 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikiformer: Pre-training with Structured Information of Wikipedia for Ad-hoc Retrieval
Jan 01, 2024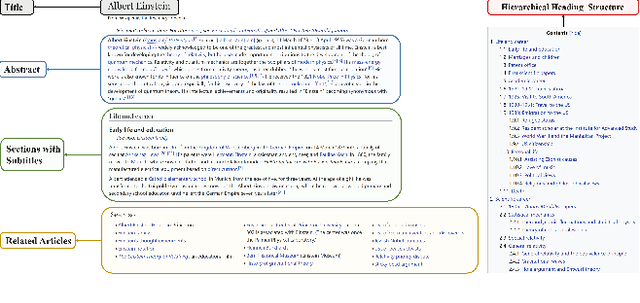
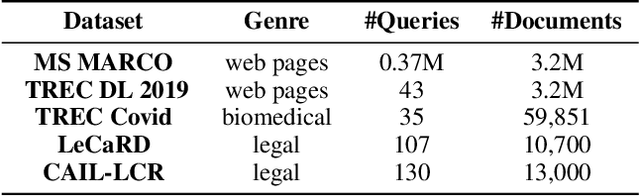
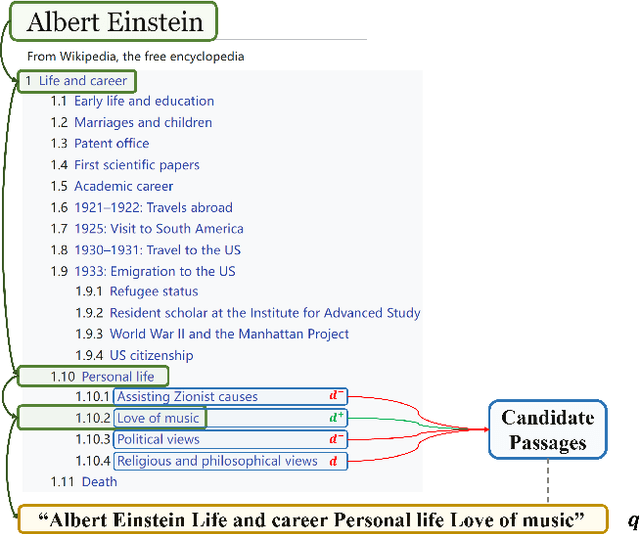
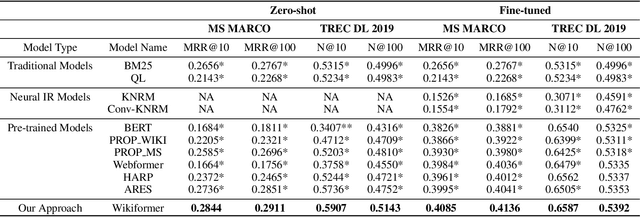
With the development of deep learning and natural language processing techniques, pre-trained language models have been widely used to solve information retrieval (IR) problems. Benefiting from the pre-training and fine-tuning paradigm, these models achieve state-of-the-art performance. In previous works, plain texts in Wikipedia have been widely used in the pre-training stage. However, the rich structured information in Wikipedia, such as the titles, abstracts, hierarchical heading (multi-level title) structure, relationship between articles, references, hyperlink structures, and the writing organizations, has not been fully explored. In this paper, we devise four pre-training objectives tailored for IR tasks based on the structured knowledge of Wikipedia. Compared to existing pre-training methods, our approach can better capture the semantic knowledge in the training corpus by leveraging the human-edited structured data from Wikipedia. Experimental results on multiple IR benchmark datasets show the superior performance of our model in both zero-shot and fine-tuning settings compared to existing strong retrieval baselines. Besides, experimental results in biomedical and legal domains demonstrate that our approach achieves better performance in vertical domains compared to previous models, especially in scenarios where long text similarity matching is needed.
THUIR2 at NTCIR-16 Session Search Task
Jul 01, 2023



Our team(THUIR2) participated in both FOSS and POSS subtasks of the NTCIR-161 Session Search (SS) Task. This paper describes our approaches and results. In the FOSS subtask, we submit five runs using learning-to-rank and fine-tuned pre-trained language models. We fine-tuned the pre-trained language model with ad-hoc data and session information and assembled them by a learning-to-rank method. The assembled model achieves the best performance among all participants in the preliminary evaluation. In the POSS subtask, we used an assembled model which also achieves the best performance in the preliminary evaluation.
T2Ranking: A large-scale Chinese Benchmark for Passage Ranking
Apr 07, 2023



Passage ranking involves two stages: passage retrieval and passage re-ranking, which are important and challenging topics for both academics and industries in the area of Information Retrieval (IR). However, the commonly-used datasets for passage ranking usually focus on the English language. For non-English scenarios, such as Chinese, the existing datasets are limited in terms of data scale, fine-grained relevance annotation and false negative issues. To address this problem, we introduce T2Ranking, a large-scale Chinese benchmark for passage ranking. T2Ranking comprises more than 300K queries and over 2M unique passages from real-world search engines. Expert annotators are recruited to provide 4-level graded relevance scores (fine-grained) for query-passage pairs instead of binary relevance judgments (coarse-grained). To ease the false negative issues, more passages with higher diversities are considered when performing relevance annotations, especially in the test set, to ensure a more accurate evaluation. Apart from the textual query and passage data, other auxiliary resources are also provided, such as query types and XML files of documents which passages are generated from, to facilitate further studies. To evaluate the dataset, commonly used ranking models are implemented and tested on T2Ranking as baselines. The experimental results show that T2Ranking is challenging and there is still scope for improvement. The full data and all codes are available at https://github.com/THUIR/T2Ranking/
Multi-Feature Integration for Perception-Dependent Examination-Bias Estimation
Feb 27, 2023Eliminating examination bias accurately is pivotal to apply click-through data to train an unbiased ranking model. However, most examination-bias estimators are limited to the hypothesis of Position-Based Model (PBM), which supposes that the calculation of examination bias only depends on the rank of the document. Recently, although some works introduce information such as clicks in the same query list and contextual information when calculating the examination bias, they still do not model the impact of document representation on search engine result pages (SERPs) that seriously affects one's perception of document relevance to a query when examining. Therefore, we propose a Multi-Feature Integration Model (MFIM) where the examination bias depends on the representation of document except the rank of it. Furthermore, we mine a key factor slipoff counts that can indirectly reflects the influence of all perception-bias factors. Real world experiments on Baidu-ULTR dataset demonstrate the superior effectiveness and robustness of the new approach. The source code is available at \href{https://github.com/lixsh6/Tencent_wsdm_cup2023/tree/main/pytorch_unbias}{https://github.com/lixsh6/Tencent\_wsdm\_cup2023}
Pretraining De-Biased Language Model with Large-scale Click Logs for Document Ranking
Feb 27, 2023Pre-trained language models have achieved great success in various large-scale information retrieval tasks. However, most of pretraining tasks are based on counterfeit retrieval data where the query produced by the tailored rule is assumed as the user's issued query on the given document or passage. Therefore, we explore to use large-scale click logs to pretrain a language model instead of replying on the simulated queries. Specifically, we propose to use user behavior features to pretrain a debiased language model for document ranking. Extensive experiments on Baidu desensitization click logs validate the effectiveness of our method. Our team on WSDM Cup 2023 Pre-training for Web Search won the 1st place with a Discounted Cumulative Gain @ 10 (DCG@10) score of 12.16525 on the final leaderboard.
Pre-training Methods in Information Retrieval
Nov 27, 2021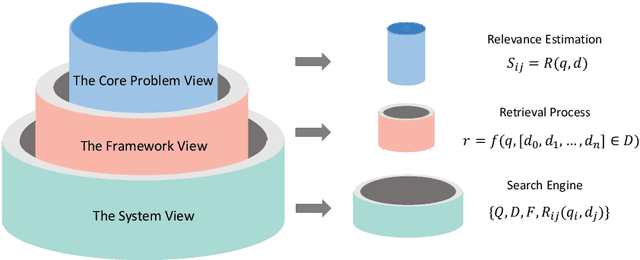
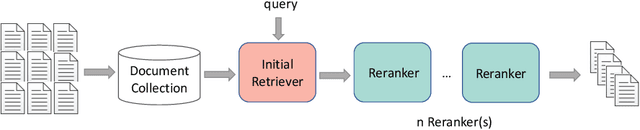
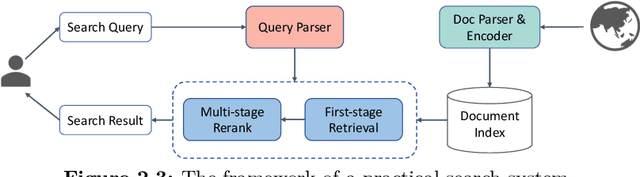

The core of information retrieval (IR) is to identify relevant information from large-scale resources and return it as a ranked list to respond to user's information need. Recently, the resurgence of deep learning has greatly advanced this field and leads to a hot topic named NeuIR (i.e., neural information retrieval), especially the paradigm of pre-training methods (PTMs). Owing to sophisticated pre-training objectives and huge model size, pre-trained models can learn universal language representations from massive textual data, which are beneficial to the ranking task of IR. Since there have been a large number of works dedicating to the application of PTMs in IR, we believe it is the right time to summarize the current status, learn from existing methods, and gain some insights for future development. In this survey, we present an overview of PTMs applied in different components of IR system, including the retrieval component, the re-ranking component, and other components. In addition, we also introduce PTMs specifically designed for IR, and summarize available datasets as well as benchmark leaderboards. Moreover, we discuss some open challenges and envision some promising directions, with the hope of inspiring more works on these topics for future research.