 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOGScene3D: Incremental Open-Vocabulary 3D Gaussian Scene Graph Mapping for Scene Understanding
Mar 17, 2026Open-vocabulary scene understanding is crucial for robotic applications, enabling robots to comprehend complex 3D environmental contexts and supporting various downstream tasks such as navigation and manipulation. However, existing methods require pre-built complete 3D semantic maps to construct scene graphs for scene understanding, which limits their applicability in robotic scenarios where environments are explored incrementally. To address this challenge, we propose OGScene3D, an open-vocabulary scene understanding system that achieves accurate 3D semantic mapping and scene graph construction incrementally. Our system employs a confidence-based Gaussian semantic representation that jointly models semantic predictions and their reliability, enabling robust scene modeling. Building on this representation, we introduce a hierarchical 3D semantic optimization strategy that achieves semantic consistency through local correspondence establishment and global refinement, thereby constructing globally consistent semantic maps. Moreover, we design a long-term global optimization method that leverages temporal memory of historical observations to enhance semantic predictions. By integrating 2D-3D semantic consistency with Gaussian rendering contribution, this method continuously refines the semantic understanding of the entire scene.Furthermore, we develop a progressive graph construction approach that dynamically creates and updates both nodes and semantic relationships, allowing continuous updating of the 3D scene graphs. Extensive experiments on widely used datasets and real-world scenes demonstrate the effectiveness of our OGScene3D on open-vocabulary scene understanding.
Multimodal Spatial Language Maps for Robot Navigation and Manipulation
Jun 07, 2025Grounding language to a navigating agent's observations can leverage pretrained multimodal foundation models to match perceptions to object or event descriptions. However, previous approaches remain disconnected from environment mapping, lack the spatial precision of geometric maps, or neglect additional modality information beyond vision. To address this, we propose multimodal spatial language maps as a spatial map representation that fuses pretrained multimodal features with a 3D reconstruction of the environment. We build these maps autonomously using standard exploration. We present two instances of our maps, which are visual-language maps (VLMaps) and their extension to audio-visual-language maps (AVLMaps) obtained by adding audio information. When combined with large language models (LLMs), VLMaps can (i) translate natural language commands into open-vocabulary spatial goals (e.g., "in between the sofa and TV") directly localized in the map, and (ii) be shared across different robot embodiments to generate tailored obstacle maps on demand. Building upon the capabilities above, AVLMaps extend VLMaps by introducing a unified 3D spatial representation integrating audio, visual, and language cues through the fusion of features from pretrained multimodal foundation models. This enables robots to ground multimodal goal queries (e.g., text, images, or audio snippets) to spatial locations for navigation. Additionally, the incorporation of diverse sensory inputs significantly enhances goal disambiguation in ambiguous environments. Experiments in simulation and real-world settings demonstrate that our multimodal spatial language maps enable zero-shot spatial and multimodal goal navigation and improve recall by 50% in ambiguous scenarios. These capabilities extend to mobile robots and tabletop manipulators, supporting navigation and interaction guided by visual, audio, and spatial cues.
BYE: Build Your Encoder with One Sequence of Exploration Data for Long-Term Dynamic Scene Understanding
Dec 03, 2024Dynamic scene understanding remains a persistent challenge in robotic applications. Early dynamic mapping methods focused on mitigating the negative influence of short-term dynamic objects on camera motion estimation by masking or tracking specific categories, which often fall short in adapting to long-term scene changes. Recent efforts address object association in long-term dynamic environments using neural networks trained on synthetic datasets, but they still rely on predefined object shapes and categories. Other methods incorporate visual, geometric, or semantic heuristics for the association but often lack robustness. In this work, we introduce BYE, a class-agnostic, per-scene point cloud encoder that removes the need for predefined categories, shape priors, or extensive association datasets. Trained on only a single sequence of exploration data, BYE can efficiently perform object association in dynamically changing scenes. We further propose an ensembling scheme combining the semantic strengths of Vision Language Models (VLMs) with the scene-specific expertise of BYE, achieving a 7% improvement and a 95% success rate in object association tasks. Code and dataset are available at https://byencoder.github.io.
Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation
Mar 26, 2024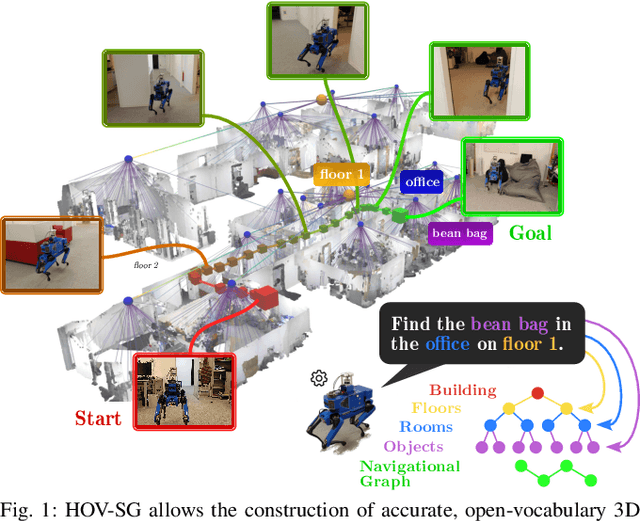



Recent open-vocabulary robot mapping methods enrich dense geometric maps with pre-trained visual-language features. While these maps allow for the prediction of point-wise saliency maps when queried for a certain language concept, large-scale environments and abstract queries beyond the object level still pose a considerable hurdle, ultimately limiting language-grounded robotic navigation. In this work, we present HOV-SG, a hierarchical open-vocabulary 3D scene graph mapping approach for language-grounded robot navigation. Leveraging open-vocabulary vision foundation models, we first obtain state-of-the-art open-vocabulary segment-level maps in 3D and subsequently construct a 3D scene graph hierarchy consisting of floor, room, and object concepts, each enriched with open-vocabulary features. Our approach is able to represent multi-story buildings and allows robotic traversal of those using a cross-floor Voronoi graph. HOV-SG is evaluated on three distinct datasets and surpasses previous baselines in open-vocabulary semantic accuracy on the object, room, and floor level while producing a 75% reduction in representation size compared to dense open-vocabulary maps. In order to prove the efficacy and generalization capabilities of HOV-SG, we showcase successful long-horizon language-conditioned robot navigation within real-world multi-storage environments. We provide code and trial video data at http://hovsg.github.io/.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Audio Visual Language Maps for Robot Navigation
Mar 27, 2023While interacting in the world is a multi-sensory experience, many robots continue to predominantly rely on visual perception to map and navigate in their environments. In this work, we propose Audio-Visual-Language Maps (AVLMaps), a unified 3D spatial map representation for storing cross-modal information from audio, visual, and language cues. AVLMaps integrate the open-vocabulary capabilities of multimodal foundation models pre-trained on Internet-scale data by fusing their features into a centralized 3D voxel grid. In the context of navigation, we show that AVLMaps enable robot systems to index goals in the map based on multimodal queries, e.g., textual descriptions, images, or audio snippets of landmarks. In particular, the addition of audio information enables robots to more reliably disambiguate goal locations. Extensive experiments in simulation show that AVLMaps enable zero-shot multimodal goal navigation from multimodal prompts and provide 50% better recall in ambiguous scenarios. These capabilities extend to mobile robots in the real world - navigating to landmarks referring to visual, audio, and spatial concepts. Videos and code are available at: https://avlmaps.github.io.
Visual Language Maps for Robot Navigation
Oct 17, 2022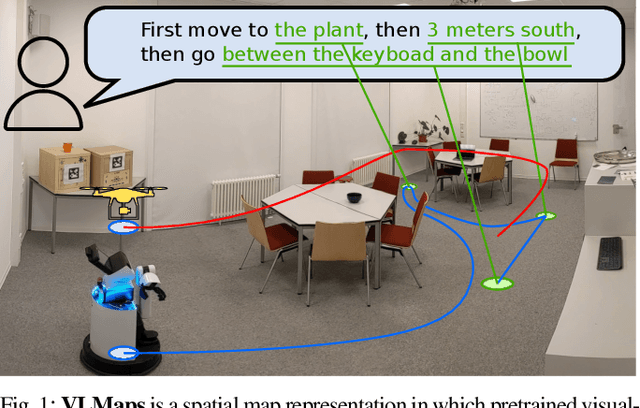

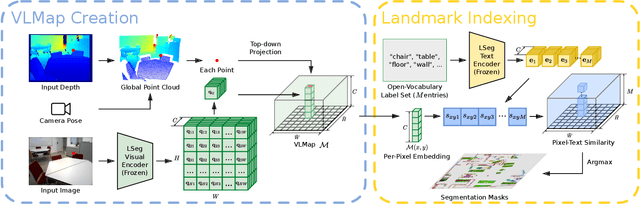

Grounding language to the visual observations of a navigating agent can be performed using off-the-shelf visual-language models pretrained on Internet-scale data (e.g., image captions). While this is useful for matching images to natural language descriptions of object goals, it remains disjoint from the process of mapping the environment, so that it lacks the spatial precision of classic geometric maps. To address this problem, we propose VLMaps, a spatial map representation that directly fuses pretrained visual-language features with a 3D reconstruction of the physical world. VLMaps can be autonomously built from video feed on robots using standard exploration approaches and enables natural language indexing of the map without additional labeled data. Specifically, when combined with large language models (LLMs), VLMaps can be used to (i) translate natural language commands into a sequence of open-vocabulary navigation goals (which, beyond prior work, can be spatial by construction, e.g., "in between the sofa and TV" or "three meters to the right of the chair") directly localized in the map, and (ii) can be shared among multiple robots with different embodiments to generate new obstacle maps on-the-fly (by using a list of obstacle categories). Extensive experiments carried out in simulated and real world environments show that VLMaps enable navigation according to more complex language instructions than existing methods. Videos are available at https://vlmaps.github.io.