 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGB Stream Is Enough for Temporal Action Detection
Paper and Code
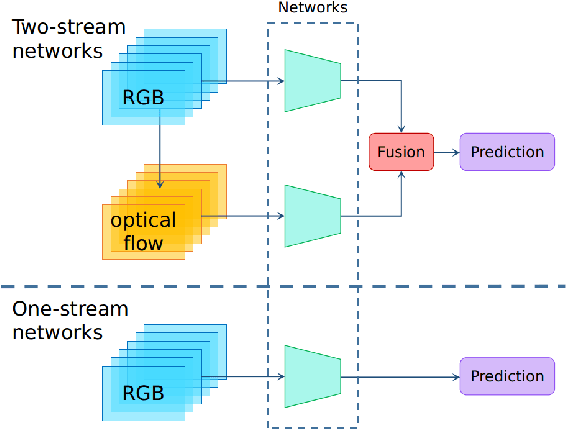
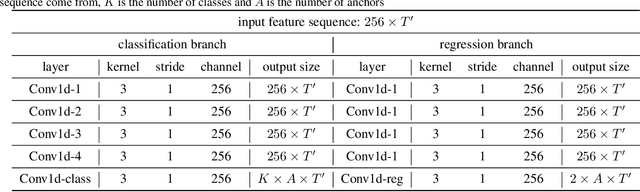
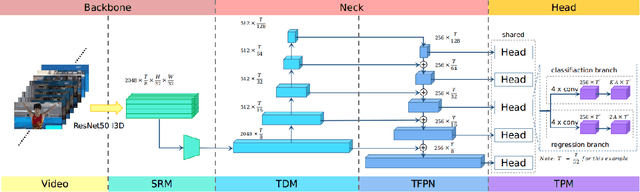
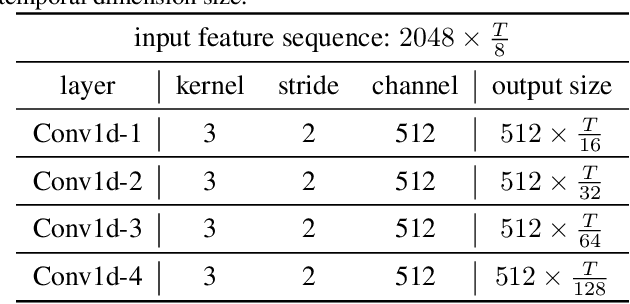
State-of-the-art temporal action detectors to date are based on two-stream input including RGB frames and optical flow. Although combining RGB frames and optical flow boosts performance significantly, optical flow is a hand-designed representation which not only requires heavy computation, but also makes it methodologically unsatisfactory that two-stream methods are often not learned end-to-end jointly with the flow. In this paper, we argue that optical flow is dispensable in high-accuracy temporal action detection and image level data augmentation (ILDA) is the key solution to avoid performance degradation when optical flow is removed. To evaluate the effectiveness of ILDA, we design a simple yet efficient one-stage temporal action detector based on single RGB stream named DaoTAD. Our results show that when trained with ILDA, DaoTAD has comparable accuracy with all existing state-of-the-art two-stream detectors while surpassing the inference speed of previous methods by a large margin and the inference speed is astounding 6668 fps on GeForce GTX 1080 Ti. Code is available at \url{https://github.com/Media-Smart/vedatad}.