 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Picture is Worth A Thousand Numbers: Enabling LLMs Reason about Time Series via Visualization
Paper and Code
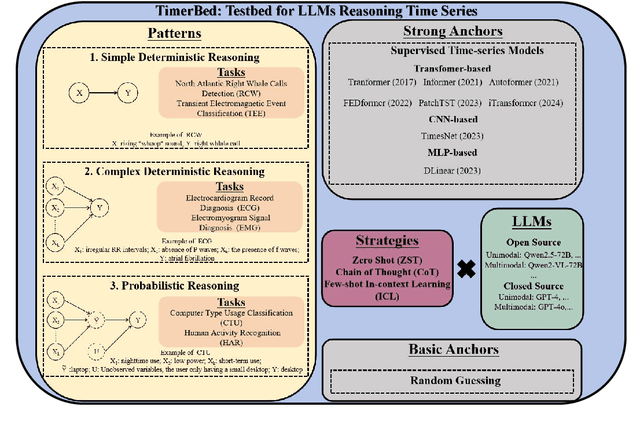
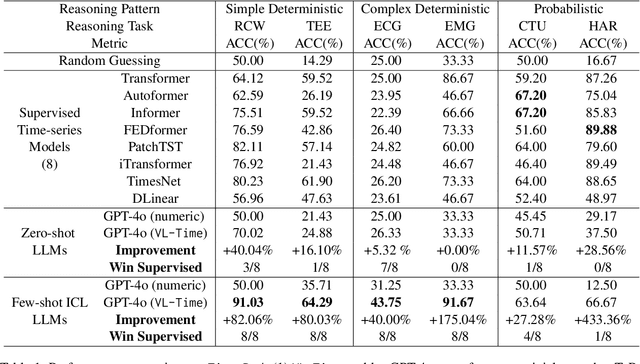
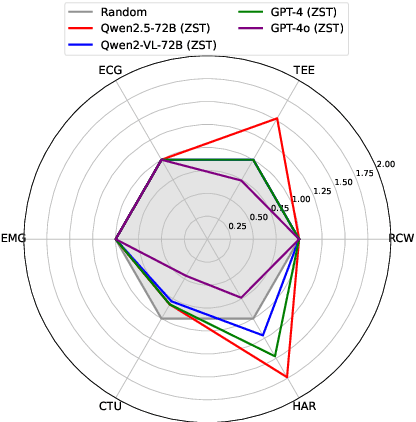

Large language models (LLMs), with demonstrated reasoning abilities across multiple domains, are largely underexplored for time-series reasoning (TsR), which is ubiquitous in the real world. In this work, we propose TimerBed, the first comprehensive testbed for evaluating LLMs' TsR performance. Specifically, TimerBed includes stratified reasoning patterns with real-world tasks, comprehensive combinations of LLMs and reasoning strategies, and various supervised models as comparison anchors. We perform extensive experiments with TimerBed, test multiple current beliefs, and verify the initial failures of LLMs in TsR, evidenced by the ineffectiveness of zero shot (ZST) and performance degradation of few shot in-context learning (ICL). Further, we identify one possible root cause: the numerical modeling of data. To address this, we propose a prompt-based solution VL-Time, using visualization-modeled data and language-guided reasoning. Experimental results demonstrate that Vl-Time enables multimodal LLMs to be non-trivial ZST and powerful ICL reasoners for time series, achieving about 140% average performance improvement and 99% average token costs reduction.