 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction Embedding: Latent Representations of Instructions Towards Task Identification
Sep 29, 2024



Instruction data is crucial for improving the capability of Large Language Models (LLMs) to align with human-level performance. Recent research LIMA demonstrates that alignment is essentially a process where the model adapts instructions' interaction style or format to solve various tasks, leveraging pre-trained knowledge and skills. Therefore, for instructional data, the most important aspect is the task it represents, rather than the specific semantics and knowledge information. The latent representations of instructions play roles for some instruction-related tasks like data selection and demonstrations retrieval. However, they are always derived from text embeddings, encompass overall semantic information that influences the representation of task categories. In this work, we introduce a new concept, instruction embedding, and construct Instruction Embedding Benchmark (IEB) for its training and evaluation. Then, we propose a baseline Prompt-based Instruction Embedding (PIE) method to make the representations more attention on tasks. The evaluation of PIE, alongside other embedding methods on IEB with two designed tasks, demonstrates its superior performance in accurately identifying task categories. Moreover, the application of instruction embeddings in four downstream tasks showcases its effectiveness and suitability for instruction-related tasks.
Focused Large Language Models are Stable Many-Shot Learners
Aug 26, 2024



In-Context Learning (ICL) enables large language models (LLMs) to achieve rapid task adaptation by learning from demonstrations. With the increase in available context length of LLMs, recent experiments have shown that the performance of ICL does not necessarily scale well in many-shot (demonstration) settings. We theoretically and experimentally confirm that the reason lies in more demonstrations dispersing the model attention from the query, hindering its understanding of key content. Inspired by how humans learn from examples, we propose a training-free method FocusICL, which conducts triviality filtering to avoid attention being diverted by unimportant contents at token-level and operates hierarchical attention to further ensure sufficient attention towards current query at demonstration-level. We also design an efficient hyperparameter searching strategy for FocusICL based on model perplexity of demonstrations. Comprehensive experiments validate that FocusICL achieves an average performance improvement of 5.2% over vanilla ICL and scales well with many-shot demonstrations.
Poor-Supervised Evaluation for SuperLLM via Mutual Consistency
Aug 25, 2024


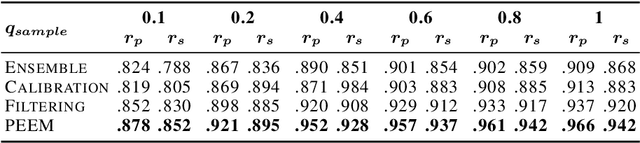
The guidance from capability evaluations has greatly propelled the progress of both human society and Artificial Intelligence. However, as LLMs evolve, it becomes challenging to construct evaluation benchmarks for them with accurate labels on hard tasks that approach the boundaries of human capabilities. To credibly conduct evaluation without accurate labels (denoted as poor-supervised evaluation), we propose the PoEM framework. We first prove that the capability of a model can be equivalently assessed by the consistency between it and certain reference model, when their prediction distributions are independent and the sample size is infinite. To alleviate the insufficiencies of the conditions in reality, we further introduce an algorithm that treats humans (when available) and the models under evaluation as reference models, alternately conducting model weights calibration and filtering during E-step and M-step. Comprehensive experiments across 3 types of tasks with 16 mainstream LLMs have shown that PoEM under poor supervision can achieve an average of 0.98 Pearson correlation coefficient with supervised evaluation results, demonstrating good effectiveness, efficiency and generalizability. More generally, PoEM has advanced the evaluation paradigm evolution from human-centric to human&model-centric by treating both of them as reference models, mitigating the limitations of human evaluation in the era of LLMs.
Make Every Penny Count: Difficulty-Adaptive Self-Consistency for Cost-Efficient Reasoning
Aug 24, 2024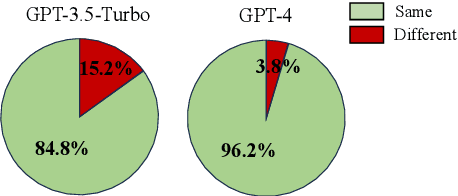


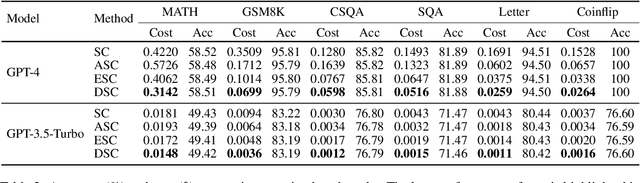
Self-consistency (SC), a widely used decoding strategy for chain-of-thought reasoning, shows significant gains across various multi-step reasoning tasks but comes with a high cost due to multiple sampling with the preset size. Its variants, Adaptive self-consistency (ASC) and Early-stopping self-consistency (ESC), dynamically adjust the number of samples based on the posterior distribution of a set of pre-samples, reducing the cost of SC with minimal impact on performance. Both methods, however, do not exploit the prior information about question difficulty. It often results in unnecessary repeated sampling for easy questions that could be accurately answered with just one attempt, wasting resources. To tackle this problem, we propose Difficulty-Adaptive Self-Consistency (DSC), which leverages the difficulty information from both prior and posterior perspectives to adaptively allocate inference resources, further reducing the cost of SC. To demonstrate the effectiveness of DSC, we conduct extensive experiments on three popular categories of reasoning tasks: arithmetic, commonsense and symbolic reasoning on six benchmarks. The empirical results show that DSC consistently surpasses the strong baseline ASC and ESC in terms of costs by a significant margin, while attaining comparable performances.
CogLM: Tracking Cognitive Development of Large Language Models
Aug 17, 2024



Piaget's Theory of Cognitive Development (PTC) posits that the development of cognitive levels forms the foundation for human learning across various abilities. As Large Language Models (LLMs) have recently shown remarkable abilities across a wide variety of tasks, we are curious about the cognitive levels of current LLMs: to what extent they have developed and how this development has been achieved. To this end, we construct a benchmark CogLM (Cognitive Ability Evaluation for Language Model) based on PTC to assess the cognitive levels of LLMs. CogLM comprises 1,220 questions spanning 10 cognitive abilities crafted by more than 20 human experts, providing a comprehensive testbed for the cognitive levels of LLMs. Through extensive experiments across multiple mainstream LLMs with CogLM, we find that: (1) Human-like cognitive abilities have emerged in advanced LLMs (GPT-4), comparable to those of a 20-year-old human. (2) The parameter size and optimization objective are two key factors affecting the cognitive levels of LLMs. (3) The performance on downstream tasks is positively correlated with the level of cognitive abilities. These findings fill the gap in research on the cognitive abilities of LLMs, tracing the development of LLMs from a cognitive perspective and guiding the future direction of their evolution.
Integrate the Essence and Eliminate the Dross: Fine-Grained Self-Consistency for Free-Form Language Generation
Jul 02, 2024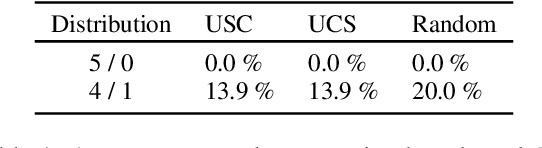



Self-consistency (SC), leveraging multiple samples from LLMs, shows significant gains on various reasoning tasks but struggles with free-form generation due to the difficulty of aggregating answers. Its variants, UCS and USC, rely on sample selection or voting mechanisms to improve output quality. These methods, however, face limitations due to their inability to fully utilize the nuanced consensus knowledge present within multiple candidate samples, often resulting in suboptimal outputs. We propose Fine-Grained Self-Consistency (FSC) to addresses these limitations by extracting and integrating segment-level commonalities from candidate samples, enhancing the performance of LLMs both in open-ended and reasoning tasks. Based on this, we present two additional strategies: candidate filtering, which enhances overall quality by identifying highly similar candidate sets, and merging, which reduces input token requirements by combining similar samples. The effectiveness of FSC is demonstrated through extensive experiments on various tasks, including summarization, code generation, and mathematical reasoning, using GPT-3.5-turbo and GPT-4. The results indicate significant improvements over baseline methods, showcasing the potential of FSC to optimize output quality by effectively synthesizing fine-grained consensus knowledge from multiple samples.
Escape Sky-high Cost: Early-stopping Self-Consistency for Multi-step Reasoning
Jan 19, 2024Self-consistency (SC) has been a widely used decoding strategy for chain-of-thought reasoning. Despite bringing significant performance improvements across a variety of multi-step reasoning tasks, it is a high-cost method that requires multiple sampling with the preset size. In this paper, we propose a simple and scalable sampling process, \textbf{E}arly-Stopping \textbf{S}elf-\textbf{C}onsistency (ESC), to greatly reduce the cost of SC without sacrificing performance. On this basis, one control scheme for ESC is further derivated to dynamically choose the performance-cost balance for different tasks and models. To demonstrate ESC's effectiveness, we conducted extensive experiments on three popular categories of reasoning tasks: arithmetic, commonsense and symbolic reasoning over language models with varying scales. The empirical results show that ESC reduces the average number of sampling of chain-of-thought reasoning by a significant margin on six benchmarks, including MATH (-33.8%), GSM8K (-80.1%), StrategyQA (-76.8%), CommonsenseQA (-78.5%), Coin Flip (-84.2%) and Last Letters (-67.4%), while attaining comparable performances.
Generative Dense Retrieval: Memory Can Be a Burden
Jan 19, 2024


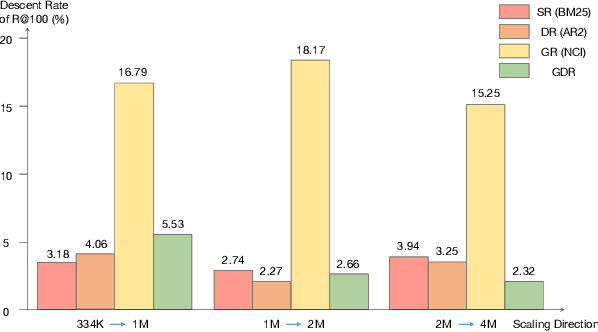
Generative Retrieval (GR), autoregressively decoding relevant document identifiers given a query, has been shown to perform well under the setting of small-scale corpora. By memorizing the document corpus with model parameters, GR implicitly achieves deep interaction between query and document. However, such a memorizing mechanism faces three drawbacks: (1) Poor memory accuracy for fine-grained features of documents; (2) Memory confusion gets worse as the corpus size increases; (3) Huge memory update costs for new documents. To alleviate these problems, we propose the Generative Dense Retrieval (GDR) paradigm. Specifically, GDR first uses the limited memory volume to achieve inter-cluster matching from query to relevant document clusters. Memorizing-free matching mechanism from Dense Retrieval (DR) is then introduced to conduct fine-grained intra-cluster matching from clusters to relevant documents. The coarse-to-fine process maximizes the advantages of GR's deep interaction and DR's scalability. Besides, we design a cluster identifier constructing strategy to facilitate corpus memory and a cluster-adaptive negative sampling strategy to enhance the intra-cluster mapping ability. Empirical results show that GDR obtains an average of 3.0 R@100 improvement on NQ dataset under multiple settings and has better scalability.
* EACL 2024 main
BatchEval: Towards Human-like Text Evaluation
Dec 31, 2023Significant progress has been made in automatic text evaluation with the introduction of large language models (LLMs) as evaluators. However, current sample-wise evaluation paradigm suffers from the following issues: (1) Sensitive to prompt design; (2) Poor resistance to noise; (3) Inferior ensemble performance with static reference. Inspired by the fact that humans treat both criterion definition and inter sample comparison as references for evaluation, we propose BatchEval, a paradigm that conducts batch-wise evaluation iteratively to alleviate the above problems. We explore variants under this paradigm and confirm the optimal settings are two stage procedure with heterogeneous batch composition strategy and decimal scoring format. Comprehensive experiments across 3 LLMs on 4 text evaluation tasks demonstrate that BatchEval outperforms state-of-the-art methods by 10.5% on Pearson correlations with only 64% API cost on average. Further analyses have been conducted to verify the robustness, generalization, and working mechanism of BatchEval.
Turning Dust into Gold: Distilling Complex Reasoning Capabilities from LLMs by Leveraging Negative Data
Dec 20, 2023



Large Language Models (LLMs) have performed well on various reasoning tasks, but their inaccessibility and numerous parameters hinder wide application in practice. One promising way is distilling the reasoning ability from LLMs to small models by the generated chain-of-thought reasoning paths. In some cases, however, LLMs may produce incorrect reasoning chains, especially when facing complex mathematical problems. Previous studies only transfer knowledge from positive samples and drop the synthesized data with wrong answers. In this work, we illustrate the merit of negative data and propose a model specialization framework to distill LLMs with negative samples besides positive ones. The framework consists of three progressive steps, covering from training to inference stages, to absorb knowledge from negative data. We conduct extensive experiments across arithmetic reasoning tasks to demonstrate the role of negative data in distillation from LLM.