 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHelpViz: Automatic Generation of Contextual Visual MobileTutorials from Text-Based Instructions
Paper and Code
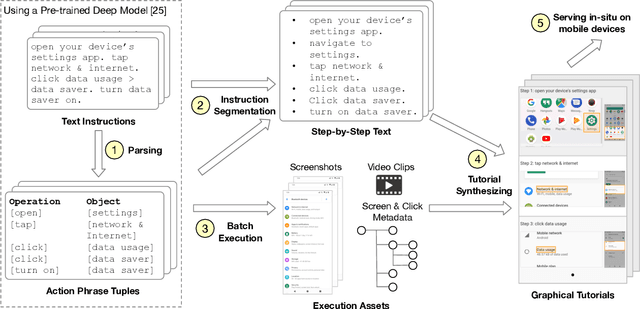

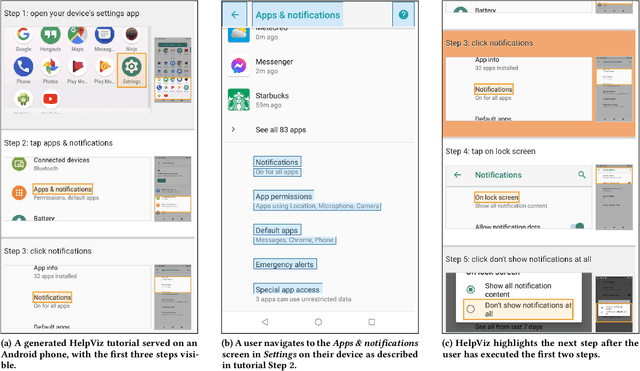

We present HelpViz, a tool for generating contextual visual mobile tutorials from text-based instructions that are abundant on the web. HelpViz transforms text instructions to graphical tutorials in batch, by extracting a sequence of actions from each text instruction through an instruction parsing model, and executing the extracted actions on a simulation infrastructure that manages an array of Android emulators. The automatic execution of each instruction produces a set of graphical and structural assets, including images, videos, and metadata such as clicked elements for each step. HelpViz then synthesizes a tutorial by combining parsed text instructions with the generated assets, and contextualizes the tutorial to user interaction by tracking the user's progress and highlighting the next step. Our experiments with HelpViz indicate that our pipeline improved tutorial execution robustness and that participants preferred tutorials generated by HelpViz over text-based instructions. HelpViz promises a cost-effective approach for generating contextual visual tutorials for mobile interaction at scale.