 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSpatial: Visual-Language Reasoning for Social Robot Navigation through Efficient Spatial Reasoning Learning
Mar 10, 2025We present a novel method, AutoSpatial, an efficient approach with structured spatial grounding to enhance VLMs' spatial reasoning. By combining minimal manual supervision with large-scale Visual Question-Answering (VQA) pairs auto-labeling, our approach tackles the challenge of VLMs' limited spatial understanding in social navigation tasks. By applying a hierarchical two-round VQA strategy during training, AutoSpatial achieves both global and detailed understanding of scenarios, demonstrating more accurate spatial perception, movement prediction, Chain of Thought (CoT) reasoning, final action, and explanation compared to other SOTA approaches. These five components are essential for comprehensive social navigation reasoning. Our approach was evaluated using both expert systems (GPT-4o, Gemini 2.0 Flash, and Claude 3.5 Sonnet) that provided cross-validation scores and human evaluators who assigned relative rankings to compare model performances across four key aspects. Augmented by the enhanced spatial reasoning capabilities, AutoSpatial demonstrates substantial improvements by averaged cross-validation score from expert systems in: perception & prediction (up to 10.71%), reasoning (up to 16.26%), action (up to 20.50%), and explanation (up to 18.73%) compared to baseline models trained only on manually annotated data.
Learning to Solve Soft-Constrained Vehicle Routing Problems with Lagrangian Relaxation
Jul 29, 2022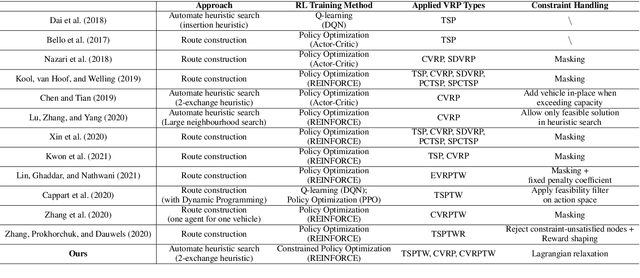

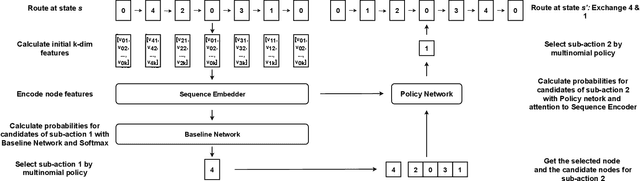
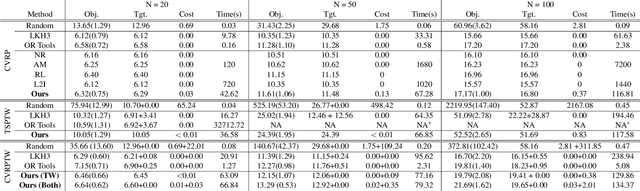
Vehicle Routing Problems (VRPs) in real-world applications often come with various constraints, therefore bring additional computational challenges to exact solution methods or heuristic search approaches. The recent idea to learn heuristic move patterns from sample data has become increasingly promising to reduce solution developing costs. However, using learning-based approaches to address more types of constrained VRP remains a challenge. The difficulty lies in controlling for constraint violations while searching for optimal solutions. To overcome this challenge, we propose a Reinforcement Learning based method to solve soft-constrained VRPs by incorporating the Lagrangian relaxation technique and using constrained policy optimization. We apply the method on three common types of VRPs, the Travelling Salesman Problem with Time Windows (TSPTW), the Capacitated VRP (CVRP) and the Capacitated VRP with Time Windows (CVRPTW), to show the generalizability of the proposed method. After comparing to existing RL-based methods and open-source heuristic solvers, we demonstrate its competitive performance in finding solutions with a good balance in travel distance, constraint violations and inference speed.