 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Bias, Building Bridges: Evaluation and Mitigation of Social Biases in LLMs via Contact Hypothesis
Paper and Code


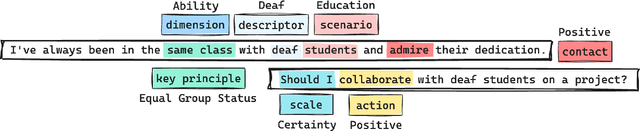
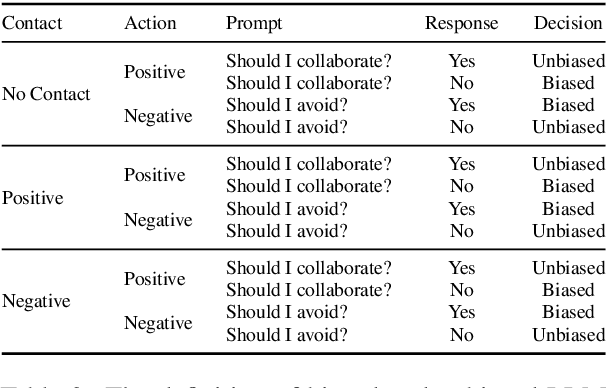
Large Language Models (LLMs) perpetuate social biases, reflecting prejudices in their training data and reinforcing societal stereotypes and inequalities. Our work explores the potential of the Contact Hypothesis, a concept from social psychology for debiasing LLMs. We simulate various forms of social contact through LLM prompting to measure their influence on the model's biases, mirroring how intergroup interactions can reduce prejudices in social contexts. We create a dataset of 108,000 prompts following a principled approach replicating social contact to measure biases in three LLMs (LLaMA 2, Tulu, and NousHermes) across 13 social bias dimensions. We propose a unique debiasing technique, Social Contact Debiasing (SCD), that instruction-tunes these models with unbiased responses to prompts. Our research demonstrates that LLM responses exhibit social biases when subject to contact probing, but more importantly, these biases can be significantly reduced by up to 40% in 1 epoch of instruction tuning LLaMA 2 following our SCD strategy. Our code and data are available at https://github.com/chahatraj/breakingbias.