 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMIC: Semantic Multi-Item Compression based on CLIP dictionary
Paper and Code
Dec 06, 2024

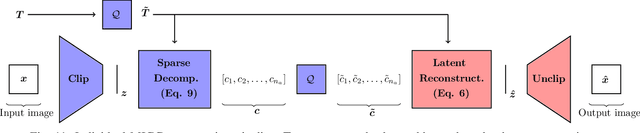
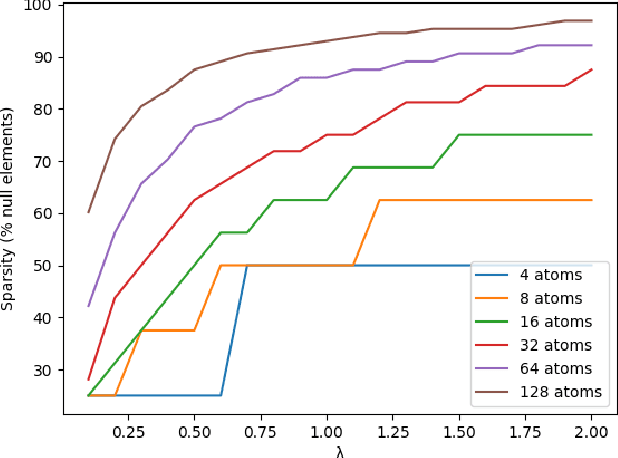
Semantic compression, a compression scheme where the distortion metric, typically MSE, is replaced with semantic fidelity metrics, tends to become more and more popular. Most recent semantic compression schemes rely on the foundation model CLIP. In this work, we extend such a scheme to image collection compression, where inter-item redundancy is taken into account during the coding phase. For that purpose, we first show that CLIP's latent space allows for easy semantic additions and subtractions. From this property, we define a dictionary-based multi-item codec that outperforms state-of-the-art generative codec in terms of compression rate, around $10^{-5}$ BPP per image, while not sacrificing semantic fidelity. We also show that the learned dictionary is of a semantic nature and works as a semantic projector for the semantic content of images.