 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond One-Size-Fits-All: Tailored Benchmarks for Efficient Evaluation
Paper and Code
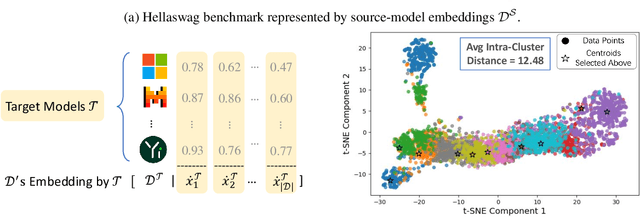
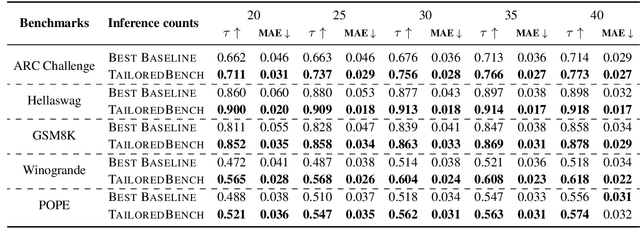
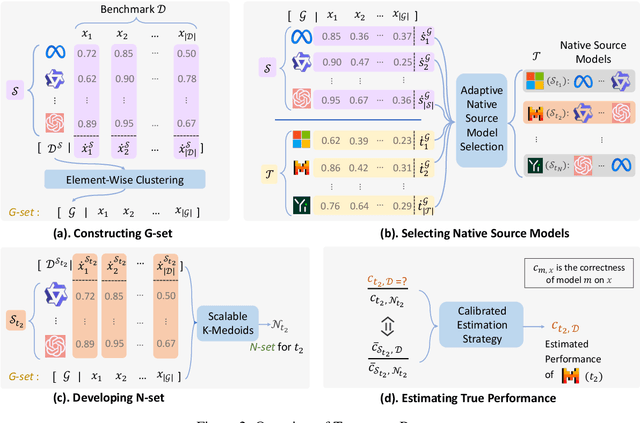
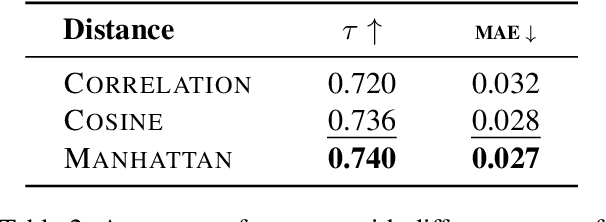
Evaluating models on large benchmarks is very resource-intensive, especially during the period of rapid model evolution. Existing efficient evaluation methods estimate the performance of target models by testing them only on a small and static coreset of the benchmark, which is derived from the publicly available evaluation results of source models. These methods rely on the assumption that target models have high prediction consistency with source models. However, we demonstrate that it doesn't generalize well in practice. To alleviate the inconsistency issue, we present TailoredBench, a method that conducts customized evaluation tailored to each target model. Specifically, a Global-coreset is first constructed as a probe to identify the most consistent source models for each target model with an adaptive source model selection strategy. Afterwards, a scalable K-Medoids clustering algorithm is proposed to extend the Global-coreset to a tailored Native-coreset for each target model. According to the predictions on Native-coresets, we obtain the performance of target models on the whole benchmark with a calibrated estimation strategy. Comprehensive experiments on 5 benchmarks across over 300 models demonstrate that compared to best performing baselines, TailoredBench achieves an average reduction of 31.4% in MAE of accuracy estimates under the same inference budgets, showcasing strong effectiveness and generalizability.