 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Generative Explainers using Counterfactual Inference: A Case Study on the Morpho-MNIST Dataset
Paper and Code
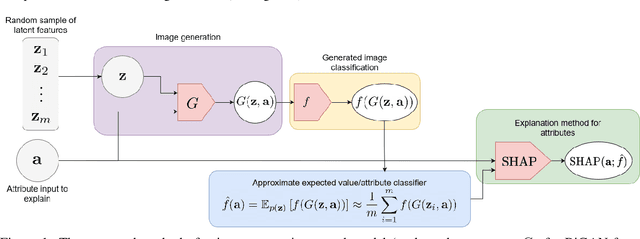
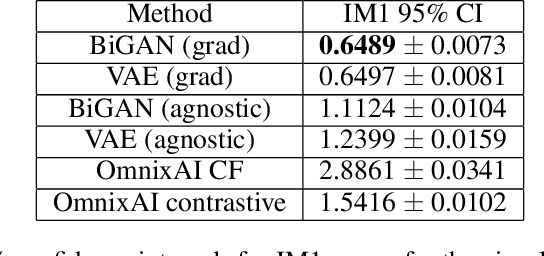

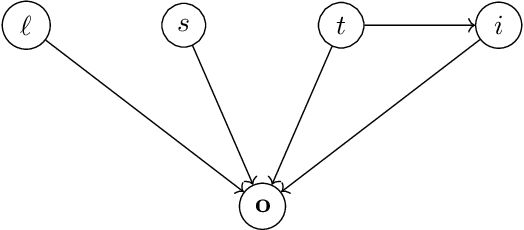
In this paper, we propose leveraging causal generative learning as an interpretable tool for explaining image classifiers. Specifically, we present a generative counterfactual inference approach to study the influence of visual features (i.e., pixels) as well as causal factors through generative learning. To this end, we first uncover the most influential pixels on a classifier's decision by varying the value of a causal attribute via counterfactual inference and computing both Shapely and contrastive explanations for counterfactual images with these different attribute values. We then establish a Monte-Carlo mechanism using the generator of a causal generative model in order to adapt Shapley explainers to produce feature importances for the human-interpretable attributes of a causal dataset in the case where a classifier has been trained exclusively on the images of the dataset. Finally, we present optimization methods for creating counterfactual explanations of classifiers by means of counterfactual inference, proposing straightforward approaches for both differentiable and arbitrary classifiers. We exploit the Morpho-MNIST causal dataset as a case study for exploring our proposed methods for generating counterfacutl explantions. We employ visual explanation methods from OmnixAI open source toolkit to compare them with our proposed methods. By employing quantitative metrics to measure the interpretability of counterfactual explanations, we find that our proposed methods of counterfactual explanation offer more interpretable explanations compared to those generated from OmnixAI. This finding suggests that our methods are well-suited for generating highly interpretable counterfactual explanations on causal datasets.