 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Learning of Semantic Relevance in Text to Image Synthesis
Dec 12, 2018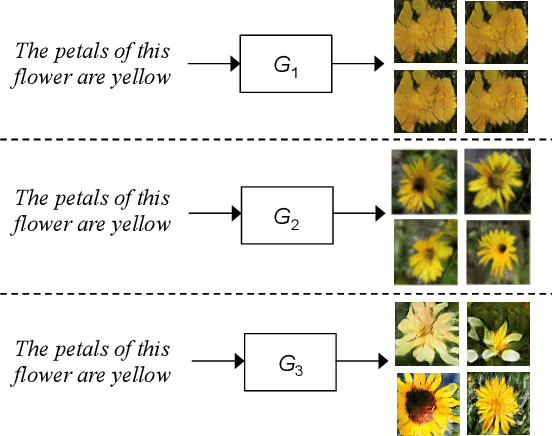
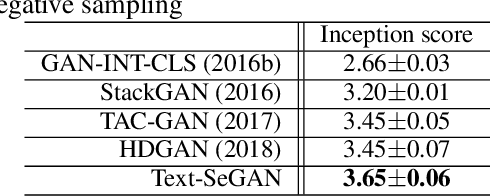
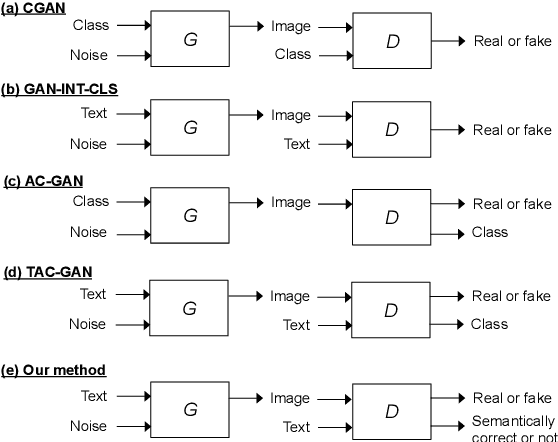
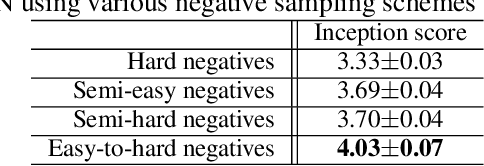
We describe a new approach that improves the training of generative adversarial nets (GANs) for synthesizing diverse images from a text input. Our approach is based on the conditional version of GANs and expands on previous work leveraging an auxiliary task in the discriminator. Our generated images are not limited to certain classes and do not suffer from mode collapse while semantically matching the text input. A key to our training methods is how to form positive and negative training examples with respect to the class label of a given image. Instead of selecting random training examples, we perform negative sampling based on the semantic distance from a positive example in the class. We evaluate our approach using the Oxford-102 flower dataset, adopting the inception score and multi-scale structural similarity index (MS-SSIM) metrics to assess discriminability and diversity of the generated images. The empirical results indicate greater diversity in the generated images, especially when we gradually select more negative training examples closer to a positive example in the semantic space.