 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAT: Interpretable Concept-based Taylor Additive Models
Jun 27, 2024As an emerging interpretable technique, Generalized Additive Models (GAMs) adopt neural networks to individually learn non-linear functions for each feature, which are then combined through a linear model for final predictions. Although GAMs can explain deep neural networks (DNNs) at the feature level, they require large numbers of model parameters and are prone to overfitting, making them hard to train and scale. Additionally, in real-world datasets with many features, the interpretability of feature-based explanations diminishes for humans. To tackle these issues, recent research has shifted towards concept-based interpretable methods. These approaches try to integrate concept learning as an intermediate step before making predictions, explaining the predictions in terms of human-understandable concepts. However, these methods require domain experts to extensively label concepts with relevant names and their ground-truth values. In response, we propose CAT, a novel interpretable Concept-bAsed Taylor additive model to simply this process. CAT does not have to require domain experts to annotate concepts and their ground-truth values. Instead, it only requires users to simply categorize input features into broad groups, which can be easily accomplished through a quick metadata review. Specifically, CAT first embeds each group of input features into one-dimensional high-level concept representation, and then feeds the concept representations into a new white-box Taylor Neural Network (TaylorNet). The TaylorNet aims to learn the non-linear relationship between the inputs and outputs using polynomials. Evaluation results across multiple benchmarks demonstrate that CAT can outperform or compete with the baselines while reducing the need of extensive model parameters. Importantly, it can explain model predictions through high-level concepts that human can understand.
General-Purpose Multi-Modal OOD Detection Framework
Jul 24, 2023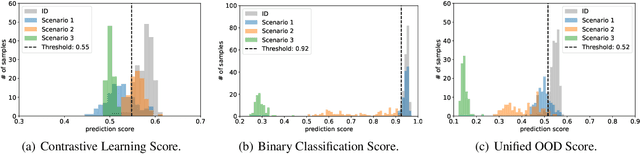

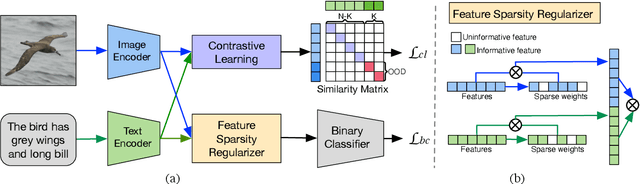

Out-of-distribution (OOD) detection identifies test samples that differ from the training data, which is critical to ensuring the safety and reliability of machine learning (ML) systems. While a plethora of methods have been developed to detect uni-modal OOD samples, only a few have focused on multi-modal OOD detection. Current contrastive learning-based methods primarily study multi-modal OOD detection in a scenario where both a given image and its corresponding textual description come from a new domain. However, real-world deployments of ML systems may face more anomaly scenarios caused by multiple factors like sensor faults, bad weather, and environmental changes. Hence, the goal of this work is to simultaneously detect from multiple different OOD scenarios in a fine-grained manner. To reach this goal, we propose a general-purpose weakly-supervised OOD detection framework, called WOOD, that combines a binary classifier and a contrastive learning component to reap the benefits of both. In order to better distinguish the latent representations of in-distribution (ID) and OOD samples, we adopt the Hinge loss to constrain their similarity. Furthermore, we develop a new scoring metric to integrate the prediction results from both the binary classifier and contrastive learning for identifying OOD samples. We evaluate the proposed WOOD model on multiple real-world datasets, and the experimental results demonstrate that the WOOD model outperforms the state-of-the-art methods for multi-modal OOD detection. Importantly, our approach is able to achieve high accuracy in OOD detection in three different OOD scenarios simultaneously. The source code will be made publicly available upon publication.
Scaling New Peaks: A Viewership-centric Approach to Automated Content Curation
Aug 09, 2021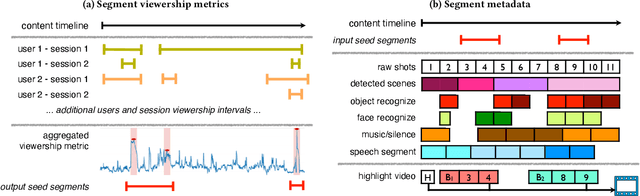
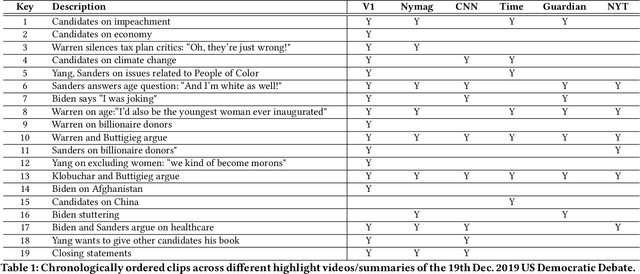
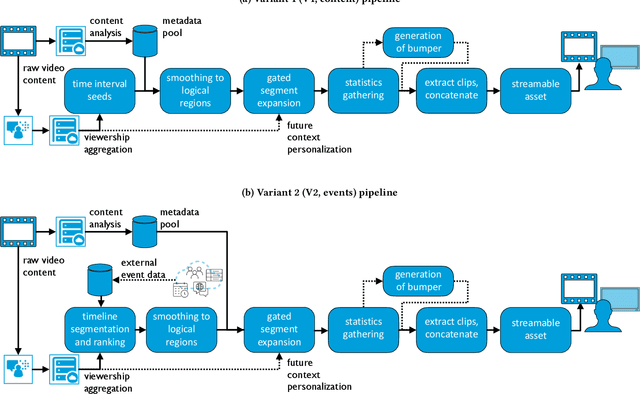
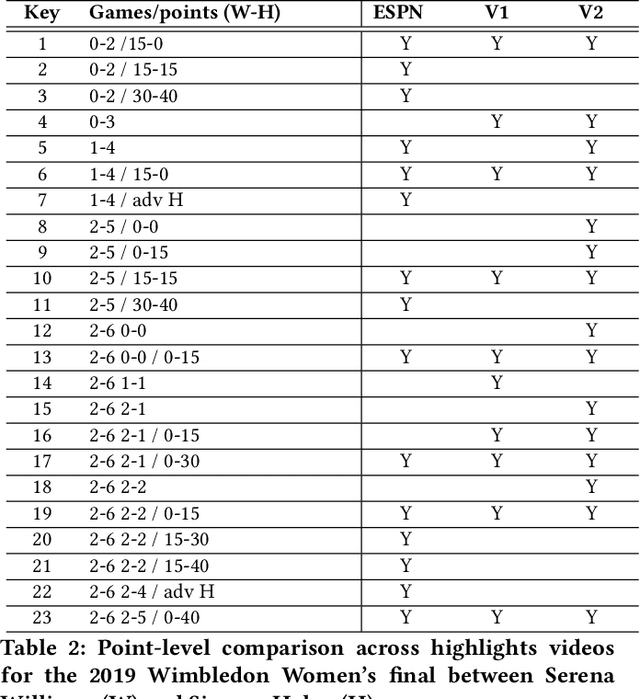
Summarizing video content is important for video streaming services to engage the user in a limited time span. To this end, current methods involve manual curation or using passive interest cues to annotate potential high-interest segments to form the basis of summarized videos, and are costly and unreliable. We propose a viewership-driven, automated method that accommodates a range of segment identification goals. Using satellite television viewership data as a source of ground truth for viewer interest, we apply statistical anomaly detection on a timeline of viewership metrics to identify 'seed' segments of high viewer interest. These segments are post-processed using empirical rules and several sources of content metadata, e.g. shot boundaries, adding in personalization aspects to produce the final highlights video. To demonstrate the flexibility of our approach, we present two case studies, on the United States Democratic Presidential Debate on 19th December 2019, and Wimbledon Women's Final 2019. We perform qualitative comparisons with their publicly available highlights, as well as early vs. late viewership comparisons for insights into possible media and social influence on viewing behavior.