 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Detection of LLM-Generated Text: A Comparative Analysis
Paper and Code
Nov 09, 2024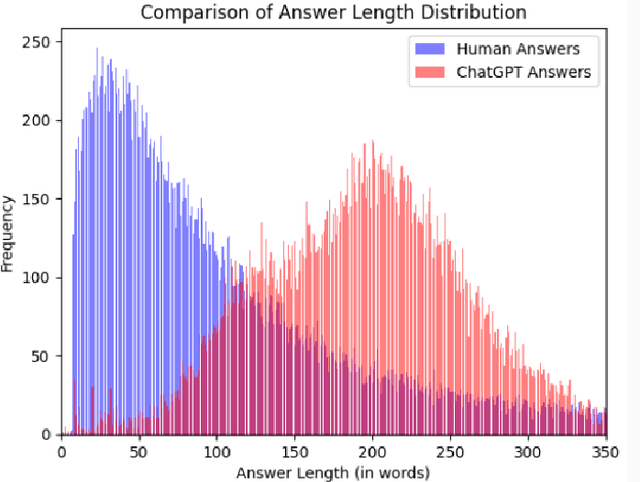
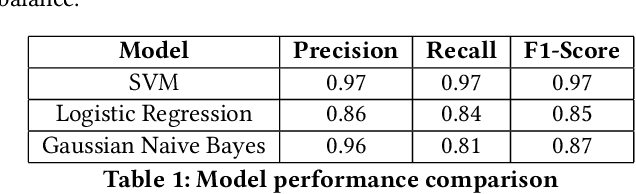
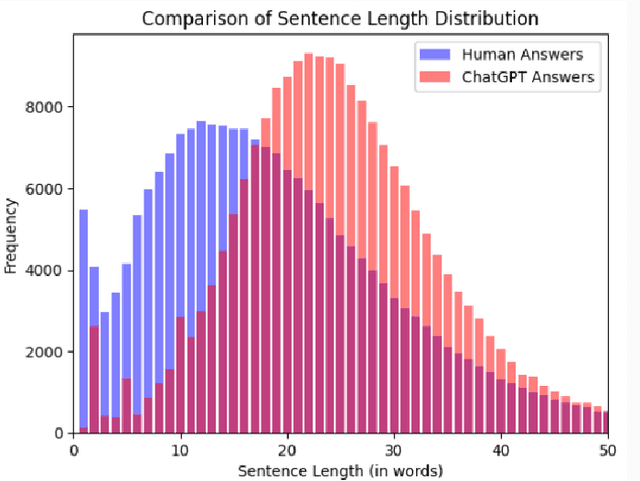
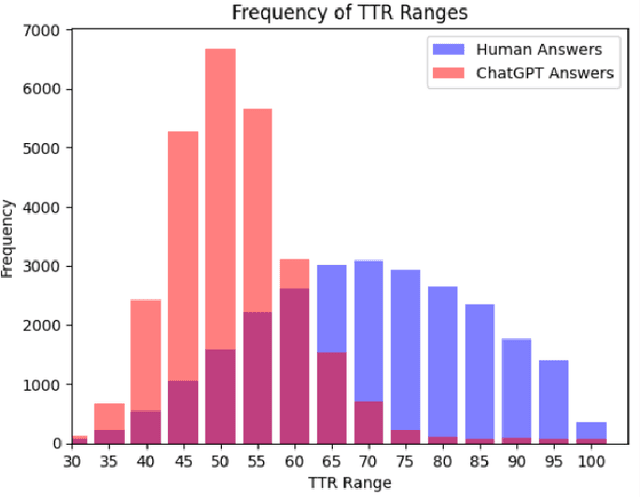
The ability of large language models to generate complex texts allows them to be widely integrated into many aspects of life, and their output can quickly fill all network resources. As the impact of LLMs grows, it becomes increasingly important to develop powerful detectors for the generated text. This detector is essential to prevent the potential misuse of these technologies and to protect areas such as social media from the negative effects of false content generated by LLMS. The main goal of LLM-generated text detection is to determine whether text is generated by an LLM, which is a basic binary classification task. In our work, we mainly use three different classification methods based on open source datasets: traditional machine learning techniques such as logistic regression, k-means clustering, Gaussian Naive Bayes, support vector machines, and methods based on converters such as BERT, and finally algorithms that use LLMs to detect LLM-generated text. We focus on model generalization, potential adversarial attacks, and accuracy of model evaluation. Finally, the possible research direction in the future is proposed, and the current experimental results are summarized.