our augmentation method, we train random forest and Na\"ive Bayes on our dataset with and without augmentation and compare their performance. We also evaluate our method on another dataset for further generality verification. Experimental results reveal the superiority of CNN-AE method compared to the standard CNN as well as other methods such as random forest and Na\"ive Bayes. COVID-19 detection average accuracy of CNN-AE is 96.05% which is higher than CNN average accuracy of 92.49%. To show that clinical data can be used as a reliable dataset for COVID-19 survival chance prediction, CNN-AE is compared with a standard CNN which is trained on CT images.
Sparse Universum Quadratic Surface Support Vector Machine Models for Binary Classification
Apr 03, 2021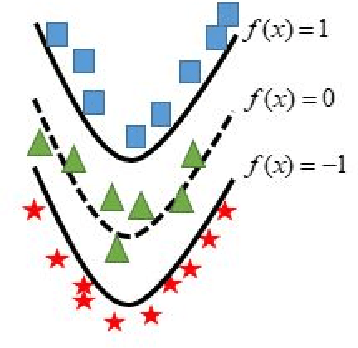

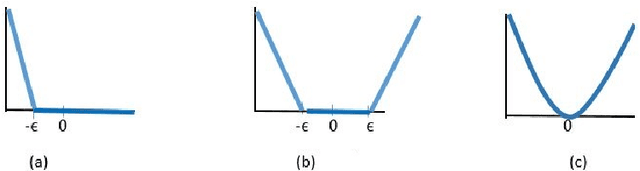
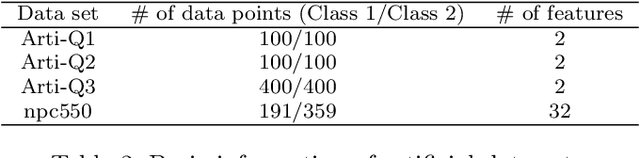
In binary classification, kernel-free linear or quadratic support vector machines are proposed to avoid dealing with difficulties such as finding appropriate kernel functions or tuning their hyper-parameters. Furthermore, Universum data points, which do not belong to any class, can be exploited to embed prior knowledge into the corresponding models so that the generalization performance is improved. In this paper, we design novel kernel-free Universum quadratic surface support vector machine models. Further, we propose the L1 norm regularized version that is beneficial for detecting potential sparsity patterns in the Hessian of the quadratic surface and reducing to the standard linear models if the data points are (almost) linearly separable. The proposed models are convex such that standard numerical solvers can be utilized for solving them. Nonetheless, we formulate a least squares version of the L1 norm regularized model and next, design an effective tailored algorithm that only requires solving one linear system. Several theoretical properties of these models are then reported/proved as well. We finally conduct numerical experiments on both artificial and public benchmark data sets to demonstrate the feasibility and effectiveness of the proposed models.