 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-guided Unsupervised Rhetorical Parsing for Text Summarization
Paper and Code


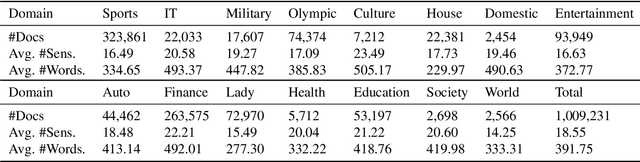
Automatic text summarization (ATS) has recently achieved impressive performance thanks to recent advances in deep learning and the availability of large-scale corpora. To make the summarization results more faithful, this paper presents an unsupervised approach that combines rhetorical structure theory, deep neural model and domain knowledge concern for ATS. This architecture mainly contains three components: domain knowledge base construction based on representation learning, attentional encoder-decoder model for rhetorical parsing and subroutine-based model for text summarization. Domain knowledge can be effectively used for unsupervised rhetorical parsing thus rhetorical structure trees for each document can be derived. In the unsupervised rhetorical parsing module, the idea of translation was adopted to alleviate the problem of data scarcity. The subroutine-based summarization model purely depends on the derived rhetorical structure trees and can generate content-balanced results. To evaluate the summary results without golden standard, we proposed an unsupervised evaluation metric, whose hyper-parameters were tuned by supervised learning. Experimental results show that, on a large-scale Chinese dataset, our proposed approach can obtain comparable performances compared with existing methods.