 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData, Not Model: Explaining Bias toward LLM Texts in Neural Retrievers
Apr 07, 2026Recent studies show that neural retrievers often display source bias, favoring passages generated by LLMs over human-written ones, even when both are semantically similar. This bias has been considered an inherent flaw of retrievers, raising concerns about the fairness and reliability of modern information access systems. Our work challenges this view by showing that source bias stems from supervision in retrieval datasets rather than the models themselves. We found that non-semantic differences, like fluency and term specificity, exist between positive and negative documents, mirroring differences between LLM and human texts. In the embedding space, the bias direction from negatives to positives aligns with the direction from human-written to LLM-generated texts. We theoretically show that retrievers inevitably absorb the artifact imbalances in the training data during contrastive learning, which leads to their preferences over LLM texts. To mitigate the effect, we propose two approaches: 1) reducing artifact differences in training data and 2) adjusting LLM text vectors by removing their projection on the bias vector. Both methods substantially reduce source bias. We hope our study alleviates some concerns regarding LLM-generated texts in information access systems.
Reconstructing Content via Collaborative Attention to Improve Multimodal Embedding Quality
Mar 02, 2026Multimodal embedding models, rooted in multimodal large language models (MLLMs), have yielded significant performance improvements across diverse tasks such as retrieval and classification. However, most existing approaches rely heavily on large-scale contrastive learning, with limited exploration of how the architectural and training paradigms of MLLMs affect embedding quality. While effective for generation, the causal attention and next-token prediction paradigm of MLLMs does not explicitly encourage the formation of globally compact representations, limiting their effectiveness as multimodal embedding backbones. To address this, we propose CoCoA, a Content reconstruction pre-training paradigm based on Collaborative Attention for multimodal embedding optimization. Specifically, we restructure the attention flow and introduce an EOS-based reconstruction task, encouraging the model to reconstruct input from the corresponding <EOS> embeddings. This drives the multimodal model to compress the semantic information of the input into the <EOS> token, laying the foundations for subsequent contrastive learning. Extensive experiments on MMEB-V1 demonstrate that CoCoA built upon Qwen2-VL and Qwen2.5-VL significantly improves embedding quality. Results validate that content reconstruction serves as an effective strategy to maximize the value of existing data, enabling multimodal embedding models generate compact and informative representations, raising their performance ceiling.
How Do LLM-Generated Texts Impact Term-Based Retrieval Models?
Aug 25, 2025



As more content generated by large language models (LLMs) floods into the Internet, information retrieval (IR) systems now face the challenge of distinguishing and handling a blend of human-authored and machine-generated texts. Recent studies suggest that neural retrievers may exhibit a preferential inclination toward LLM-generated content, while classic term-based retrievers like BM25 tend to favor human-written documents. This paper investigates the influence of LLM-generated content on term-based retrieval models, which are valued for their efficiency and robust generalization across domains. Our linguistic analysis reveals that LLM-generated texts exhibit smoother high-frequency and steeper low-frequency Zipf slopes, higher term specificity, and greater document-level diversity. These traits are aligned with LLMs being trained to optimize reader experience through diverse and precise expressions. Our study further explores whether term-based retrieval models demonstrate source bias, concluding that these models prioritize documents whose term distributions closely correspond to those of the queries, rather than displaying an inherent source bias. This work provides a foundation for understanding and addressing potential biases in term-based IR systems managing mixed-source content.
CAME: Competitively Learning a Mixture-of-Experts Model for First-stage Retrieval
Nov 06, 2023



The first-stage retrieval aims to retrieve a subset of candidate documents from a huge collection both effectively and efficiently. Since various matching patterns can exist between queries and relevant documents, previous work tries to combine multiple retrieval models to find as many relevant results as possible. The constructed ensembles, whether learned independently or jointly, do not care which component model is more suitable to an instance during training. Thus, they cannot fully exploit the capabilities of different types of retrieval models in identifying diverse relevance patterns. Motivated by this observation, in this paper, we propose a Mixture-of-Experts (MoE) model consisting of representative matching experts and a novel competitive learning mechanism to let the experts develop and enhance their expertise during training. Specifically, our MoE model shares the bottom layers to learn common semantic representations and uses differently structured upper layers to represent various types of retrieval experts. Our competitive learning mechanism has two stages: (1) a standardized learning stage to train the experts equally to develop their capabilities to conduct relevance matching; (2) a specialized learning stage where the experts compete with each other on every training instance and get rewards and updates according to their performance to enhance their expertise on certain types of samples. Experimental results on three retrieval benchmark datasets show that our method significantly outperforms the state-of-the-art baselines.
L^2R: Lifelong Learning for First-stage Retrieval with Backward-Compatible Representations
Aug 22, 2023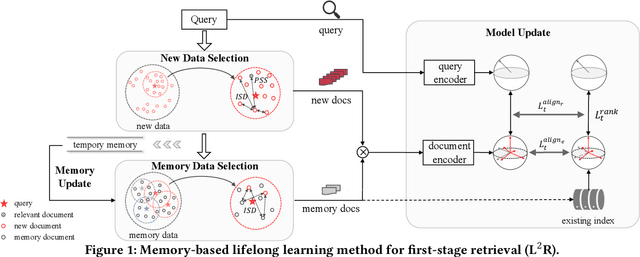
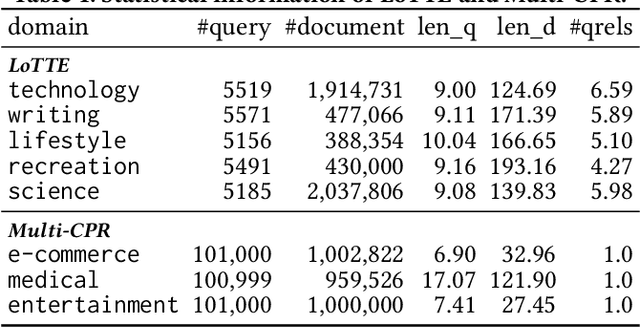
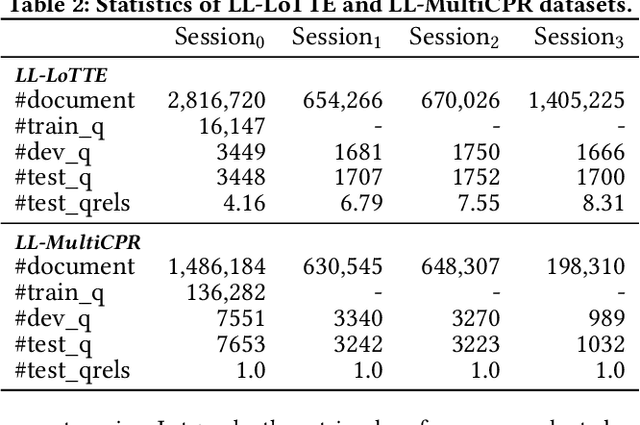
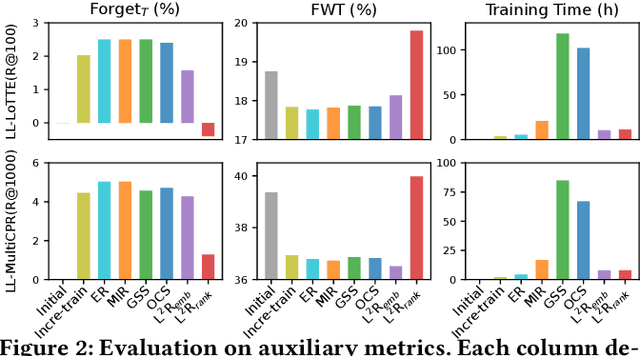
First-stage retrieval is a critical task that aims to retrieve relevant document candidates from a large-scale collection. While existing retrieval models have achieved impressive performance, they are mostly studied on static data sets, ignoring that in the real-world, the data on the Web is continuously growing with potential distribution drift. Consequently, retrievers trained on static old data may not suit new-coming data well and inevitably produce sub-optimal results. In this work, we study lifelong learning for first-stage retrieval, especially focusing on the setting where the emerging documents are unlabeled since relevance annotation is expensive and may not keep up with data emergence. Under this setting, we aim to develop model updating with two goals: (1) to effectively adapt to the evolving distribution with the unlabeled new-coming data, and (2) to avoid re-inferring all embeddings of old documents to efficiently update the index each time the model is updated. We first formalize the task and then propose a novel Lifelong Learning method for the first-stage Retrieval, namely L^2R. L^2R adopts the typical memory mechanism for lifelong learning, and incorporates two crucial components: (1) selecting diverse support negatives for model training and memory updating for effective model adaptation, and (2) a ranking alignment objective to ensure the backward-compatibility of representations to save the cost of index rebuilding without hurting the model performance. For evaluation, we construct two new benchmarks from LoTTE and Multi-CPR datasets to simulate the document distribution drift in realistic retrieval scenarios. Extensive experiments show that L^2R significantly outperforms competitive lifelong learning baselines.
Hard Negatives or False Negatives: Correcting Pooling Bias in Training Neural Ranking Models
Sep 12, 2022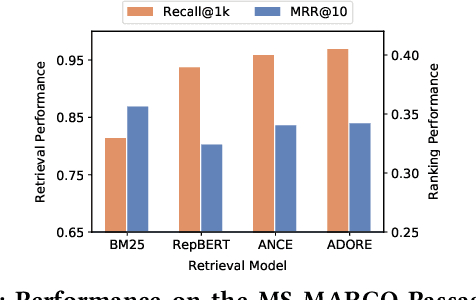
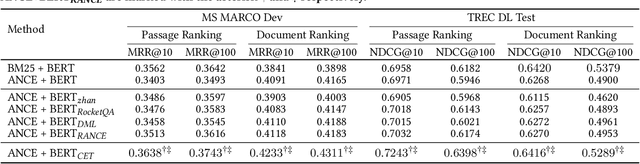
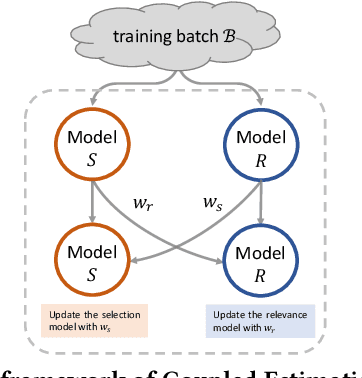
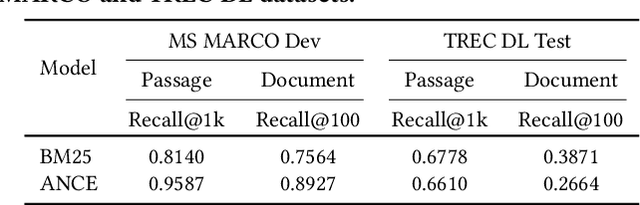
Neural ranking models (NRMs) have become one of the most important techniques in information retrieval (IR). Due to the limitation of relevance labels, the training of NRMs heavily relies on negative sampling over unlabeled data. In general machine learning scenarios, it has shown that training with hard negatives (i.e., samples that are close to positives) could lead to better performance. Surprisingly, we find opposite results from our empirical studies in IR. When sampling top-ranked results (excluding the labeled positives) as negatives from a stronger retriever, the performance of the learned NRM becomes even worse. Based on our investigation, the superficial reason is that there are more false negatives (i.e., unlabeled positives) in the top-ranked results with a stronger retriever, which may hurt the training process; The root is the existence of pooling bias in the dataset constructing process, where annotators only judge and label very few samples selected by some basic retrievers. Therefore, in principle, we can formulate the false negative issue in training NRMs as learning from labeled datasets with pooling bias. To solve this problem, we propose a novel Coupled Estimation Technique (CET) that learns both a relevance model and a selection model simultaneously to correct the pooling bias for training NRMs. Empirical results on three retrieval benchmarks show that NRMs trained with our technique can achieve significant gains on ranking effectiveness against other baseline strategies.
Pre-training Methods in Information Retrieval
Nov 27, 2021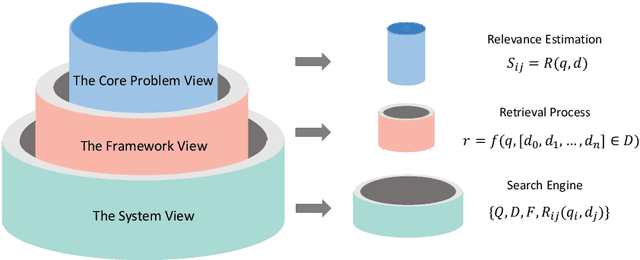
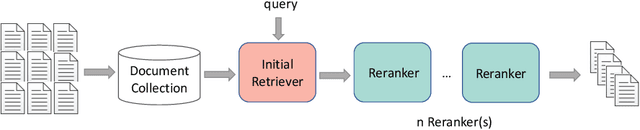

The core of information retrieval (IR) is to identify relevant information from large-scale resources and return it as a ranked list to respond to user's information need. Recently, the resurgence of deep learning has greatly advanced this field and leads to a hot topic named NeuIR (i.e., neural information retrieval), especially the paradigm of pre-training methods (PTMs). Owing to sophisticated pre-training objectives and huge model size, pre-trained models can learn universal language representations from massive textual data, which are beneficial to the ranking task of IR. Since there have been a large number of works dedicating to the application of PTMs in IR, we believe it is the right time to summarize the current status, learn from existing methods, and gain some insights for future development. In this survey, we present an overview of PTMs applied in different components of IR system, including the retrieval component, the re-ranking component, and other components. In addition, we also introduce PTMs specifically designed for IR, and summarize available datasets as well as benchmark leaderboards. Moreover, we discuss some open challenges and envision some promising directions, with the hope of inspiring more works on these topics for future research.
A Discriminative Semantic Ranker for Question Retrieval
Jul 18, 2021

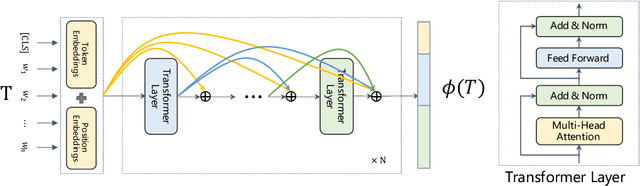
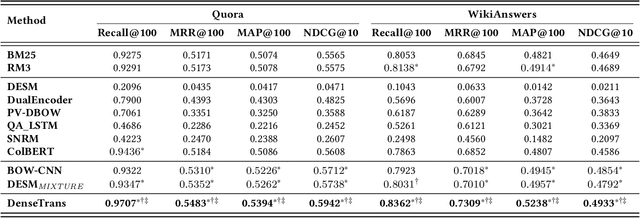
Similar question retrieval is a core task in community-based question answering (CQA) services. To balance the effectiveness and efficiency, the question retrieval system is typically implemented as multi-stage rankers: The first-stage ranker aims to recall potentially relevant questions from a large repository, and the latter stages attempt to re-rank the retrieved results. Most existing works on question retrieval mainly focused on the re-ranking stages, leaving the first-stage ranker to some traditional term-based methods. However, term-based methods often suffer from the vocabulary mismatch problem, especially on short texts, which may block the re-rankers from relevant questions at the very beginning. An alternative is to employ embedding-based methods for the first-stage ranker, which compress texts into dense vectors to enhance the semantic matching. However, these methods often lose the discriminative power as term-based methods, thus introduce noise during retrieval and hurt the recall performance. In this work, we aim to tackle the dilemma of the first-stage ranker, and propose a discriminative semantic ranker, namely DenseTrans, for high-recall retrieval. Specifically, DenseTrans is a densely connected Transformer, which learns semantic embeddings for texts based on Transformer layers. Meanwhile, DenseTrans promotes low-level features through dense connections to keep the discriminative power of the learned representations. DenseTrans is inspired by DenseNet in computer vision (CV), but poses a new way to use the dense connectivity which is totally different from its original design purpose. Experimental results over two question retrieval benchmark datasets show that our model can obtain significant gain on recall against strong term-based methods as well as state-of-the-art embedding-based methods.
Semantic Models for the First-stage Retrieval: A Comprehensive Review
Mar 12, 2021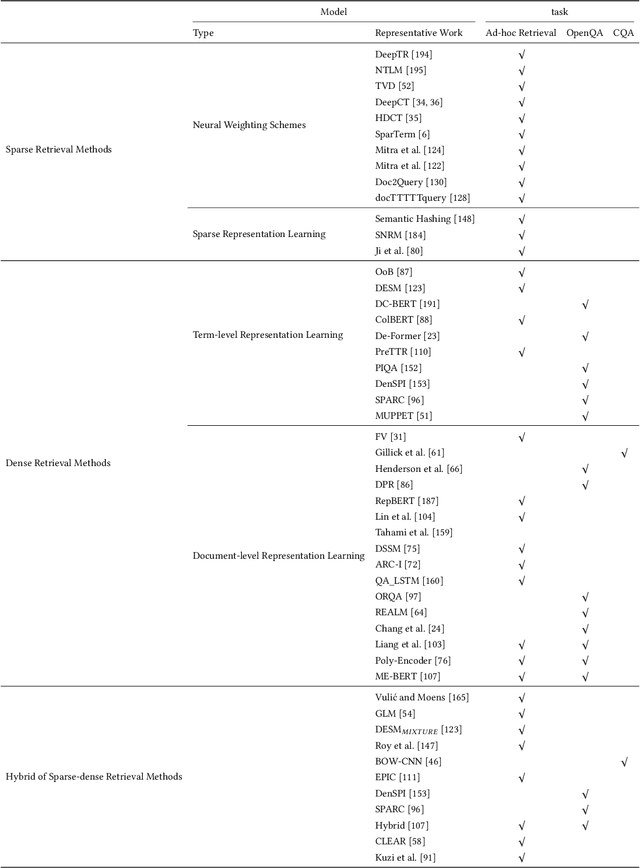
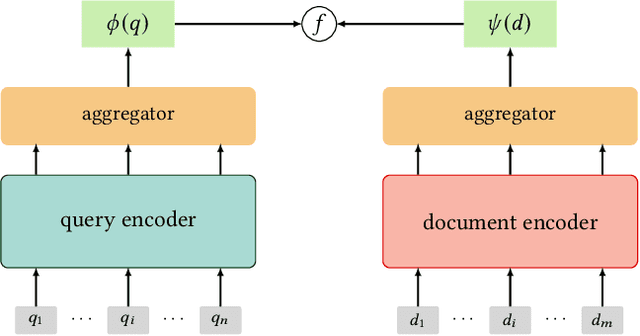

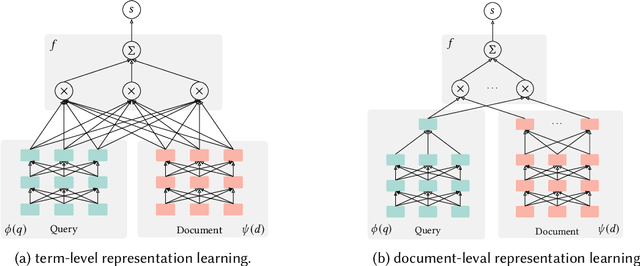
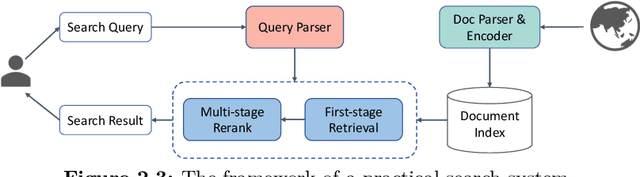
Multi-stage ranking pipelines have been a practical solution in modern search systems, where the first-stage retrieval is to return a subset of candidate documents, and the latter stages attempt to re-rank those candidates. Unlike the re-ranking stages going through quick technique shifts during the past decades, the first-stage retrieval has long been dominated by classical term-based models. Unfortunately, these models suffer from the vocabulary mismatch problem, which may block the re-ranking stages from relevant documents at the very beginning. Therefore, it has been a long-term desire to build semantic models for the first-stage retrieval that can achieve high recall efficiently. Recently, we have witnessed an explosive growth of research interests on the first-stage semantic retrieval models. We believe it is the right time to survey the current status, learn from existing methods, and gain some insights for future development. In this paper, we describe the current landscape of semantic retrieval models from three major paradigms, paying special attention to recent neural-based methods. We review the benchmark datasets, optimization methods and evaluation metrics, and summarize the state-of-the-art models. We also discuss the unresolved challenges and suggest potentially promising directions for future work.