 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoTok: Regulating Information Flow for Capacity-Constrained Shared Visual Tokenization in Unified MLLMs
Feb 02, 2026Unified multimodal large language models (MLLMs) integrate image understanding and generation in a single framework, with the visual tokenizer acting as the sole interface that maps visual inputs into tokens for downstream tasks. However, existing shared-token designs are mostly architecture-driven and lack an explicit criterion for what information tokens should preserve to support both understanding and generation. Therefore, we introduce a capacity-constrained perspective, highlighting that in shared-token unified MLLMs the visual tokenizer behaves as a compute-bounded learner, so the token budget should prioritize reusable structure over hard-to-exploit high-entropy variations and redundancy. Motivated by this perspective, we propose InfoTok, an information-regularized visual tokenization mechanism grounded in the Information Bottleneck (IB) principle. InfoTok formulates tokenization as controlling information flow from images to shared tokens to multimodal outputs, yielding a principled trade-off between compression and task relevance via mutual-information regularization. We integrate InfoTok into three representative unified MLLMs without introducing any additional training data. Experiments show consistent improvements on both understanding and generation, supporting information-regularized tokenization as a principled foundation for learning a shared token space in unified MLLMs.
Pruning for Sparse Diffusion Models based on Gradient Flow
Jan 16, 2025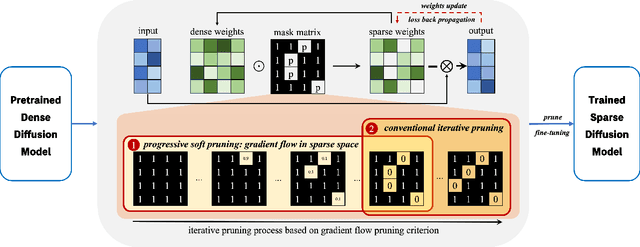
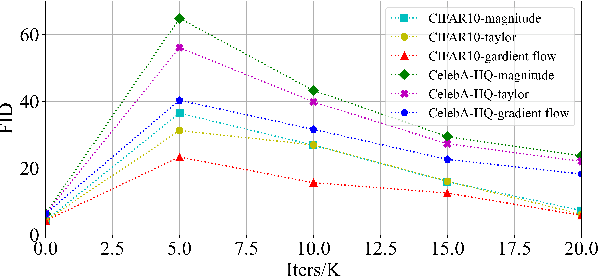
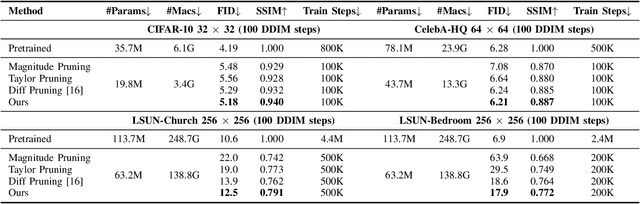
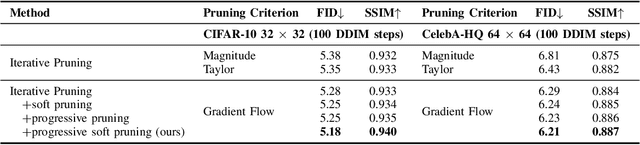
Diffusion Models (DMs) have impressive capabilities among generation models, but are limited to slower inference speeds and higher computational costs. Previous works utilize one-shot structure pruning to derive lightweight DMs from pre-trained ones, but this approach often leads to a significant drop in generation quality and may result in the removal of crucial weights. Thus we propose a iterative pruning method based on gradient flow, including the gradient flow pruning process and the gradient flow pruning criterion. We employ a progressive soft pruning strategy to maintain the continuity of the mask matrix and guide it along the gradient flow of the energy function based on the pruning criterion in sparse space, thereby avoiding the sudden information loss typically caused by one-shot pruning. Gradient-flow based criterion prune parameters whose removal increases the gradient norm of loss function and can enable fast convergence for a pruned model in iterative pruning stage. Our extensive experiments on widely used datasets demonstrate that our method achieves superior performance in efficiency and consistency with pre-trained models.
Towards Generalizable Data Protection With Transferable Unlearnable Examples
May 18, 2023Artificial Intelligence (AI) is making a profound impact in almost every domain. One of the crucial factors contributing to this success has been the access to an abundance of high-quality data for constructing machine learning models. Lately, as the role of data in artificial intelligence has been significantly magnified, concerns have arisen regarding the secure utilization of data, particularly in the context of unauthorized data usage. To mitigate data exploitation, data unlearning have been introduced to render data unexploitable. However, current unlearnable examples lack the generalization required for wide applicability. In this paper, we present a novel, generalizable data protection method by generating transferable unlearnable examples. To the best of our knowledge, this is the first solution that examines data privacy from the perspective of data distribution. Through extensive experimentation, we substantiate the enhanced generalizable protection capabilities of our proposed method.
MCAE: Masked Contrastive Autoencoder for Face Anti-Spoofing
Feb 17, 2023Face anti-spoofing (FAS) method performs well under the intra-domain setups. But cross-domain performance of the model is not satisfying. Domain generalization method has been used to align the feature from different domain extracted by convolutional neural network (CNN) backbone. However, the improvement is limited. Recently, the Vision Transformer (ViT) model has performed well on various visual tasks. But ViT model relies heavily on pre-training of large-scale dataset, which cannot be satisfied by existing FAS datasets. In this paper, taking the FAS task as an example, we propose Masked Contrastive Autoencoder (MCAE) method to solve this problem using only limited data. Meanwhile in order for a feature extractor to extract common features in live samples from different domains, we combine Masked Image Model (MIM) with supervised contrastive learning to train our model.Some intriguing design principles are summarized for performing MIM pre-training for downstream tasks.We also provide insightful analysis for our method from an information theory perspective. Experimental results show our approach has good performance on extensive public datasets and outperforms the state-of-the-art methods.