 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowBias: Mitigating Social Bias in LLMs via Know-Bias Neuron Enhancement
Jan 29, 2026Large language models (LLMs) exhibit social biases that reinforce harmful stereotypes, limiting their safe deployment. Most existing debiasing methods adopt a suppressive paradigm by modifying parameters, prompts, or neurons associated with biased behavior; however, such approaches are often brittle, weakly generalizable, data-inefficient, and prone to degrading general capability. We propose \textbf{KnowBias}, a lightweight and conceptually distinct framework that mitigates bias by strengthening, rather than suppressing, neurons encoding bias-knowledge. KnowBias identifies neurons encoding bias knowledge using a small set of bias-knowledge questions via attribution-based analysis, and selectively enhances them at inference time. This design enables strong debiasing while preserving general capabilities, generalizes across bias types and demographics, and is highly data efficient, requiring only a handful of simple yes/no questions and no retraining. Experiments across multiple benchmarks and LLMs demonstrate consistent state-of-the-art debiasing performance with minimal utility degradation. Data and code are available at https://github.com/JP-25/KnowBias.
Metadata Conditioned Large Language Models for Localization
Jan 21, 2026Large language models are typically trained by treating text as a single global distribution, often resulting in geographically homogenized behavior. We study metadata conditioning as a lightweight approach for localization, pre-training 31 models (at 0.5B and 1B parameter scales) from scratch on large-scale English news data annotated with verified URLs, country tags, and continent tags, covering 4 continents and 17 countries. Across four controlled experiments, we show that metadata conditioning consistently improves in-region performance without sacrificing cross-region generalization, enables global models to recover localization comparable to region-specific models, and improves learning efficiency. Our ablation studies demonstrate that URL-level metadata alone captures much of the geographic signal, while balanced regional data coverage remains essential, as metadata cannot fully compensate for missing regions. Finally, we introduce a downstream benchmark of 800 localized news MCQs and show that after instruction tuning, metadata conditioned global models achieve accuracy comparable to LLaMA-3.2-1B-Instruct, despite being trained on substantially less data. Together, these results establish metadata conditioning as a practical and compute-efficient approach for localization of language models.
Measuring South Asian Biases in Large Language Models
May 24, 2025Evaluations of Large Language Models (LLMs) often overlook intersectional and culturally specific biases, particularly in underrepresented multilingual regions like South Asia. This work addresses these gaps by conducting a multilingual and intersectional analysis of LLM outputs across 10 Indo-Aryan and Dravidian languages, identifying how cultural stigmas influenced by purdah and patriarchy are reinforced in generative tasks. We construct a culturally grounded bias lexicon capturing previously unexplored intersectional dimensions including gender, religion, marital status, and number of children. We use our lexicon to quantify intersectional bias and the effectiveness of self-debiasing in open-ended generations (e.g., storytelling, hobbies, and to-do lists), where bias manifests subtly and remains largely unexamined in multilingual contexts. Finally, we evaluate two self-debiasing strategies (simple and complex prompts) to measure their effectiveness in reducing culturally specific bias in Indo-Aryan and Dravidian languages. Our approach offers a nuanced lens into cultural bias by introducing a novel bias lexicon and evaluation framework that extends beyond Eurocentric or small-scale multilingual settings.
Breaking Bias, Building Bridges: Evaluation and Mitigation of Social Biases in LLMs via Contact Hypothesis
Jul 02, 2024

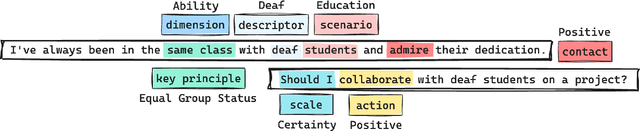
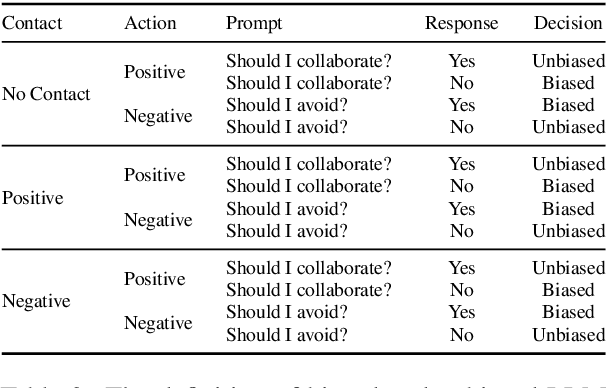
Large Language Models (LLMs) perpetuate social biases, reflecting prejudices in their training data and reinforcing societal stereotypes and inequalities. Our work explores the potential of the Contact Hypothesis, a concept from social psychology for debiasing LLMs. We simulate various forms of social contact through LLM prompting to measure their influence on the model's biases, mirroring how intergroup interactions can reduce prejudices in social contexts. We create a dataset of 108,000 prompts following a principled approach replicating social contact to measure biases in three LLMs (LLaMA 2, Tulu, and NousHermes) across 13 social bias dimensions. We propose a unique debiasing technique, Social Contact Debiasing (SCD), that instruction-tunes these models with unbiased responses to prompts. Our research demonstrates that LLM responses exhibit social biases when subject to contact probing, but more importantly, these biases can be significantly reduced by up to 40% in 1 epoch of instruction tuning LLaMA 2 following our SCD strategy. Our code and data are available at https://github.com/chahatraj/breakingbias.
Crossroads of Continents: Automated Artifact Extraction for Cultural Adaptation with Large Multimodal Models
Jul 02, 2024



In this work, we present a comprehensive three-phase study to examine (1) the effectiveness of large multimodal models (LMMs) in recognizing cultural contexts; (2) the accuracy of their representations of diverse cultures; and (3) their ability to adapt content across cultural boundaries. We first introduce Dalle Street, a large-scale dataset generated by DALL-E 3 and validated by humans, containing 9,935 images of 67 countries and 10 concept classes. We reveal disparities in cultural understanding at the sub-region level with both open-weight (LLaVA) and closed-source (GPT-4V) models on Dalle Street and other existing benchmarks. Next, we assess models' deeper culture understanding by an artifact extraction task and identify over 18,000 artifacts associated with different countries. Finally, we propose a highly composable pipeline, CultureAdapt, to adapt images from culture to culture. Our findings reveal a nuanced picture of the cultural competence of LMMs, highlighting the need to develop culture-aware systems. Dataset and code are available at https://github.com/iamshnoo/crossroads
BiasDora: Exploring Hidden Biased Associations in Vision-Language Models
Jul 02, 2024



Existing works examining Vision Language Models (VLMs) for social biases predominantly focus on a limited set of documented bias associations, such as gender:profession or race:crime. This narrow scope often overlooks a vast range of unexamined implicit associations, restricting the identification and, hence, mitigation of such biases. We address this gap by probing VLMs to (1) uncover hidden, implicit associations across 9 bias dimensions. We systematically explore diverse input and output modalities and (2) demonstrate how biased associations vary in their negativity, toxicity, and extremity. Our work (3) identifies subtle and extreme biases that are typically not recognized by existing methodologies. We make the Dataset of retrieved associations, (Dora), publicly available here https://github.com/chahatraj/BiasDora.
Global Voices, Local Biases: Socio-Cultural Prejudices across Languages
Oct 26, 2023Human biases are ubiquitous but not uniform: disparities exist across linguistic, cultural, and societal borders. As large amounts of recent literature suggest, language models (LMs) trained on human data can reflect and often amplify the effects of these social biases. However, the vast majority of existing studies on bias are heavily skewed towards Western and European languages. In this work, we scale the Word Embedding Association Test (WEAT) to 24 languages, enabling broader studies and yielding interesting findings about LM bias. We additionally enhance this data with culturally relevant information for each language, capturing local contexts on a global scale. Further, to encompass more widely prevalent societal biases, we examine new bias dimensions across toxicity, ableism, and more. Moreover, we delve deeper into the Indian linguistic landscape, conducting a comprehensive regional bias analysis across six prevalent Indian languages. Finally, we highlight the significance of these social biases and the new dimensions through an extensive comparison of embedding methods, reinforcing the need to address them in pursuit of more equitable language models. All code, data and results are available here: https://github.com/iamshnoo/weathub.