 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the features used for summary evaluation by Human and GPT
Dec 22, 2025Summary assessment involves evaluating how well a generated summary reflects the key ideas and meaning of the source text, requiring a deep understanding of the content. Large Language Models (LLMs) have been used to automate this process, acting as judges to evaluate summaries with respect to the original text. While previous research investigated the alignment between LLMs and Human responses, it is not yet well understood what properties or features are exploited by them when asked to evaluate based on a particular quality dimension, and there has not been much attention towards mapping between evaluation scores and metrics. In this paper, we address this issue and discover features aligned with Human and Generative Pre-trained Transformers (GPTs) responses by studying statistical and machine learning metrics. Furthermore, we show that instructing GPTs to employ metrics used by Human can improve their judgment and conforming them better with human responses.
A Review of Global Sensitivity Analysis Methods and a comparative case study on Digit Classification
Jun 23, 2024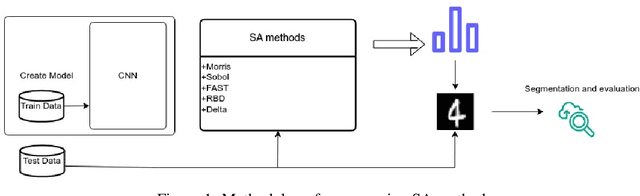
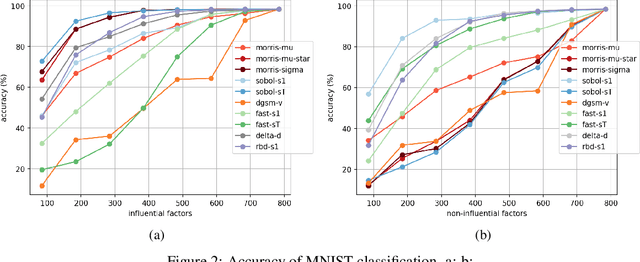
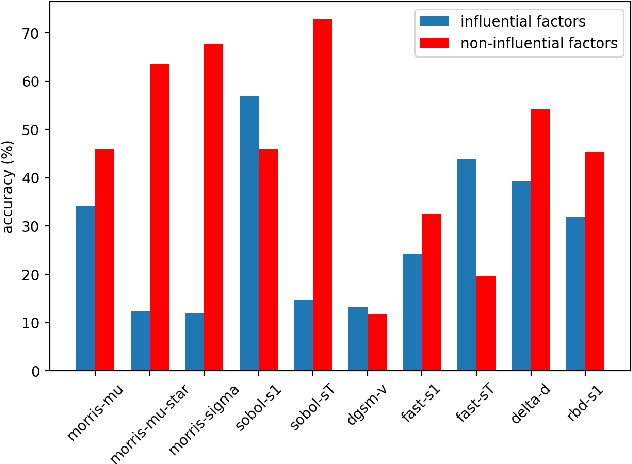
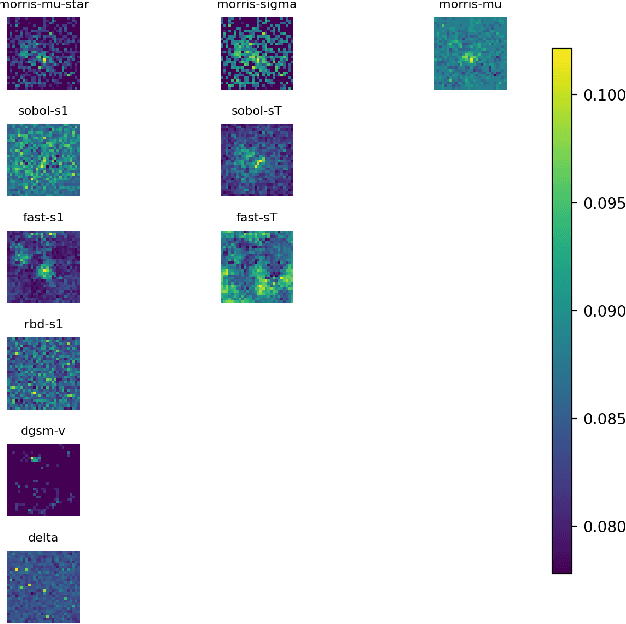
Global sensitivity analysis (GSA) aims to detect influential input factors that lead a model to arrive at a certain decision and is a significant approach for mitigating the computational burden of processing high dimensional data. In this paper, we provide a comprehensive review and a comparison on global sensitivity analysis methods. Additionally, we propose a methodology for evaluating the efficacy of these methods by conducting a case study on MNIST digit dataset. Our study goes through the underlying mechanism of widely used GSA methods and highlights their efficacy through a comprehensive methodology.
Causal Generative Explainers using Counterfactual Inference: A Case Study on the Morpho-MNIST Dataset
Jan 21, 2024
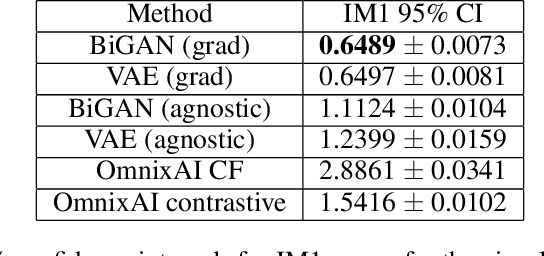

In this paper, we propose leveraging causal generative learning as an interpretable tool for explaining image classifiers. Specifically, we present a generative counterfactual inference approach to study the influence of visual features (i.e., pixels) as well as causal factors through generative learning. To this end, we first uncover the most influential pixels on a classifier's decision by varying the value of a causal attribute via counterfactual inference and computing both Shapely and contrastive explanations for counterfactual images with these different attribute values. We then establish a Monte-Carlo mechanism using the generator of a causal generative model in order to adapt Shapley explainers to produce feature importances for the human-interpretable attributes of a causal dataset in the case where a classifier has been trained exclusively on the images of the dataset. Finally, we present optimization methods for creating counterfactual explanations of classifiers by means of counterfactual inference, proposing straightforward approaches for both differentiable and arbitrary classifiers. We exploit the Morpho-MNIST causal dataset as a case study for exploring our proposed methods for generating counterfacutl explantions. We employ visual explanation methods from OmnixAI open source toolkit to compare them with our proposed methods. By employing quantitative metrics to measure the interpretability of counterfactual explanations, we find that our proposed methods of counterfactual explanation offer more interpretable explanations compared to those generated from OmnixAI. This finding suggests that our methods are well-suited for generating highly interpretable counterfactual explanations on causal datasets.
A Brief Review of Explainable Artificial Intelligence in Healthcare
Apr 04, 2023



XAI refers to the techniques and methods for building AI applications which assist end users to interpret output and predictions of AI models. Black box AI applications in high-stakes decision-making situations, such as medical domain have increased the demand for transparency and explainability since wrong predictions may have severe consequences. Model explainability and interpretability are vital successful deployment of AI models in healthcare practices. AI applications' underlying reasoning needs to be transparent to clinicians in order to gain their trust. This paper presents a systematic review of XAI aspects and challenges in the healthcare domain. The primary goals of this study are to review various XAI methods, their challenges, and related machine learning models in healthcare. The methods are discussed under six categories: Features-oriented methods, global methods, concept models, surrogate models, local pixel-based methods, and human-centric methods. Most importantly, the paper explores XAI role in healthcare problems to clarify its necessity in safety-critical applications. The paper intends to establish a comprehensive understanding of XAI-related applications in the healthcare field by reviewing the related experimental results. To facilitate future research for filling research gaps, the importance of XAI models from different viewpoints and their limitations are investigated.
Evolutionary Augmentation Policy Optimization for Self-supervised Learning
Mar 02, 2023



Self-supervised learning (SSL) is a Machine Learning algorithm for pretraining Deep Neural Networks (DNNs) without requiring manually labeled data. The central idea of this learning technique is based on an auxiliary stage aka pretext task in which labeled data are created automatically through data augmentation and exploited for pretraining the DNN. However, the effect of each pretext task is not well studied or compared in the literature. In this paper, we study the contribution of augmentation operators on the performance of self supervised learning algorithms in a constrained settings. We propose an evolutionary search method for optimization of data augmentation pipeline in pretext tasks and measure the impact of augmentation operators in several SOTA SSL algorithms. By encoding different combination of augmentation operators in chromosomes we seek the optimal augmentation policies through an evolutionary optimization mechanism. We further introduce methods for analyzing and explaining the performance of optimized SSL algorithms. Our results indicate that our proposed method can find solutions that outperform the accuracy of classification of SSL algorithms which confirms the influence of augmentation policy choice on the overall performance of SSL algorithms. We also compare optimal SSL solutions found by our evolutionary search mechanism and show the effect of batch size in the pretext task on two visual datasets.
The Effect of Top-Down Attention in Occluded Object Recognition
Jul 17, 2020
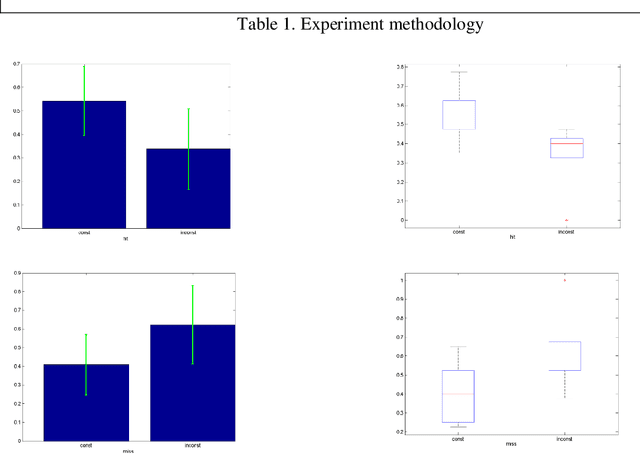
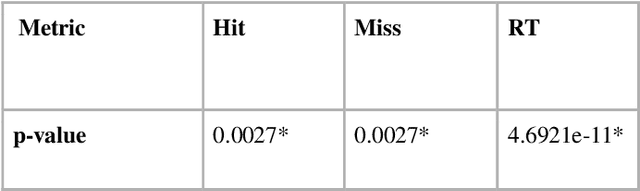

This study is concerned with the top-down visual processing benefit in the task of occluded object recognition. To this end, a psychophysical experiment is designed and carried out which aimed at investigating the effect of consistency of contextual information on the recognition of objects which are partially occluded. The results demonstrate the facilitative impact of consistent contextual clues on the task of object recognition in presence of occlusion.
Deep Learning Framework for Detecting Ground Deformation in the Built Environment using Satellite InSAR data
May 13, 2020



The large volumes of Sentinel-1 data produced over Europe are being used to develop pan-national ground motion services. However, simple analysis techniques like thresholding cannot detect and classify complex deformation signals reliably making providing usable information to a broad range of non-expert stakeholders a challenge. Here we explore the applicability of deep learning approaches by adapting a pre-trained convolutional neural network (CNN) to detect deformation in a national-scale velocity field. For our proof-of-concept, we focus on the UK where previously identified deformation is associated with coal-mining, ground water withdrawal, landslides and tunnelling. The sparsity of measurement points and the presence of spike noise make this a challenging application for deep learning networks, which involve calculations of the spatial convolution between images. Moreover, insufficient ground truth data exists to construct a balanced training data set, and the deformation signals are slower and more localised than in previous applications. We propose three enhancement methods to tackle these problems: i) spatial interpolation with modified matrix completion, ii) a synthetic training dataset based on the characteristics of real UK velocity map, and iii) enhanced over-wrapping techniques. Using velocity maps spanning 2015-2019, our framework detects several areas of coal mining subsidence, uplift due to dewatering, slate quarries, landslides and tunnel engineering works. The results demonstrate the potential applicability of the proposed framework to the development of automated ground motion analysis systems.
Visual Categorization of Objects into Animal and Plant Classes Using Global Shape Descriptors
Jan 25, 2019


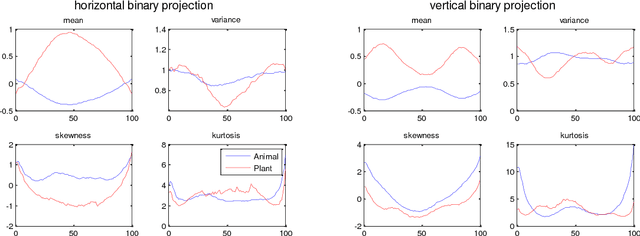
How humans can distinguish between general categories of objects? Are the subcategories of living things visually distinctive? In a number of semantic-category deficits, patients are good at making broad categorization but are unable to remember fine and specific details. It has been well accepted that general information about concepts are more robust to damages related to semantic memory. Results from patients with semantic memory disorders demonstrate the loss of ability in subcategory recognition. While bottom-up feature construction has been studied in detail, little attention has been served to top-down approach and the type of features that could account for general categorization. In this paper, we show that broad categories of animal and plant are visually distinguishable without processing textural information. To this aim, we utilize shape descriptors with an additional phase of feature learning. The results are evaluated with both supervised and unsupervised learning mechanisms. The obtained results demonstrate that global encoding of visual appearance of objects accounts for high discrimination between animal and plant object categories.
Conceptual Content in Deep Convolutional Neural Networks: An analysis into multi-faceted properties of neurons
Oct 31, 2018



In this paper we analyze convolutional layers of VGG16 model pre-trained on ILSVRC2012. We based our analysis on the responses of neurons to the images of all classes in ImageNet database. In our analysis, we first propose a visualization method to illustrate the learned content of each neuron. Next, we investigate single and multi-faceted neurons based on the diversity of neurons responses to different classes. Finally, we compute the neuronal similarity at each layer and make a comparison between them. Our results demonstrate that the neurons in lower layers exhibit a multi-faceted behavior, whereas the majority of neurons in higher layers comprise single-faceted property and tend to respond to a smaller number of classes.