 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProFlow: Learning to Predict Optical Flow
Paper and Code
Jun 03, 2018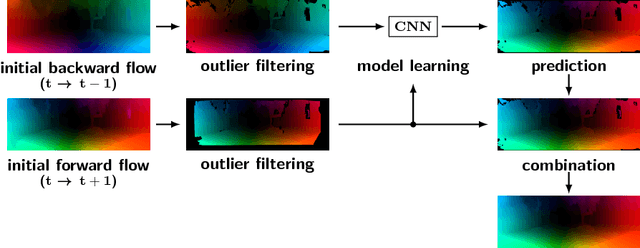
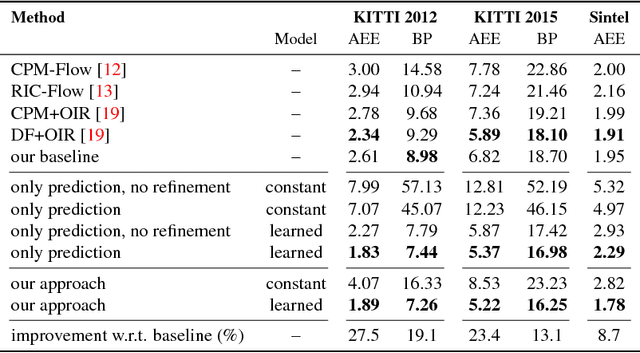
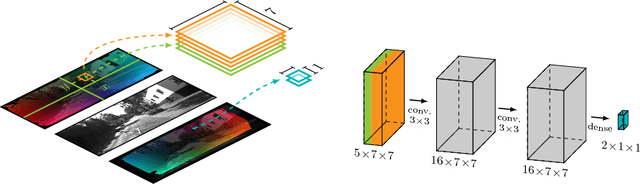
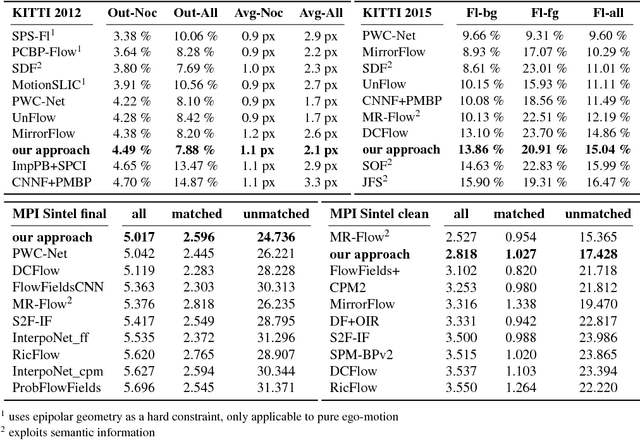
Temporal coherence is a valuable source of information in the context of optical flow estimation. However, finding a suitable motion model to leverage this information is a non-trivial task. In this paper we propose an unsupervised online learning approach based on a convolutional neural network (CNN) that estimates such a motion model individually for each frame. By relating forward and backward motion these learned models not only allow to infer valuable motion information based on the backward flow, they also help to improve the performance at occlusions, where a reliable prediction is particularly useful. Moreover, our learned models are spatially variant and hence allow to estimate non-rigid motion per construction. This, in turns, allows to overcome the major limitation of recent rigidity-based approaches that seek to improve the estimation by incorporating additional stereo/SfM constraints. Experiments demonstrate the usefulness of our new approach. They not only show a consistent improvement of up to 27% for all major benchmarks (KITTI 2012, KITTI 2015, MPI Sintel) compared to a baseline without prediction, they also show top results for the MPI Sintel benchmark -- the one of the three benchmarks that contains the largest amount of non-rigid motion.