 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning More from Less: Unlocking Internal Representations for Benchmark Compression
Feb 03, 2026The prohibitive cost of evaluating Large Language Models (LLMs) necessitates efficient alternatives to full-scale benchmarking. Prevalent approaches address this by identifying a small coreset of items to approximate full-benchmark performance. However, existing methods must estimate a reliable item profile from response patterns across many source models, which becomes statistically unstable when the source pool is small. This dependency is particularly limiting for newly released benchmarks with minimal historical evaluation data. We argue that discrete correctness labels are a lossy view of the model's decision process and fail to capture information encoded in hidden states. To address this, we introduce REPCORE, which aligns heterogeneous hidden states into a unified latent space to construct representative coresets. Using these subsets for performance extrapolation, REPCORE achieves precise estimation accuracy with as few as ten source models. Experiments on five benchmarks and over 200 models show consistent gains over output-based baselines in ranking correlation and estimation accuracy. Spectral analysis further indicates that the aligned representations contain separable components reflecting broad response tendencies and task-specific reasoning patterns.
Do Not Waste Your Rollouts: Recycling Search Experience for Efficient Test-Time Scaling
Jan 29, 2026Test-Time Scaling enhances the reasoning capabilities of Large Language Models by allocating additional inference compute to broaden the exploration of the solution space. However, existing search strategies typically treat rollouts as disposable samples, where valuable intermediate insights are effectively discarded after each trial. This systemic memorylessness leads to massive computational redundancy, as models repeatedly re-derive discovered conclusions and revisit known dead ends across extensive attempts. To bridge this gap, we propose \textbf{Recycling Search Experience (RSE)}, a self-guided, training-free strategy that turns test-time search from a series of isolated trials into a cumulative process. By actively distilling raw trajectories into a shared experience bank, RSE enables positive recycling of intermediate conclusions to shortcut redundant derivations and negative recycling of failure patterns to prune encountered dead ends. Theoretically, we provide an analysis that formalizes the efficiency gains of RSE, validating its advantage over independent sampling in solving complex reasoning tasks. Empirically, extensive experiments on HMMT24, HMMT25, IMO-Bench, and HLE show that RSE consistently outperforms strong baselines with comparable computational cost, achieving state-of-the-art scaling efficiency.
Mind the Quote: Enabling Quotation-Aware Dialogue in LLMs via Plug-and-Play Modules
May 30, 2025Human-AI conversation frequently relies on quoting earlier text-"check it with the formula I just highlighted"-yet today's large language models (LLMs) lack an explicit mechanism for locating and exploiting such spans. We formalise the challenge as span-conditioned generation, decomposing each turn into the dialogue history, a set of token-offset quotation spans, and an intent utterance. Building on this abstraction, we introduce a quotation-centric data pipeline that automatically synthesises task-specific dialogues, verifies answer correctness through multi-stage consistency checks, and yields both a heterogeneous training corpus and the first benchmark covering five representative scenarios. To meet the benchmark's zero-overhead and parameter-efficiency requirements, we propose QuAda, a lightweight training-based method that attaches two bottleneck projections to every attention head, dynamically amplifying or suppressing attention to quoted spans at inference time while leaving the prompt unchanged and updating < 2.8% of backbone weights. Experiments across models show that QuAda is suitable for all scenarios and generalises to unseen topics, offering an effective, plug-and-play solution for quotation-aware dialogue.
Silencer: From Discovery to Mitigation of Self-Bias in LLM-as-Benchmark-Generator
May 27, 2025



LLM-as-Benchmark-Generator methods have been widely studied as a supplement to human annotators for scalable evaluation, while the potential biases within this paradigm remain underexplored. In this work, we systematically define and validate the phenomenon of inflated performance in models evaluated on their self-generated benchmarks, referred to as self-bias, and attribute it to sub-biases arising from question domain, language style, and wrong labels. On this basis, we propose Silencer, a general framework that leverages the heterogeneity between multiple generators at both the sample and benchmark levels to neutralize bias and generate high-quality, self-bias-silenced benchmark. Experimental results across various settings demonstrate that Silencer can suppress self-bias to near zero, significantly improve evaluation effectiveness of the generated benchmark (with an average improvement from 0.655 to 0.833 in Pearson correlation with high-quality human-annotated benchmark), while also exhibiting strong generalizability.
Speculative Decoding for Multi-Sample Inference
Mar 07, 2025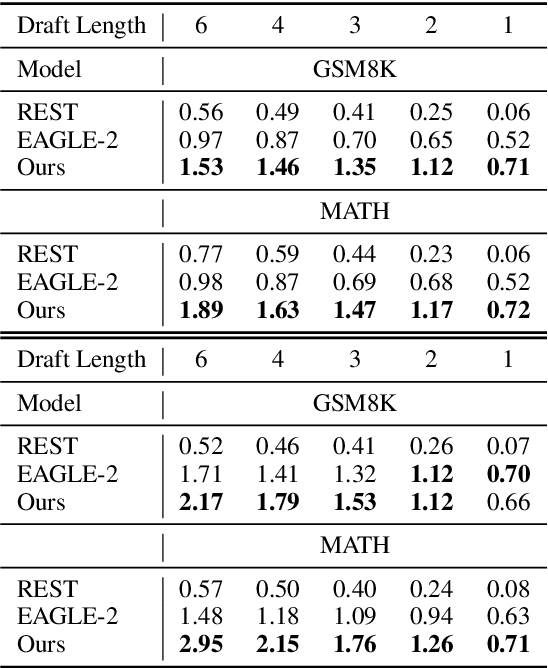
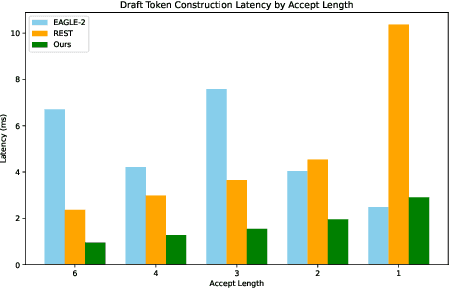
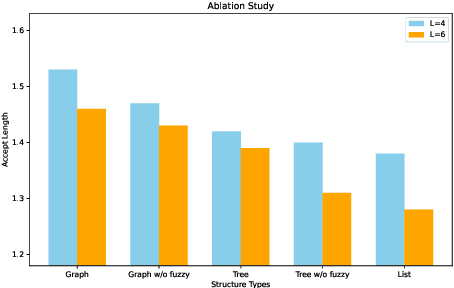
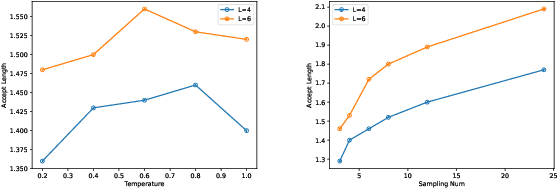
We propose a novel speculative decoding method tailored for multi-sample reasoning scenarios, such as self-consistency and Best-of-N sampling. Our method exploits the intrinsic consensus of parallel generation paths to synthesize high-quality draft tokens without requiring auxiliary models or external databases. By dynamically analyzing structural patterns across parallel reasoning paths through a probabilistic aggregation mechanism, it identifies consensus token sequences that align with the decoding distribution. Evaluations on mathematical reasoning benchmarks demonstrate a substantial improvement in draft acceptance rates over baselines, while reducing the latency in draft token construction. This work establishes a paradigm shift for efficient multi-sample inference, enabling seamless integration of speculative decoding with sampling-based reasoning techniques.
Revisiting Self-Consistency from Dynamic Distributional Alignment Perspective on Answer Aggregation
Feb 27, 2025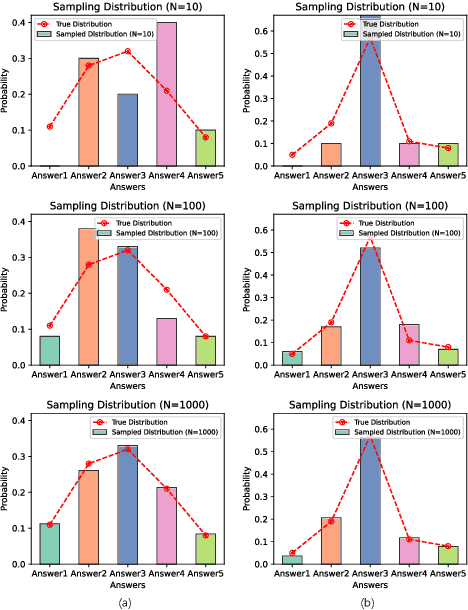
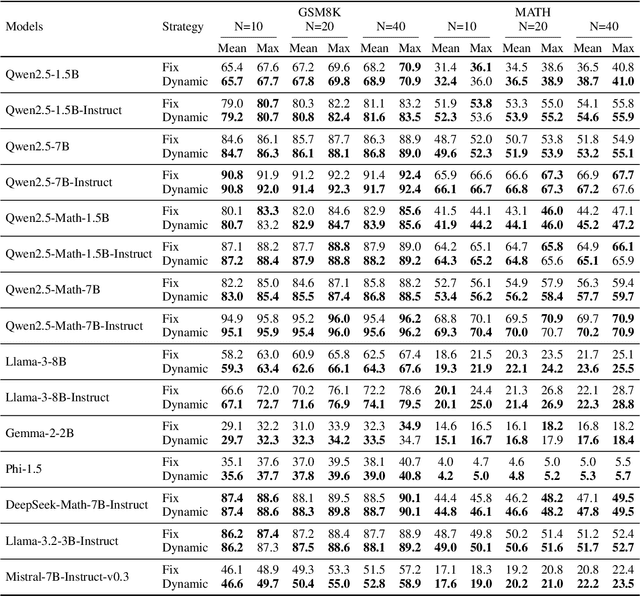
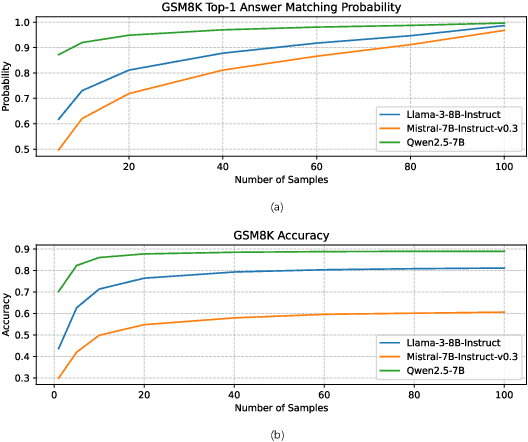
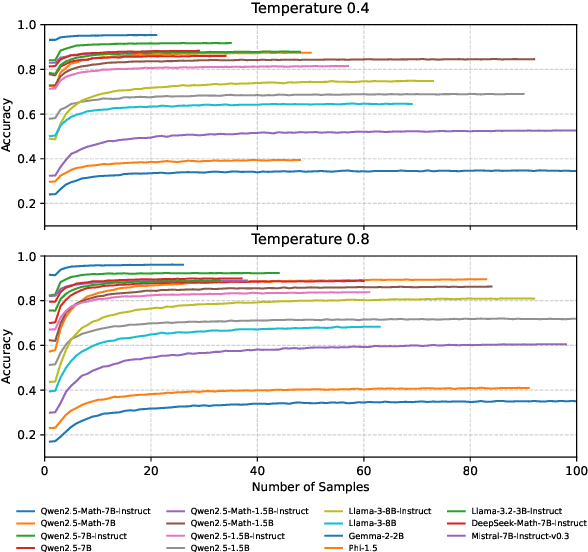
Self-consistency improves reasoning by aggregating diverse stochastic samples, yet the dynamics behind its efficacy remain underexplored. We reframe self-consistency as a dynamic distributional alignment problem, revealing that decoding temperature not only governs sampling randomness but also actively shapes the latent answer distribution. Given that high temperatures require prohibitively large sample sizes to stabilize, while low temperatures risk amplifying biases, we propose a confidence-driven mechanism that dynamically calibrates temperature: sharpening the sampling distribution under uncertainty to align with high-probability modes, and promoting exploration when confidence is high. Experiments on mathematical reasoning tasks show this approach outperforms fixed-diversity baselines under limited samples, improving both average and best-case performance across varying initial temperatures without additional data or modules. This establishes self-consistency as a synchronization challenge between sampling dynamics and evolving answer distributions.
Beyond One-Size-Fits-All: Tailored Benchmarks for Efficient Evaluation
Feb 19, 2025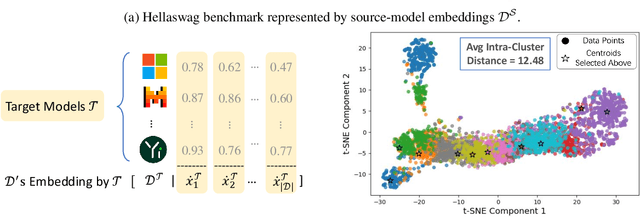
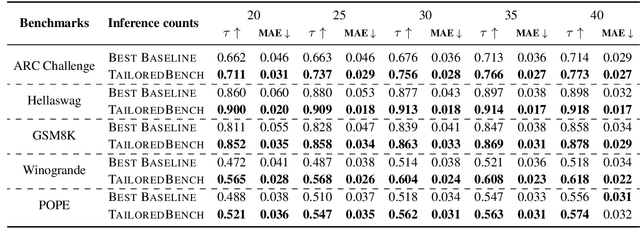
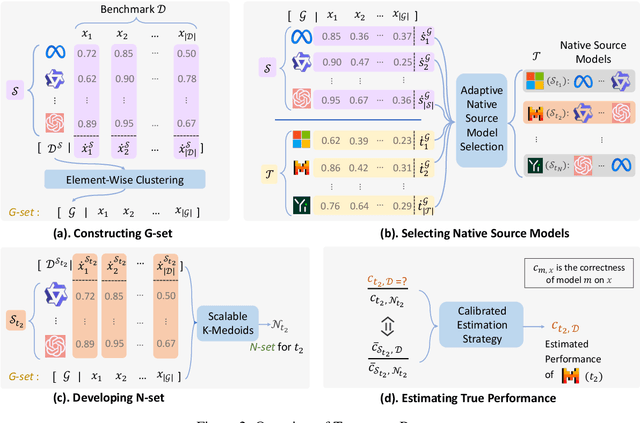
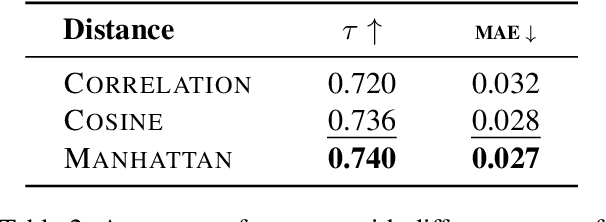
Evaluating models on large benchmarks is very resource-intensive, especially during the period of rapid model evolution. Existing efficient evaluation methods estimate the performance of target models by testing them only on a small and static coreset of the benchmark, which is derived from the publicly available evaluation results of source models. These methods rely on the assumption that target models have high prediction consistency with source models. However, we demonstrate that it doesn't generalize well in practice. To alleviate the inconsistency issue, we present TailoredBench, a method that conducts customized evaluation tailored to each target model. Specifically, a Global-coreset is first constructed as a probe to identify the most consistent source models for each target model with an adaptive source model selection strategy. Afterwards, a scalable K-Medoids clustering algorithm is proposed to extend the Global-coreset to a tailored Native-coreset for each target model. According to the predictions on Native-coresets, we obtain the performance of target models on the whole benchmark with a calibrated estimation strategy. Comprehensive experiments on 5 benchmarks across over 300 models demonstrate that compared to best performing baselines, TailoredBench achieves an average reduction of 31.4% in MAE of accuracy estimates under the same inference budgets, showcasing strong effectiveness and generalizability.
From Sub-Ability Diagnosis to Human-Aligned Generation: Bridging the Gap for Text Length Control via MARKERGEN
Feb 19, 2025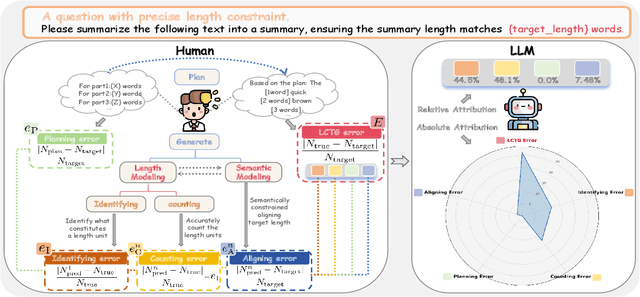
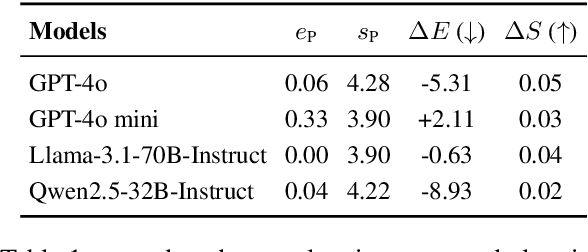
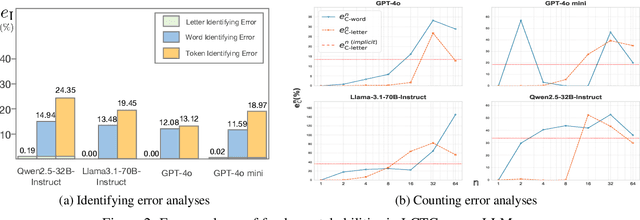
Despite the rapid progress of large language models (LLMs), their length-controllable text generation (LCTG) ability remains below expectations, posing a major limitation for practical applications. Existing methods mainly focus on end-to-end training to reinforce adherence to length constraints. However, the lack of decomposition and targeted enhancement of LCTG sub-abilities restricts further progress.To bridge this gap, we conduct a bottom-up decomposition of LCTG sub-abilities with human patterns as reference and perform a detailed error analysis.On this basis, we propose MarkerGen, a simple-yet-effective plug-and-play approach that:(1) mitigates LLM fundamental deficiencies via external tool integration;(2) conducts explicit length modeling with dynamically inserted markers;(3) employs a three-stage generation scheme to better align length constraints while maintaining content quality.Comprehensive experiments demonstrate that MarkerGen significantly improves LCTG across various settings, exhibiting outstanding effectiveness and generalizability.
UniCBE: An Uniformity-driven Comparing Based Evaluation Framework with Unified Multi-Objective Optimization
Feb 17, 2025Human preference plays a significant role in measuring large language models and guiding them to align with human values. Unfortunately, current comparing-based evaluation (CBE) methods typically focus on a single optimization objective, failing to effectively utilize scarce yet valuable preference signals. To address this, we delve into key factors that can enhance the accuracy, convergence, and scalability of CBE: suppressing sampling bias, balancing descending process of uncertainty, and mitigating updating uncertainty. Following the derived guidelines, we propose UniCBE, a unified uniformity-driven CBE framework which simultaneously optimize these core objectives by constructing and integrating three decoupled sampling probability matrices, each designed to ensure uniformity in specific aspects. We further ablate the optimal tuple sampling and preference aggregation strategies to achieve efficient CBE. On the AlpacaEval benchmark, UniCBE saves over 17% of evaluation budgets while achieving a Pearson correlation with ground truth exceeding 0.995, demonstrating excellent accuracy and convergence. In scenarios where new models are continuously introduced, UniCBE can even save over 50% of evaluation costs, highlighting its improved scalability.
InsBank: Evolving Instruction Subset for Ongoing Alignment
Feb 17, 2025



Large language models (LLMs) typically undergo instruction tuning to enhance alignment. Recent studies emphasize that quality and diversity of instruction data are more crucial than quantity, highlighting the need to select diverse, high-quality subsets to reduce training costs. However, how to evolve these selected subsets alongside the development of new instruction data remains insufficiently explored. To achieve LLMs' ongoing alignment, we introduce Instruction Bank (InsBank), a continuously updated repository that integrates the latest valuable instruction data. We further propose Progressive Instruction Bank Evolution (PIBE), a novel framework designed to evolve InsBank effectively and efficiently over time. PIBE employs a gradual data selection strategy to maintain long-term efficiency, leveraging a representation-based diversity score to capture relationships between data points and retain historical information for comprehensive diversity evaluation. This also allows for flexible combination of diversity and quality scores during data selection and ranking. Extensive experiments demonstrate that PIBE significantly outperforms baselines in InsBank evolution and is able to extract budget-specific subsets, demonstrating its effectiveness and adaptability.