 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Prompt Alignment for Facial Expression Recognition
Jun 26, 2025Prompt learning has been widely adopted to efficiently adapt vision-language models (VLMs) like CLIP for various downstream tasks. Despite their success, current VLM-based facial expression recognition (FER) methods struggle to capture fine-grained textual-visual relationships, which are essential for distinguishing subtle differences between facial expressions. To address this challenge, we propose a multimodal prompt alignment framework for FER, called MPA-FER, that provides fine-grained semantic guidance to the learning process of prompted visual features, resulting in more precise and interpretable representations. Specifically, we introduce a multi-granularity hard prompt generation strategy that utilizes a large language model (LLM) like ChatGPT to generate detailed descriptions for each facial expression. The LLM-based external knowledge is injected into the soft prompts by minimizing the feature discrepancy between the soft prompts and the hard prompts. To preserve the generalization abilities of the pretrained CLIP model, our approach incorporates prototype-guided visual feature alignment, ensuring that the prompted visual features from the frozen image encoder align closely with class-specific prototypes. Additionally, we propose a cross-modal global-local alignment module that focuses on expression-relevant facial features, further improving the alignment between textual and visual features. Extensive experiments demonstrate our framework outperforms state-of-the-art methods on three FER benchmark datasets, while retaining the benefits of the pretrained model and minimizing computational costs.
GeReA: Question-Aware Prompt Captions for Knowledge-based Visual Question Answering
Feb 04, 2024Knowledge-based visual question answering (VQA) requires world knowledge beyond the image for accurate answer. Recently, instead of extra knowledge bases, a large language model (LLM) like GPT-3 is activated as an implicit knowledge engine to jointly acquire and reason the necessary knowledge for answering by converting images into textual information (e.g., captions and answer candidates). However, such conversion may introduce irrelevant information, which causes the LLM to misinterpret images and ignore visual details crucial for accurate knowledge. We argue that multimodal large language model (MLLM) is a better implicit knowledge engine than the LLM for its superior capability of visual understanding. Despite this, how to activate the capacity of MLLM as the implicit knowledge engine has not been explored yet. Therefore, we propose GeReA, a generate-reason framework that prompts a MLLM like InstructBLIP with question relevant vision and language information to generate knowledge-relevant descriptions and reasons those descriptions for knowledge-based VQA. Specifically, the question-relevant image regions and question-specific manual prompts are encoded in the MLLM to generate the knowledge relevant descriptions, referred to as question-aware prompt captions. After that, the question-aware prompt captions, image-question pair, and similar samples are sent into the multi-modal reasoning model to learn a joint knowledge-image-question representation for answer prediction. GeReA unlocks the use of MLLM as the implicit knowledge engine, surpassing all previous state-of-the-art methods on OK-VQA and A-OKVQA datasets, with test accuracies of 66.5% and 63.3% respectively. Our code will be released at https://github.com/Upper9527/GeReA.
LOGO-Former: Local-Global Spatio-Temporal Transformer for Dynamic Facial Expression Recognition
May 05, 2023


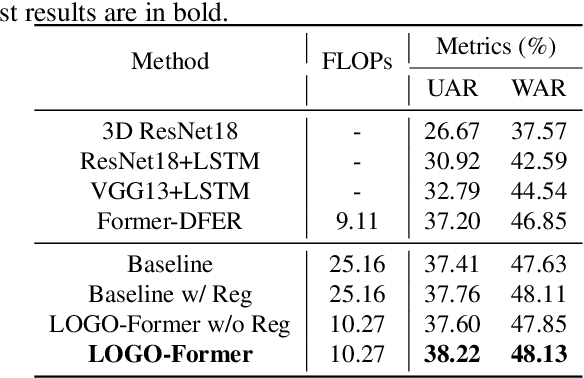
Previous methods for dynamic facial expression recognition (DFER) in the wild are mainly based on Convolutional Neural Networks (CNNs), whose local operations ignore the long-range dependencies in videos. Transformer-based methods for DFER can achieve better performances but result in higher FLOPs and computational costs. To solve these problems, the local-global spatio-temporal Transformer (LOGO-Former) is proposed to capture discriminative features within each frame and model contextual relationships among frames while balancing the complexity. Based on the priors that facial muscles move locally and facial expressions gradually change, we first restrict both the space attention and the time attention to a local window to capture local interactions among feature tokens. Furthermore, we perform the global attention by querying a token with features from each local window iteratively to obtain long-range information of the whole video sequence. In addition, we propose the compact loss regularization term to further encourage the learned features have the minimum intra-class distance and the maximum inter-class distance. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and FERV39K) indicate that our method provides an effective way to make use of the spatial and temporal dependencies for DFER.
Spatio-Temporal Transformer for Dynamic Facial Expression Recognition in the Wild
May 10, 2022
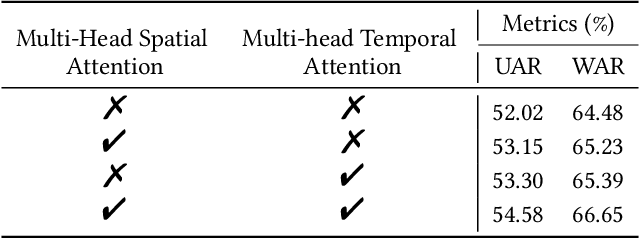
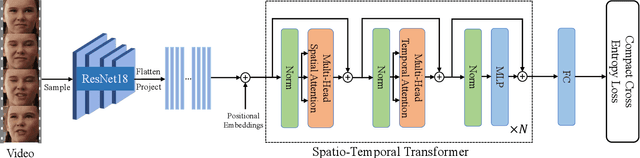

Previous methods for dynamic facial expression in the wild are mainly based on Convolutional Neural Networks (CNNs), whose local operations ignore the long-range dependencies in videos. To solve this problem, we propose the spatio-temporal Transformer (STT) to capture discriminative features within each frame and model contextual relationships among frames. Spatio-temporal dependencies are captured and integrated by our unified Transformer. Specifically, given an image sequence consisting of multiple frames as input, we utilize the CNN backbone to translate each frame into a visual feature sequence. Subsequently, the spatial attention and the temporal attention within each block are jointly applied for learning spatio-temporal representations at the sequence level. In addition, we propose the compact softmax cross entropy loss to further encourage the learned features have the minimum intra-class distance and the maximum inter-class distance. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and AFEW) indicate that our method provides an effective way to make use of the spatial and temporal dependencies for dynamic facial expression recognition. The source code and the training logs will be made publicly available.
Prompt-based Pre-trained Model for Personality and Interpersonal Reactivity Prediction
Mar 23, 2022
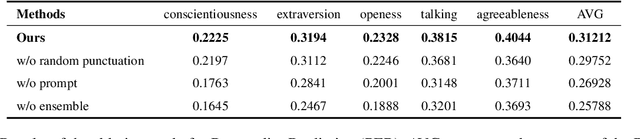


This paper describes the LingJing team's method to the Workshop on Computational Approaches to Subjectivity, Sentiment & Social Media Analysis (WASSA) 2022 shared task on Personality Prediction (PER) and Reactivity Index Prediction (IRI). In this paper, we adopt the prompt-based method with the pre-trained language model to accomplish these tasks. Specifically, the prompt is designed to provide the extra knowledge for enhancing the pre-trained model. Data augmentation and model ensemble are adopted for obtaining better results. Extensive experiments are performed, which shows the effectiveness of the proposed method. On the final submission, our system achieves a Pearson Correlation Coefficient of 0.2301 and 0.2546 on Track 3 and Track 4 respectively. We ranked Top-1 on both sub-tasks.
Hybrid Mutimodal Fusion for Dimensional Emotion Recognition
Oct 16, 2021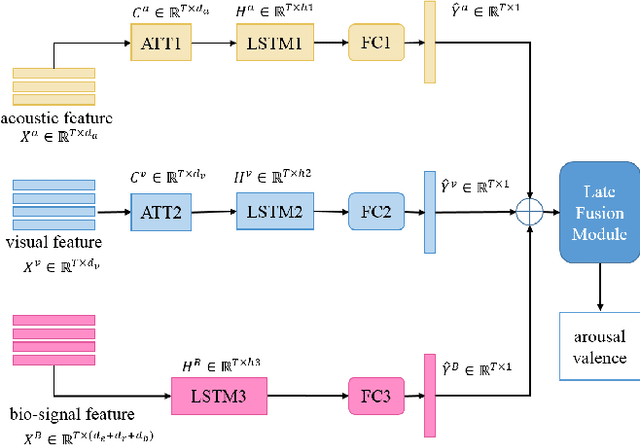
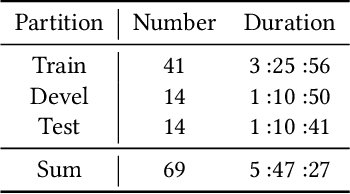
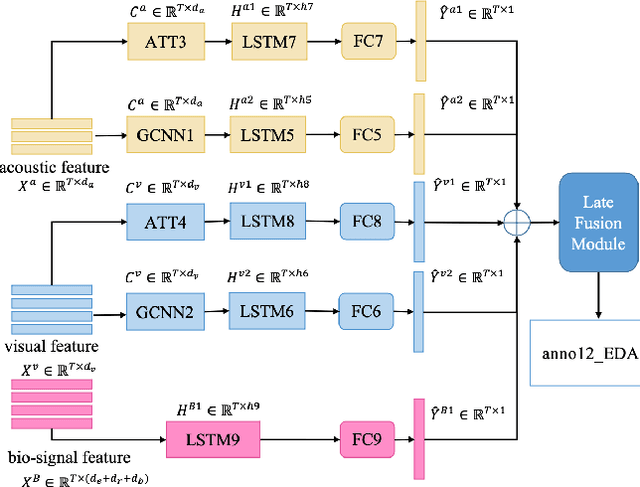
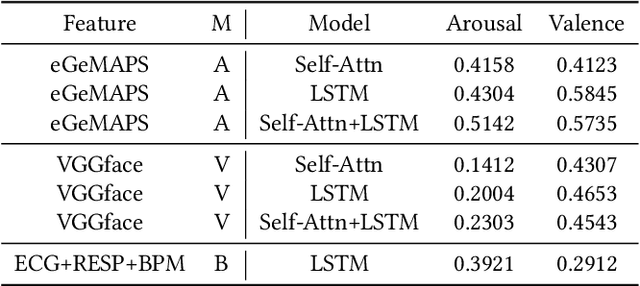
In this paper, we extensively present our solutions for the MuSe-Stress sub-challenge and the MuSe-Physio sub-challenge of Multimodal Sentiment Challenge (MuSe) 2021. The goal of MuSe-Stress sub-challenge is to predict the level of emotional arousal and valence in a time-continuous manner from audio-visual recordings and the goal of MuSe-Physio sub-challenge is to predict the level of psycho-physiological arousal from a) human annotations fused with b) galvanic skin response (also known as Electrodermal Activity (EDA)) signals from the stressed people. The Ulm-TSST dataset which is a novel subset of the audio-visual textual Ulm-Trier Social Stress dataset that features German speakers in a Trier Social Stress Test (TSST) induced stress situation is used in both sub-challenges. For the MuSe-Stress sub-challenge, we highlight our solutions in three aspects: 1) the audio-visual features and the bio-signal features are used for emotional state recognition. 2) the Long Short-Term Memory (LSTM) with the self-attention mechanism is utilized to capture complex temporal dependencies within the feature sequences. 3) the late fusion strategy is adopted to further boost the model's recognition performance by exploiting complementary information scattered across multimodal sequences. Our proposed model achieves CCC of 0.6159 and 0.4609 for valence and arousal respectively on the test set, which both rank in the top 3. For the MuSe-Physio sub-challenge, we first extract the audio-visual features and the bio-signal features from multiple modalities. Then, the LSTM module with the self-attention mechanism, and the Gated Convolutional Neural Networks (GCNN) as well as the LSTM network are utilized for modeling the complex temporal dependencies in the sequence. Finally, the late fusion strategy is used. Our proposed method also achieves CCC of 0.5412 on the test set, which ranks in the top 3.
Robust Facial Expression Recognition with Convolutional Visual Transformers
Mar 31, 2021
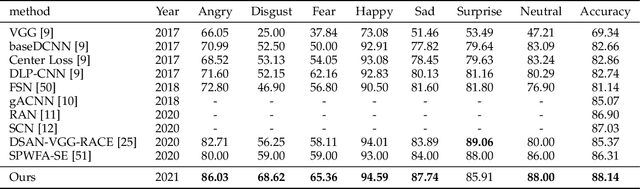
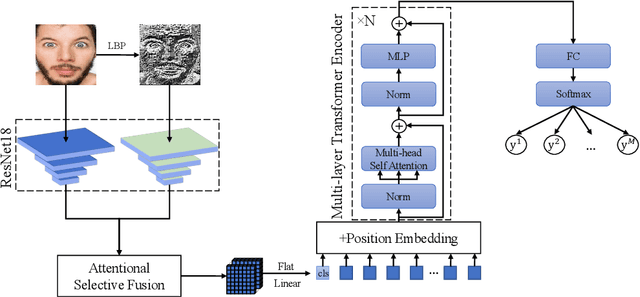
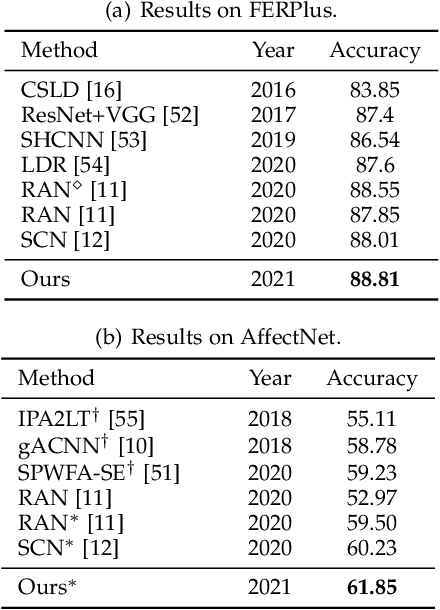
Facial Expression Recognition (FER) in the wild is extremely challenging due to occlusions, variant head poses, face deformation and motion blur under unconstrained conditions. Although substantial progresses have been made in automatic FER in the past few decades, previous studies are mainly designed for lab-controlled FER. Real-world occlusions, variant head poses and other issues definitely increase the difficulty of FER on account of these information-deficient regions and complex backgrounds. Different from previous pure CNNs based methods, we argue that it is feasible and practical to translate facial images into sequences of visual words and perform expression recognition from a global perspective. Therefore, we propose Convolutional Visual Transformers to tackle FER in the wild by two main steps. First, we propose an attentional selective fusion (ASF) for leveraging the feature maps generated by two-branch CNNs. The ASF captures discriminative information by fusing multiple features with global-local attention. The fused feature maps are then flattened and projected into sequences of visual words. Second, inspired by the success of Transformers in natural language processing, we propose to model relationships between these visual words with global self-attention. The proposed method are evaluated on three public in-the-wild facial expression datasets (RAF-DB, FERPlus and AffectNet). Under the same settings, extensive experiments demonstrate that our method shows superior performance over other methods, setting new state of the art on RAF-DB with 88.14%, FERPlus with 88.81% and AffectNet with 61.85%. We also conduct cross-dataset evaluation on CK+ show the generalization capability of the proposed method.