 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling Data with Chains of Forward-Backward Diffusion Steps
May 26, 2026Sampling from learned high-dimensional distributions is a foundational computational problem. We introduce U-turn chains: Markov chains obtained by iterating short forward-backward steps of a diffusion model, in which each step proposes a move that remains on the learned data manifold and, paired with a Metropolis-Hastings correction, samples from energy-modified targets. For synthetic languages, we show that minimal U-turn dynamics undergoes an ergodicity-breaking phase transition driven by fragmentation of the data manifold; ergodicity is restored at larger U-turn magnitude. In the non-ergodic regime, low-level features relax faster than high-level ones, an ordering that inverts only at sufficiently large U-turn magnitude. We test these predictions on natural language and natural images. In both modalities, minimal U-turns relax slowly, especially for high-level features approximated by deep representations in CNNs or LLMs. The layer-ordering inversion appears only at large noise when mixing is efficient -- signatures consistent with strongly constrained, weakly mixing local dynamics. We discuss the implications of these results for sampling with diffusion models.
Learn from your own latents and not from tokens: A sample-complexity theory
May 26, 2026Generative models, from diffusion models to large language models, achieve remarkable performance but at a cost in training data orders of magnitude larger than what biological learners require. An alternative paradigm has emerged in which networks are trained to predict their \emph{own} latent representations of related views or masked regions, as in data2vec and JEPA -- an idea related to predictive-coding accounts of the cortex. Despite strong empirical results, the theoretical understanding of these methods remains limited. Central questions include: by how much does latent prediction actually improve data efficiency? Is there a benefit to stacking such methods into multi-scale hierarchies? We answer both using as data a tractable probabilistic context-free grammar that captures the compositional structure of natural language and images. Such a grammar generates strings of visible tokens by recursively applying production rules along a tree of hidden symbols of depth $L$. For such data, supervised or token-level SSL require a number of samples \emph{exponential} in $L$ to recover the latent tree; we prove that latent prediction achieves this with a number of samples \emph{constant} in $L$, up to logarithmic factors. We confirm this bound with (i) a hierarchical clustering algorithm, (ii) an end-to-end neural network whose predictor-clusterer modules predict their own latents at each level via gradient descent, and (iii) the first sample-complexity analysis of data2vec, which we show implicitly performs hierarchical latent prediction. This suggests that explicit stacking such as H-JEPA is largely redundant.
Hierarchical Concept Geometry in Language Models Emerges from Word Co-occurrence
May 22, 2026We propose a distributional theory of how hypernymy -- the ``is-a'' relation between general and specific concepts -- is encoded geometrically in language representations. Starting from the empirically verified assumption that words closer on the WordNet hypernym graph co-occur more often, we characterize theoretically the spectrum of the resulting embedding Gram matrix of word2vec embeddings. Under mild positivity and decay conditions on the co-occurrence kernel, we prove that the leading eigenvectors first separate broad taxonomic branches and then progressively finer sub-branches, producing a \emph{hierarchical splitting geometry} with a coarse-to-fine spectral organization that mirrors the tree. We confirm these predictions in word2vec embeddings across many sampled WordNet subtrees, and show that the same signature extends strikingly well to Gemma 2B unembeddings. Our results indicate that hierarchical concept geometry in LLMs need not reflect a hierarchy-specific functional mechanism, but emerges from the spectral structure of pairwise word statistics.
Symmetry in language statistics shapes the geometry of model representations
Feb 16, 2026Although learned representations underlie neural networks' success, their fundamental properties remain poorly understood. A striking example is the emergence of simple geometric structures in LLM representations: for example, calendar months organize into a circle, years form a smooth one-dimensional manifold, and cities' latitudes and longitudes can be decoded by a linear probe. We show that the statistics of language exhibit a translation symmetry -- e.g., the co-occurrence probability of two months depends only on the time interval between them -- and we prove that the latter governs the aforementioned geometric structures in high-dimensional word embedding models. Moreover, we find that these structures persist even when the co-occurrence statistics are strongly perturbed (for example, by removing all sentences in which two months appear together) and at moderate embedding dimension. We show that this robustness naturally emerges if the co-occurrence statistics are collectively controlled by an underlying continuous latent variable. We empirically validate this theoretical framework in word embedding models, text embedding models, and large language models.
Deep networks learn to parse uniform-depth context-free languages from local statistics
Feb 09, 2026Understanding how the structure of language can be learned from sentences alone is a central question in both cognitive science and machine learning. Studies of the internal representations of Large Language Models (LLMs) support their ability to parse text when predicting the next word, while representing semantic notions independently of surface form. Yet, which data statistics make these feats possible, and how much data is required, remain largely unknown. Probabilistic context-free grammars (PCFGs) provide a tractable testbed for studying these questions. However, prior work has focused either on the post-hoc characterization of the parsing-like algorithms used by trained networks; or on the learnability of PCFGs with fixed syntax, where parsing is unnecessary. Here, we (i) introduce a tunable class of PCFGs in which both the degree of ambiguity and the correlation structure across scales can be controlled; (ii) provide a learning mechanism -- an inference algorithm inspired by the structure of deep convolutional networks -- that links learnability and sample complexity to specific language statistics; and (iii) validate our predictions empirically across deep convolutional and transformer-based architectures. Overall, we propose a unifying framework where correlations at different scales lift local ambiguities, enabling the emergence of hierarchical representations of the data.
Deriving Neural Scaling Laws from the statistics of natural language
Feb 07, 2026Despite the fact that experimental neural scaling laws have substantially guided empirical progress in large-scale machine learning, no existing theory can quantitatively predict the exponents of these important laws for any modern LLM trained on any natural language dataset. We provide the first such theory in the case of data-limited scaling laws. We isolate two key statistical properties of language that alone can predict neural scaling exponents: (i) the decay of pairwise token correlations with time separation between token pairs, and (ii) the decay of the next-token conditional entropy with the length of the conditioning context. We further derive a simple formula in terms of these statistics that predicts data-limited neural scaling exponents from first principles without any free parameters or synthetic data models. Our theory exhibits a remarkable match with experimentally measured neural scaling laws obtained from training GPT-2 and LLaMA style models from scratch on two qualitatively different benchmarks, TinyStories and WikiText.
On the Emergence of Linear Analogies in Word Embeddings
May 24, 2025Models such as Word2Vec and GloVe construct word embeddings based on the co-occurrence probability $P(i,j)$ of words $i$ and $j$ in text corpora. The resulting vectors $W_i$ not only group semantically similar words but also exhibit a striking linear analogy structure -- for example, $W_{\text{king}} - W_{\text{man}} + W_{\text{woman}} \approx W_{\text{queen}}$ -- whose theoretical origin remains unclear. Previous observations indicate that this analogy structure: (i) already emerges in the top eigenvectors of the matrix $M(i,j) = P(i,j)/P(i)P(j)$, (ii) strengthens and then saturates as more eigenvectors of $M (i, j)$, which controls the dimension of the embeddings, are included, (iii) is enhanced when using $\log M(i,j)$ rather than $M(i,j)$, and (iv) persists even when all word pairs involved in a specific analogy relation (e.g., king-queen, man-woman) are removed from the corpus. To explain these phenomena, we introduce a theoretical generative model in which words are defined by binary semantic attributes, and co-occurrence probabilities are derived from attribute-based interactions. This model analytically reproduces the emergence of linear analogy structure and naturally accounts for properties (i)-(iv). It can be viewed as giving fine-grained resolution into the role of each additional embedding dimension. It is robust to various forms of noise and agrees well with co-occurrence statistics measured on Wikipedia and the analogy benchmark introduced by Mikolov et al.
Bigger Isn't Always Memorizing: Early Stopping Overparameterized Diffusion Models
May 22, 2025
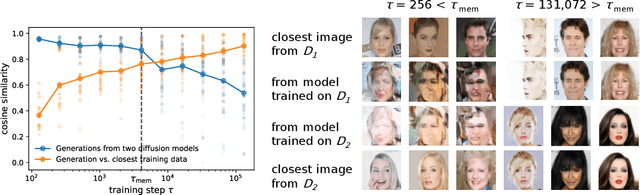
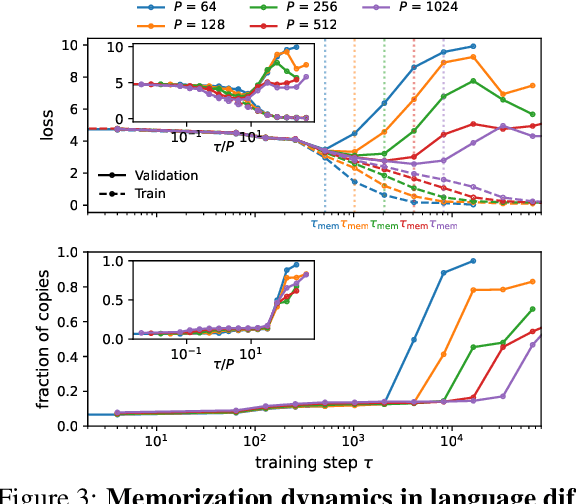

Diffusion probabilistic models have become a cornerstone of modern generative AI, yet the mechanisms underlying their generalization remain poorly understood. In fact, if these models were perfectly minimizing their training loss, they would just generate data belonging to their training set, i.e., memorize, as empirically found in the overparameterized regime. We revisit this view by showing that, in highly overparameterized diffusion models, generalization in natural data domains is progressively achieved during training before the onset of memorization. Our results, ranging from image to language diffusion models, systematically support the empirical law that memorization time is proportional to the dataset size. Generalization vs. memorization is then best understood as a competition between time scales. We show that this phenomenology is recovered in diffusion models learning a simple probabilistic context-free grammar with random rules, where generalization corresponds to the hierarchical acquisition of deeper grammar rules as training time grows, and the generalization cost of early stopping can be characterized. We summarize these results in a phase diagram. Overall, our results support that a principled early-stopping criterion - scaling with dataset size - can effectively optimize generalization while avoiding memorization, with direct implications for hyperparameter transfer and privacy-sensitive applications.
Scaling Laws and Representation Learning in Simple Hierarchical Languages: Transformers vs. Convolutional Architectures
May 11, 2025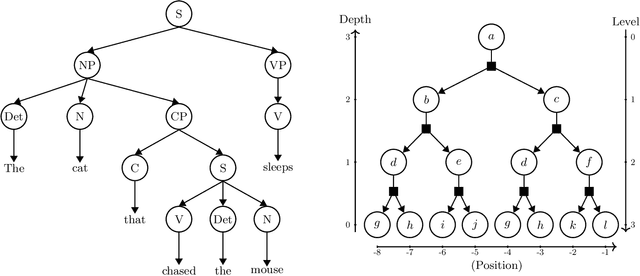
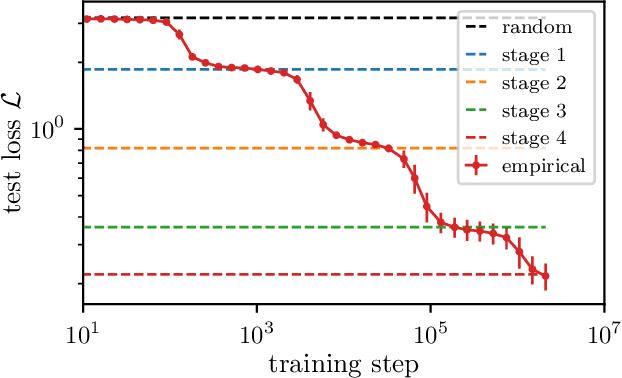
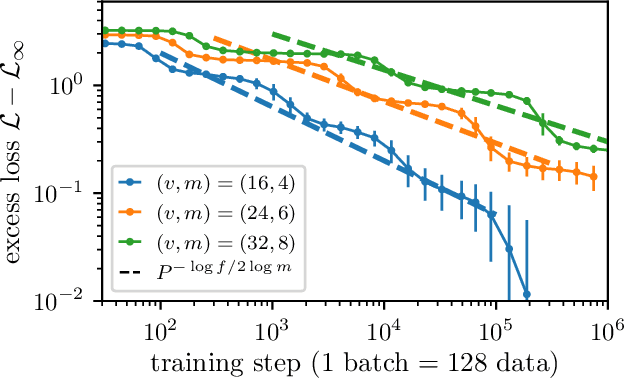
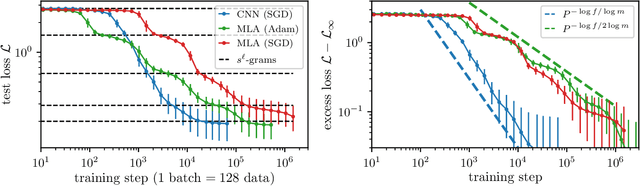
How do neural language models acquire a language's structure when trained for next-token prediction? We address this question by deriving theoretical scaling laws for neural network performance on synthetic datasets generated by the Random Hierarchy Model (RHM) -- an ensemble of probabilistic context-free grammars designed to capture the hierarchical structure of natural language while remaining analytically tractable. Previously, we developed a theory of representation learning based on data correlations that explains how deep learning models capture the hierarchical structure of the data sequentially, one layer at a time. Here, we extend our theoretical framework to account for architectural differences. In particular, we predict and empirically validate that convolutional networks, whose structure aligns with that of the generative process through locality and weight sharing, enjoy a faster scaling of performance compared to transformer models, which rely on global self-attention mechanisms. This finding clarifies the architectural biases underlying neural scaling laws and highlights how representation learning is shaped by the interaction between model architecture and the statistical properties of data.
Learning curves theory for hierarchically compositional data with power-law distributed features
May 11, 2025Recent theories suggest that Neural Scaling Laws arise whenever the task is linearly decomposed into power-law distributed units. Alternatively, scaling laws also emerge when data exhibit a hierarchically compositional structure, as is thought to occur in language and images. To unify these views, we consider classification and next-token prediction tasks based on probabilistic context-free grammars -- probabilistic models that generate data via a hierarchy of production rules. For classification, we show that having power-law distributed production rules results in a power-law learning curve with an exponent depending on the rules' distribution and a large multiplicative constant that depends on the hierarchical structure. By contrast, for next-token prediction, the distribution of production rules controls the local details of the learning curve, but not the exponent describing the large-scale behaviour.