 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEVFusion4D: Learning LiDAR-Camera Fusion Under Bird's-Eye-View via Cross-Modality Guidance and Temporal Aggregation
Mar 30, 2023



Integrating LiDAR and Camera information into Bird's-Eye-View (BEV) has become an essential topic for 3D object detection in autonomous driving. Existing methods mostly adopt an independent dual-branch framework to generate LiDAR and camera BEV, then perform an adaptive modality fusion. Since point clouds provide more accurate localization and geometry information, they could serve as a reliable spatial prior to acquiring relevant semantic information from the images. Therefore, we design a LiDAR-Guided View Transformer (LGVT) to effectively obtain the camera representation in BEV space and thus benefit the whole dual-branch fusion system. LGVT takes camera BEV as the primitive semantic query, repeatedly leveraging the spatial cue of LiDAR BEV for extracting image features across multiple camera views. Moreover, we extend our framework into the temporal domain with our proposed Temporal Deformable Alignment (TDA) module, which aims to aggregate BEV features from multiple historical frames. Including these two modules, our framework dubbed BEVFusion4D achieves state-of-the-art results in 3D object detection, with 72.0% mAP and 73.5% NDS on the nuScenes validation set, and 73.3% mAP and 74.7% NDS on nuScenes test set, respectively.
WS-3D-Lane: Weakly Supervised 3D Lane Detection With 2D Lane Labels
Sep 23, 2022
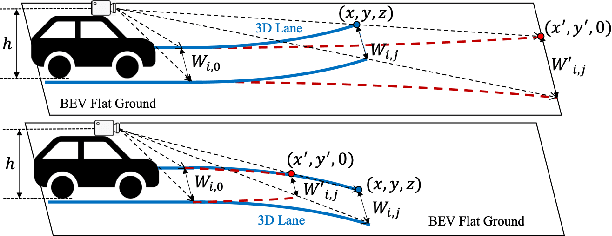
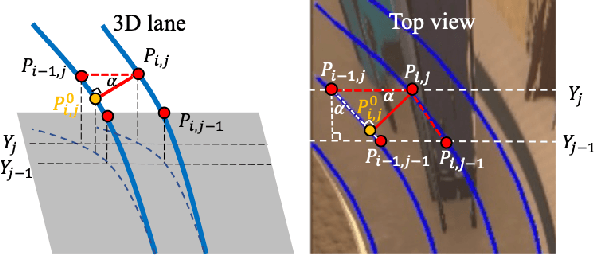

Compared to 2D lanes, real 3D lane data is difficult to collect accurately. In this paper, we propose a novel method for training 3D lanes with only 2D lane labels, called weakly supervised 3D lane detection WS-3D-Lane. By assumptions of constant lane width and equal height on adjacent lanes, we indirectly supervise 3D lane heights in the training. To overcome the problem of the dynamic change of the camera pitch during data collection, a camera pitch self-calibration method is proposed. In anchor representation, we propose a double-layer anchor with a improved non-maximum suppression (NMS) method, which enables the anchor-based method to predict two lane lines that are close. Experiments are conducted on the base of 3D-LaneNet under two supervision methods. Under weakly supervised setting, our WS-3D-Lane outperforms previous 3D-LaneNet: F-score rises to 92.3% on Apollo 3D synthetic dataset, and F1 rises to 74.5% on ONCE-3DLanes. Meanwhile, WS-3D-Lane in purely supervised setting makes more increments and outperforms state-of-the-art. To the best of our knowledge, WS-3D-Lane is the first try of 3D lane detection under weakly supervised setting.