 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccuracy and Performance Comparison of Video Action Recognition Approaches
Aug 20, 2020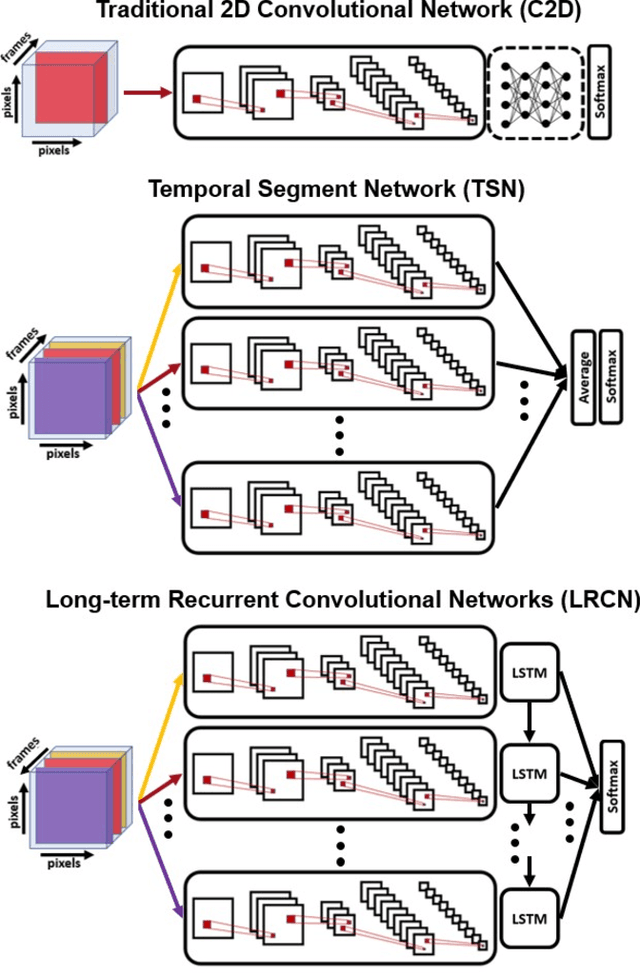
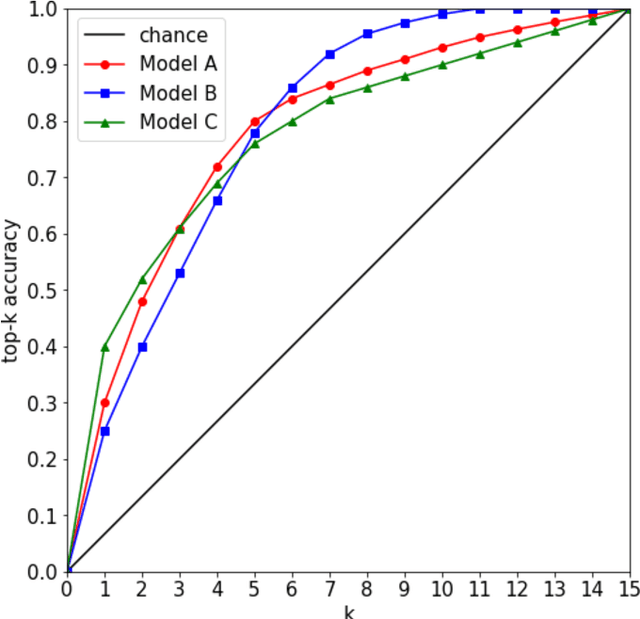
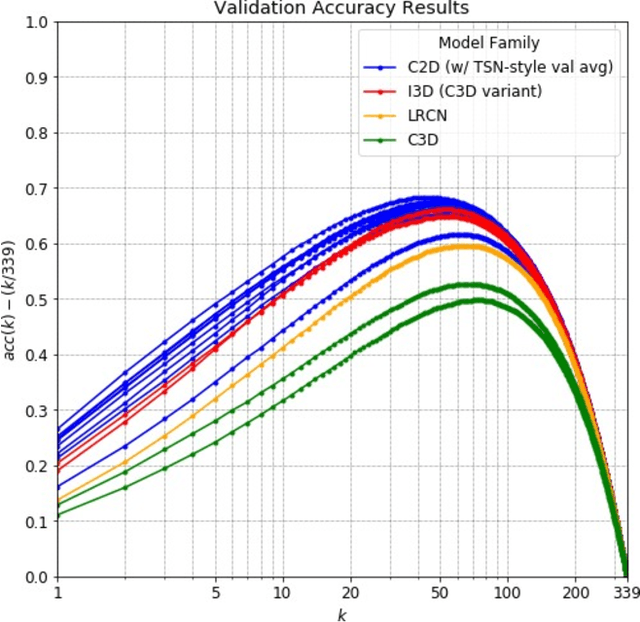
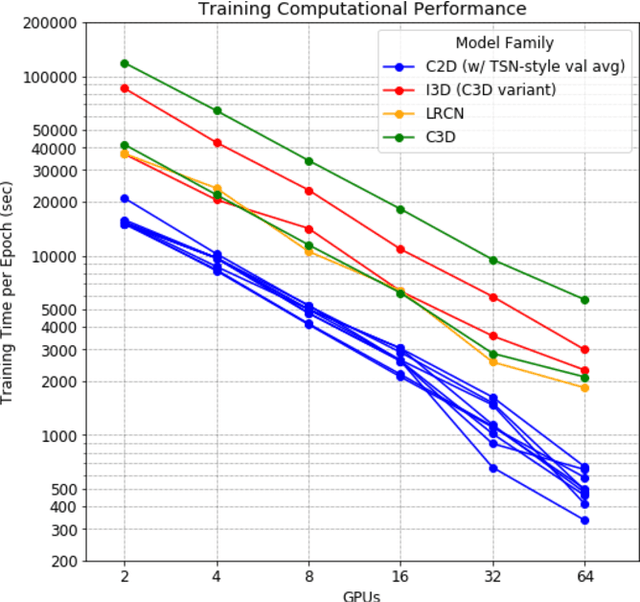
Over the past few years, there has been significant interest in video action recognition systems and models. However, direct comparison of accuracy and computational performance results remain clouded by differing training environments, hardware specifications, hyperparameters, pipelines, and inference methods. This article provides a direct comparison between fourteen off-the-shelf and state-of-the-art models by ensuring consistency in these training characteristics in order to provide readers with a meaningful comparison across different types of video action recognition algorithms. Accuracy of the models is evaluated using standard Top-1 and Top-5 accuracy metrics in addition to a proposed new accuracy metric. Additionally, we compare computational performance of distributed training from two to sixty-four GPUs on a state-of-the-art HPC system.
Benchmarking network fabrics for data distributed training of deep neural networks
Aug 18, 2020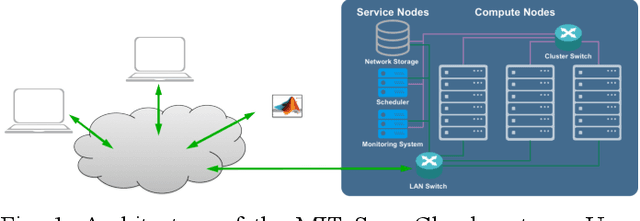
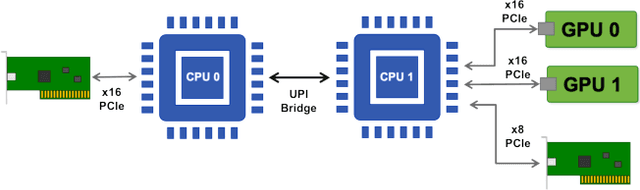
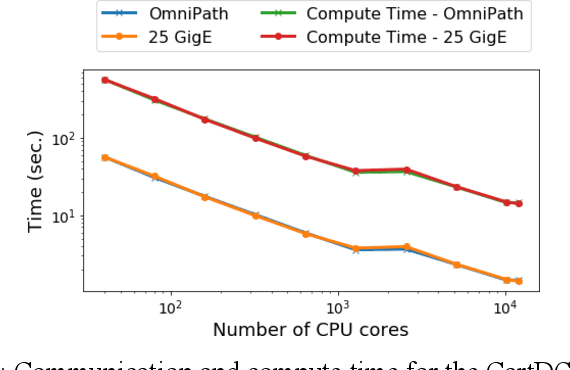

Artificial Intelligence/Machine Learning applications require the training of complex models on large amounts of labelled data. The large computational requirements for training deep models have necessitated the development of new methods for faster training. One such approach is the data parallel approach, where the training data is distributed across multiple compute nodes. This approach is simple to implement and supported by most of the commonly used machine learning frameworks. The data parallel approach leverages MPI for communicating gradients across all nodes. In this paper, we examine the effects of using different physical hardware interconnects and network-related software primitives for enabling data distributed deep learning. We compare the effect of using GPUDirect and NCCL on Ethernet and OmniPath fabrics. Our results show that using Ethernet-based networking in shared HPC systems does not have a significant effect on the training times for commonly used deep neural network architectures or traditional HPC applications such as Computational Fluid Dynamics.