 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering the effects of model initialization on deep model generalization: A study with adult and pediatric Chest X-ray images
Sep 20, 2023Model initialization techniques are vital for improving the performance and reliability of deep learning models in medical computer vision applications. While much literature exists on non-medical images, the impacts on medical images, particularly chest X-rays (CXRs) are less understood. Addressing this gap, our study explores three deep model initialization techniques: Cold-start, Warm-start, and Shrink and Perturb start, focusing on adult and pediatric populations. We specifically focus on scenarios with periodically arriving data for training, thereby embracing the real-world scenarios of ongoing data influx and the need for model updates. We evaluate these models for generalizability against external adult and pediatric CXR datasets. We also propose novel ensemble methods: F-score-weighted Sequential Least-Squares Quadratic Programming (F-SLSQP) and Attention-Guided Ensembles with Learnable Fuzzy Softmax to aggregate weight parameters from multiple models to capitalize on their collective knowledge and complementary representations. We perform statistical significance tests with 95% confidence intervals and p-values to analyze model performance. Our evaluations indicate models initialized with ImageNet-pre-trained weights demonstrate superior generalizability over randomly initialized counterparts, contradicting some findings for non-medical images. Notably, ImageNet-pretrained models exhibit consistent performance during internal and external testing across different training scenarios. Weight-level ensembles of these models show significantly higher recall (p<0.05) during testing compared to individual models. Thus, our study accentuates the benefits of ImageNet-pretrained weight initialization, especially when used with weight-level ensembles, for creating robust and generalizable deep learning solutions.
Semantically Redundant Training Data Removal and Deep Model Classification Performance: A Study with Chest X-rays
Sep 18, 2023Deep learning (DL) has demonstrated its innate capacity to independently learn hierarchical features from complex and multi-dimensional data. A common understanding is that its performance scales up with the amount of training data. Another data attribute is the inherent variety. It follows, therefore, that semantic redundancy, which is the presence of similar or repetitive information, would tend to lower performance and limit generalizability to unseen data. In medical imaging data, semantic redundancy can occur due to the presence of multiple images that have highly similar presentations for the disease of interest. Further, the common use of augmentation methods to generate variety in DL training may be limiting performance when applied to semantically redundant data. We propose an entropy-based sample scoring approach to identify and remove semantically redundant training data. We demonstrate using the publicly available NIH chest X-ray dataset that the model trained on the resulting informative subset of training data significantly outperforms the model trained on the full training set, during both internal (recall: 0.7164 vs 0.6597, p<0.05) and external testing (recall: 0.3185 vs 0.2589, p<0.05). Our findings emphasize the importance of information-oriented training sample selection as opposed to the conventional practice of using all available training data.
Does image resolution impact chest X-ray based fine-grained Tuberculosis-consistent lesion segmentation?
Jan 10, 2023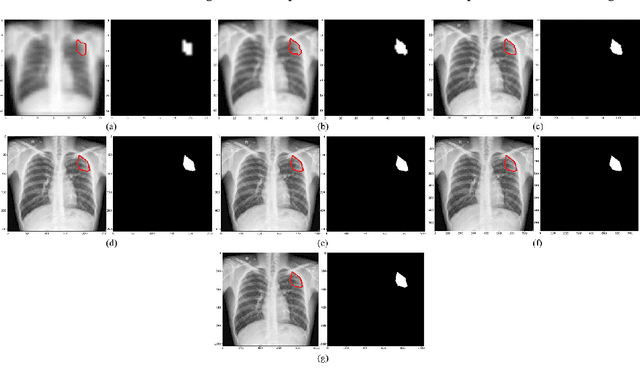
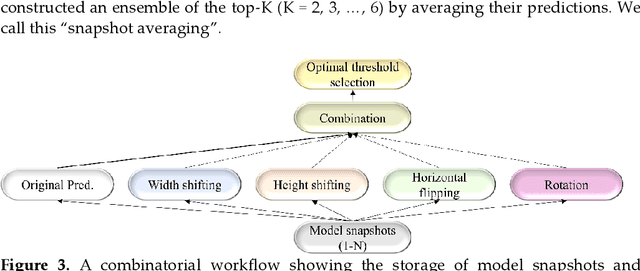
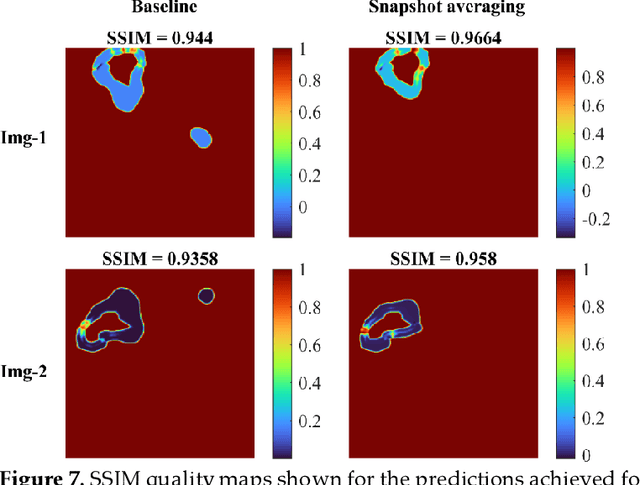
Deep learning (DL) models are becoming state-of-the-art in segmenting anatomical and disease regions of interest (ROIs) in medical images, particularly chest X-rays (CXRs). However, these models are reportedly trained on reduced image resolutions citing reasons for the lack of computational resources. Literature is sparse considering identifying the optimal image resolution to train these models for the task under study, particularly considering segmentation of Tuberculosis (TB)-consistent lesions in CXRs. In this study, we used the (i) Shenzhen TB CXR dataset, investigated performance gains achieved through training an Inception-V3-based UNet model using various image/mask resolutions with/without lung ROI cropping and aspect ratio adjustments, and (ii) identified the optimal image resolution through extensive empirical evaluations to improve TB-consistent lesion segmentation performance. We proposed a combinatorial approach consisting of storing model snapshots, optimizing test-time augmentation (TTA) methods, and selecting the optimal segmentation threshold to further improve performance at the optimal resolution. We emphasize that (i) higher image resolutions are not always necessary and (ii) identifying the optimal image resolution is indispensable to achieve superior performance for the task under study.
Generalizability of Deep Adult Lung Segmentation Models to the Pediatric Population: A Retrospective Study
Nov 04, 2022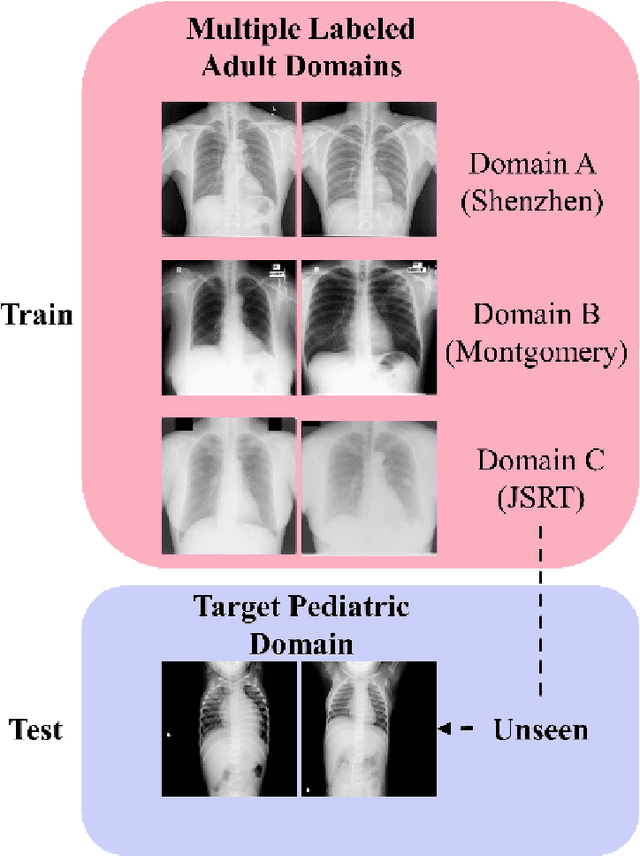

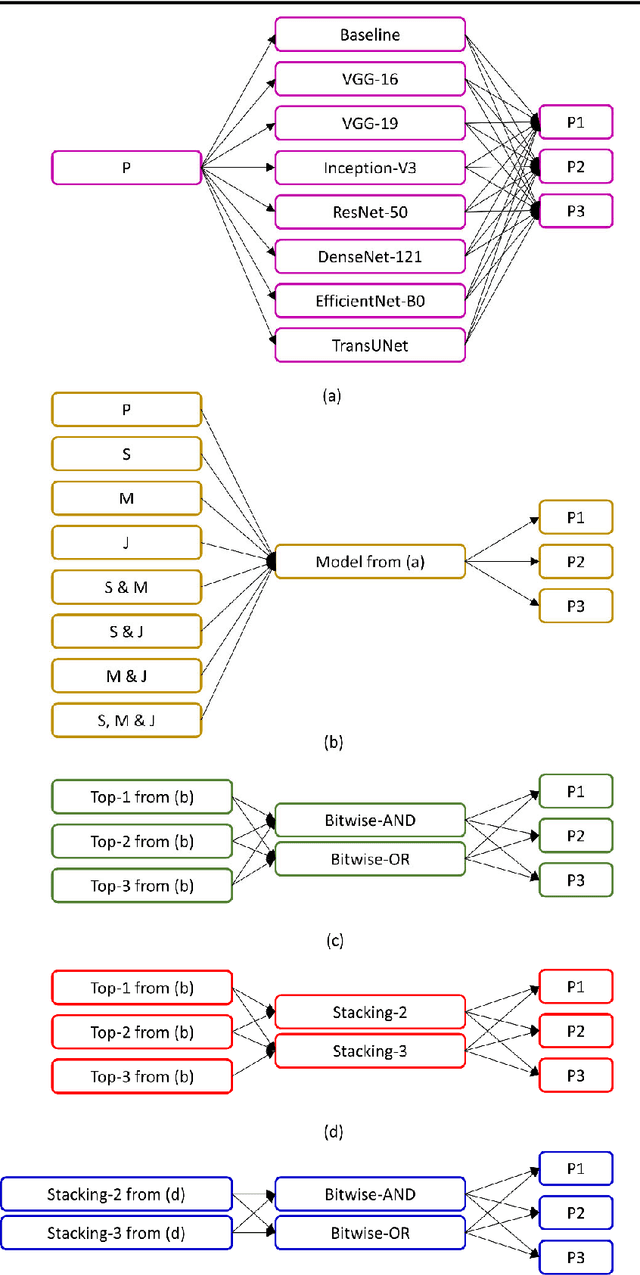

Lung segmentation in chest X-rays (CXRs) is an important prerequisite for improving the specificity of diagnoses of cardiopulmonary diseases in a clinical decision support system. Current deep learning (DL) models for lung segmentation are trained and evaluated on CXR datasets in which the radiographic projections are captured predominantly from the adult population. However, the shape of the lungs is reported to be significantly different for pediatrics across the developmental stages from infancy to adulthood. This might result in age-related data domain shifts that would adversely impact lung segmentation performance when the models trained on the adult population are deployed for pediatric lung segmentation. In this work, our goal is to analyze the generalizability of deep adult lung segmentation models to the pediatric population and improve performance through a systematic combinatorial approach consisting of CXR modality-specific weight initializations, stacked generalization, and an ensemble of the stacked generalization models. Novel evaluation metrics consisting of Mean Lung Contour Distance and Average Hash Score are proposed in addition to the Multi-scale Structural Similarity Index Measure, Intersection of Union, and Dice metrics to evaluate segmentation performance. We observed a significant improvement (p < 0.05) in cross-domain generalization through our combinatorial approach. This study could serve as a paradigm to analyze the cross-domain generalizability of deep segmentation models for other medical imaging modalities and applications.
Functional Parcellation of fMRI data using multistage k-means clustering
Feb 19, 2022Purpose: Functional Magnetic Resonance Imaging (fMRI) data acquired through resting-state studies have been used to obtain information about the spontaneous activations inside the brain. One of the approaches for analysis and interpretation of resting-state fMRI data require spatially and functionally homogenous parcellation of the whole brain based on underlying temporal fluctuations. Clustering is often used to generate functional parcellation. However, major clustering algorithms, when used for fMRI data, have their limitations. Among commonly used parcellation schemes, a tradeoff exists between intra-cluster functional similarity and alignment with anatomical regions. Approach: In this work, we present a clustering algorithm for resting state and task fMRI data which is developed to obtain brain parcellations that show high structural and functional homogeneity. The clustering is performed by multistage binary k-means clustering algorithm designed specifically for the 4D fMRI data. The results from this multistage k-means algorithm show that by modifying and combining different algorithms, we can take advantage of the strengths of different techniques while overcoming their limitations. Results: The clustering output for resting state fMRI data using the multistage k-means approach is shown to be better than simple k-means or functional atlas in terms of spatial and functional homogeneity. The clusters also correspond to commonly identifiable brain networks. For task fMRI, the clustering output can identify primary and secondary activation regions and provide information about the varying hemodynamic response across different brain regions. Conclusion: The multistage k-means approach can provide functional parcellations of the brain using resting state fMRI data. The method is model-free and is data driven which can be applied to both resting state and task fMRI.
Deep Cervix Model Development from Heterogeneous and Partially Labeled Image Datasets
Jan 18, 2022Cervical cancer is the fourth most common cancer in women worldwide. The availability of a robust automated cervical image classification system can augment the clinical care provider's limitation in traditional visual inspection with acetic acid (VIA). However, there are a wide variety of cervical inspection objectives which impact the labeling criteria for criteria-specific prediction model development. Moreover, due to the lack of confirmatory test results and inter-rater labeling variation, many images are left unlabeled. Motivated by these challenges, we propose a self-supervised learning (SSL) based approach to produce a pre-trained cervix model from unlabeled cervical images. The developed model is further fine-tuned to produce criteria-specific classification models with the available labeled images. We demonstrate the effectiveness of the proposed approach using two cervical image datasets. Both datasets are partially labeled and labeling criteria are different. The experimental results show that the SSL-based initialization improves classification performance (Accuracy: 2.5% min) and the inclusion of images from both datasets during SSL further improves the performance (Accuracy: 1.5% min). Further, considering data-sharing restrictions, we experimented with the effectiveness of Federated SSL and find that it can improve performance over the SSL model developed with just its images. This justifies the importance of SSL-based cervix model development. We believe that the present research shows a novel direction in developing criteria-specific custom deep models for cervical image classification by combining images from different sources unlabeled and/or labeled with varying criteria, and addressing image access restrictions.
Selective Synthetic Augmentation with HistoGAN for Improved Histopathology Image Classification
Nov 10, 2021
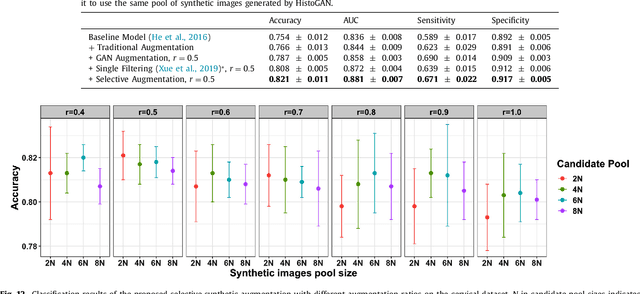

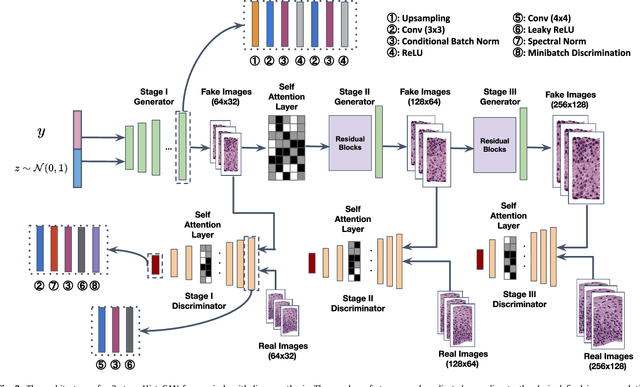
Histopathological analysis is the present gold standard for precancerous lesion diagnosis. The goal of automated histopathological classification from digital images requires supervised training, which requires a large number of expert annotations that can be expensive and time-consuming to collect. Meanwhile, accurate classification of image patches cropped from whole-slide images is essential for standard sliding window based histopathology slide classification methods. To mitigate these issues, we propose a carefully designed conditional GAN model, namely HistoGAN, for synthesizing realistic histopathology image patches conditioned on class labels. We also investigate a novel synthetic augmentation framework that selectively adds new synthetic image patches generated by our proposed HistoGAN, rather than expanding directly the training set with synthetic images. By selecting synthetic images based on the confidence of their assigned labels and their feature similarity to real labeled images, our framework provides quality assurance to synthetic augmentation. Our models are evaluated on two datasets: a cervical histopathology image dataset with limited annotations, and another dataset of lymph node histopathology images with metastatic cancer. Here, we show that leveraging HistoGAN generated images with selective augmentation results in significant and consistent improvements of classification performance (6.7% and 2.8% higher accuracy, respectively) for cervical histopathology and metastatic cancer datasets.
* Elsevier Medical Image Analysis Best Paper Award runner up. arXiv admin note: substantial text overlap with arXiv:1912.03837
A bone suppression model ensemble to improve COVID-19 detection in chest X-rays
Nov 05, 2021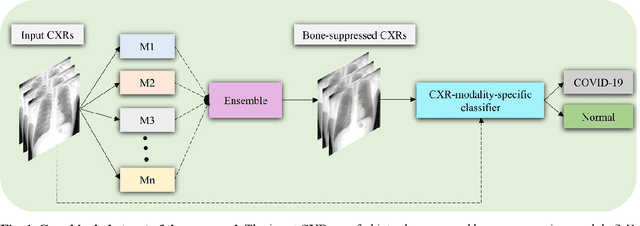
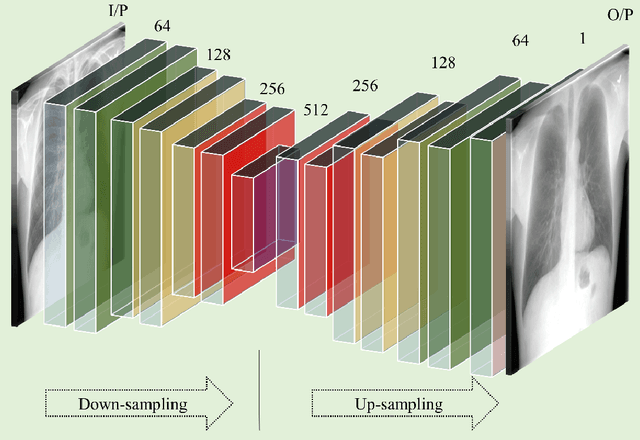
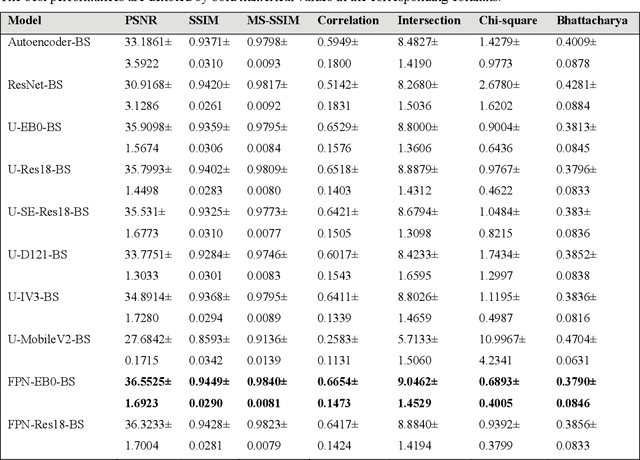
Chest X-ray (CXR) is a widely performed radiology examination that helps to detect abnormalities in the tissues and organs in the thoracic cavity. Detecting pulmonary abnormalities like COVID-19 may become difficult due to that they are obscured by the presence of bony structures like the ribs and the clavicles, thereby resulting in screening/diagnostic misinterpretations. Automated bone suppression methods would help suppress these bony structures and increase soft tissue visibility. In this study, we propose to build an ensemble of convolutional neural network models to suppress bones in frontal CXRs, improve classification performance, and reduce interpretation errors related to COVID-19 detection. The ensemble is constructed by (i) measuring the multi-scale structural similarity index (MS-SSIM) score between the sub-blocks of the bone-suppressed image predicted by each of the top-3 performing bone-suppression models and the corresponding sub-blocks of its respective ground truth soft-tissue image, and (ii) performing a majority voting of the MS-SSIM score computed in each sub-block to identify the sub-block with the maximum MS-SSIM score and use it in constructing the final bone-suppressed image. We empirically determine the sub-block size that delivers superior bone suppression performance. It is observed that the bone suppression model ensemble outperformed the individual models in terms of MS-SSIM and other metrics. A CXR modality-specific classification model is retrained and evaluated on the non-bone-suppressed and bone-suppressed images to classify them as showing normal lungs or other COVID-19-like manifestations. We observed that the bone-suppressed model training significantly outperformed the model trained on non-bone-suppressed images toward detecting COVID-19 manifestations.
Does deep learning model calibration improve performance in class-imbalanced medical image classification?
Oct 11, 2021
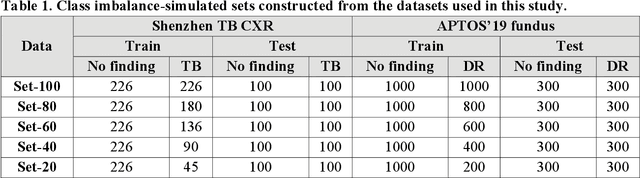
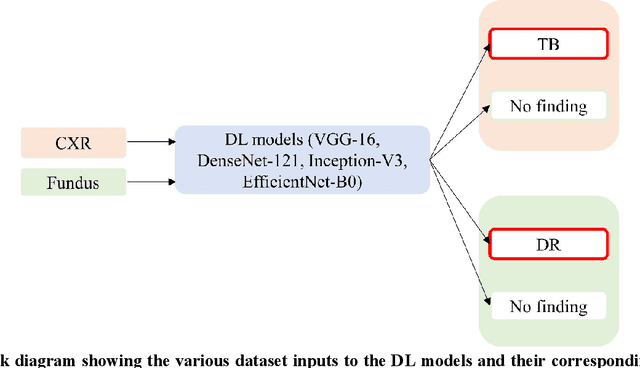
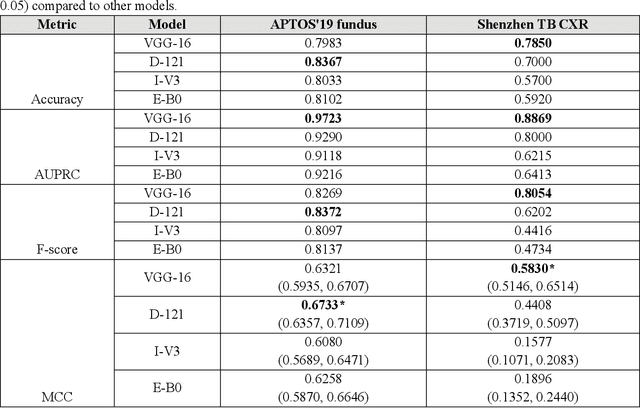
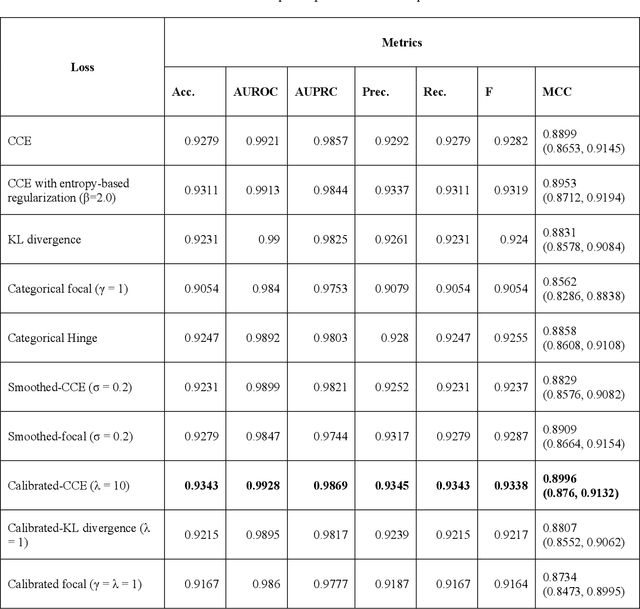
In medical image classification tasks, it is common to find that the number of normal samples far exceeds the number of abnormal samples. In such class-imbalanced situations, reliable training of deep neural networks continues to be a major challenge. Under these circumstances, the predicted class probabilities may be biased toward the majority class. Calibration has been suggested to alleviate some of these effects. However, there is insufficient analysis explaining when and whether calibrating a model would be beneficial in improving performance. In this study, we perform a systematic analysis of the effect of model calibration on its performance on two medical image modalities, namely, chest X-rays and fundus images, using various deep learning classifier backbones. For this, we study the following variations: (i) the degree of imbalances in the dataset used for training; (ii) calibration methods; and (iii) two classification thresholds, namely, default decision threshold of 0.5, and optimal threshold from precision-recall curves. Our results indicate that at the default operating threshold of 0.5, the performance achieved through calibration is significantly superior (p < 0.05) to using uncalibrated probabilities. However, at the PR-guided threshold, these gains are not significantly different (p > 0.05). This finding holds for both image modalities and at varying degrees of imbalance.
Multi-loss ensemble deep learning for chest X-ray classification
Sep 29, 2021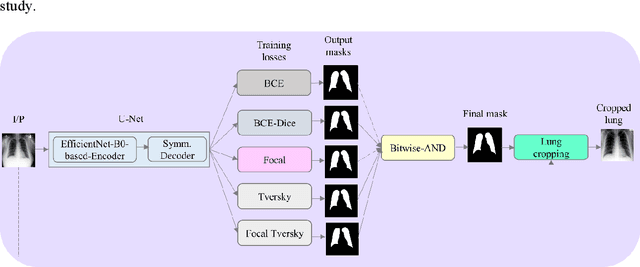
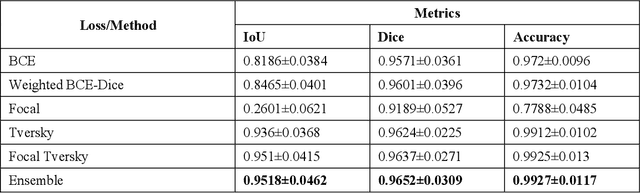
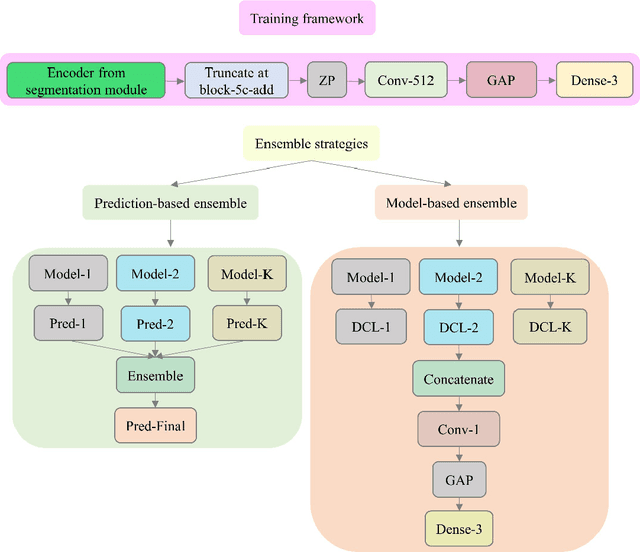
Class imbalance is common in medical image classification tasks, where the number of abnormal samples is fewer than the number of normal samples. The difficulty of imbalanced classification is compounded by other issues such as the size and distribution of the dataset. Reliable training of deep neural networks continues to be a major challenge in such class-imbalanced conditions. The loss function used to train the deep neural networks highly impact the performance of both balanced and imbalanced tasks. Currently, the cross-entropy loss remains the de-facto loss function for balanced and imbalanced classification tasks. This loss, however, asserts equal learning to all classes, leading to the classification of most samples as the majority normal class. To provide a critical analysis of different loss functions and identify those suitable for class-imbalanced classification, we benchmark various state-of-the-art loss functions and propose novel loss functions to train a DL model and analyze its performance in a multiclass classification setting that classifies pediatric chest X-rays as showing normal lungs, bacterial pneumonia, or viral pneumonia manifestations. We also construct prediction-level and model-level ensembles of the models that are trained with various loss functions to improve classification performance. We performed localization studies to interpret model behavior to ensure that the individual models and their ensembles precisely learned the regions of interest showing disease manifestations to classify the chest X-rays to their respective categories.