 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinaFace: Strong but Simple Baseline for Face Detection
Dec 02, 2020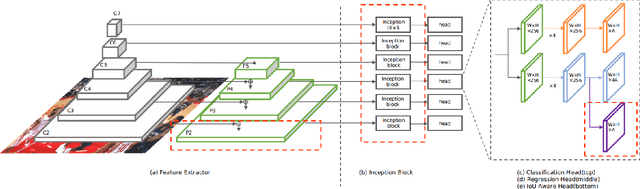
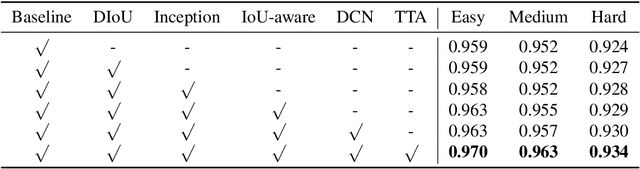
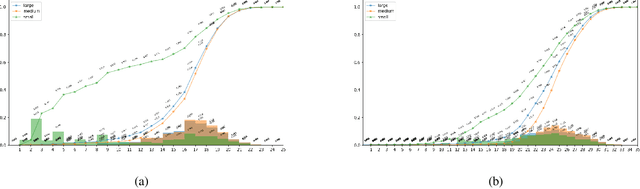
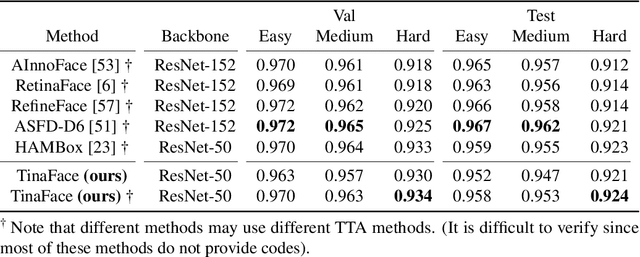
Face detection has received intensive attention in recent years. Many works present lots of special methods for face detection from different perspectives like model architecture, data augmentation, label assignment and etc., which make the overall algorithm and system become more and more complex. In this paper, we point out that \textbf{there is no gap between face detection and generic object detection}. Then we provide a strong but simple baseline method to deal with face detection named TinaFace. We use ResNet-50 \cite{he2016deep} as backbone, and all modules and techniques in TinaFace are constructed on existing modules, easily implemented and based on generic object detection. On the hard test set of the most popular and challenging face detection benchmark WIDER FACE \cite{yang2016wider}, with single-model and single-scale, our TinaFace achieves 92.1\% average precision (AP), which exceeds most of the recent face detectors with larger backbone. And after using test time augmentation (TTA), our TinaFace outperforms the current state-of-the-art method and achieves 92.4\% AP. The code will be available at \url{https://github.com/Media-Smart/vedadet}.
A Solution to Product detection in Densely Packed Scenes
Jul 23, 2020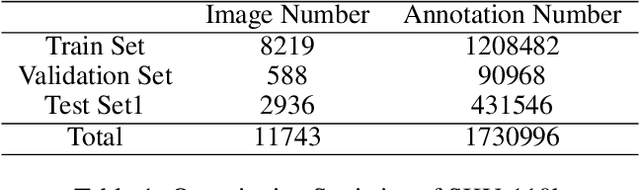
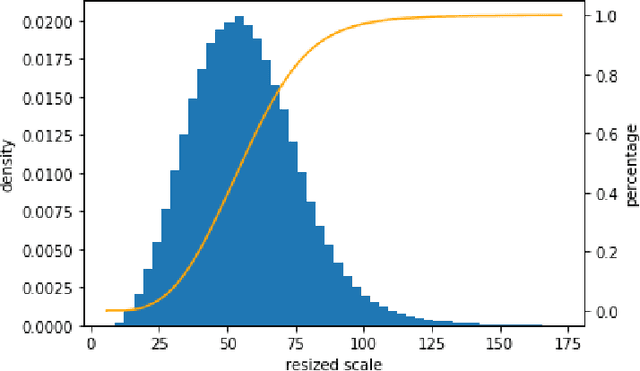


This work is a solution to densely packed scenes dataset SKU-110k. Our work is modified from cascade R-CNN. To solve the problem, we proposed a random crop strategy to ensure both the sampling rate and input scale is relatively sufficient as a contrast to the regular random crop. And we adopted some of trick and optimized the hyper-parameters. To grasp the essential feature of the densely packed scenes, we analysis the stages of a detector and investigate the bottleneck which limits the performance. As a result, our method obtains 58.7 mAP on test set of SKU-110k.