 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Speech Recognizers to Imagine Lyrics
Dec 15, 2019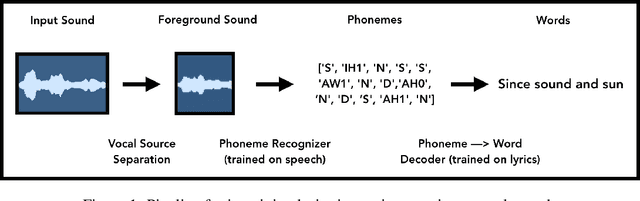

We introduce a new method for generating text, and in particular song lyrics, based on the speech-like acoustic qualities of a given audio file. We repurpose a vocal source separation algorithm and an acoustic model trained to recognize isolated speech, instead inputting instrumental music or environmental sounds. Feeding the "mistakes" of the vocal separator into the recognizer, we obtain a transcription of words \emph{imagined} to be spoken in the input audio. We describe the key components of our approach, present initial analysis, and discuss the potential of the method for machine-in-the-loop collaboration in creative applications.
* 3 pages
Learning to Groove with Inverse Sequence Transformations
May 14, 2019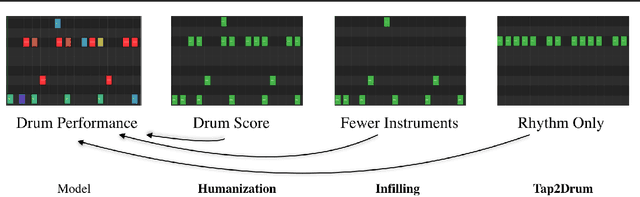
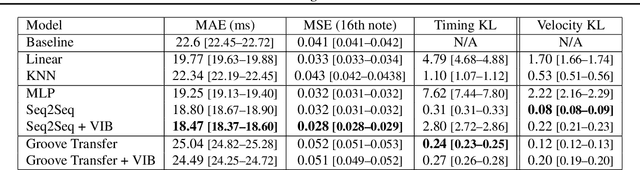
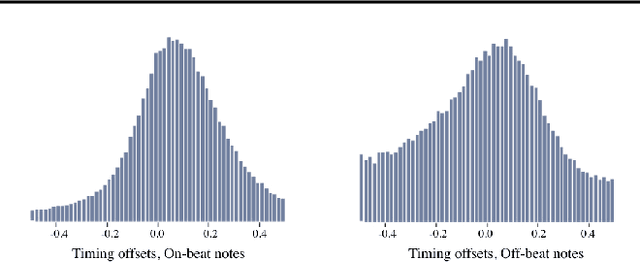
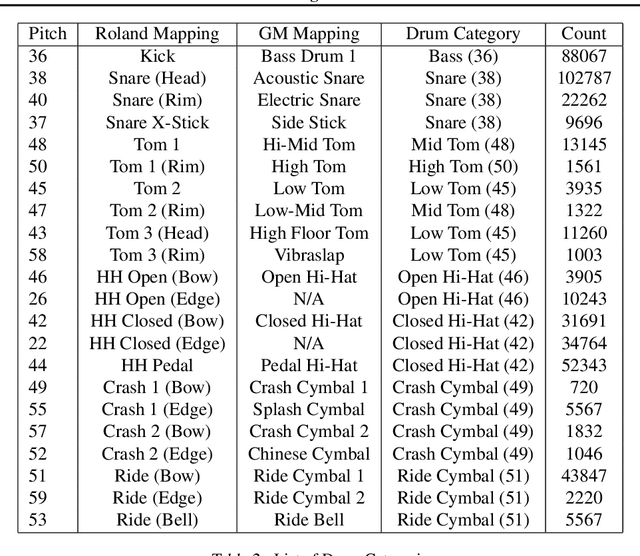
We explore models for translating abstract musical ideas (scores, rhythms) into expressive performances using Seq2Seq and recurrent Variational Information Bottleneck (VIB) models. Though Seq2Seq models usually require painstakingly aligned corpora, we show that it is possible to adapt an approach from the Generative Adversarial Network (GAN) literature (e.g. Pix2Pix (Isola et al., 2017) and Vid2Vid (Wang et al. 2018a)) to sequences, creating large volumes of paired data by performing simple transformations and training generative models to plausibly invert these transformations. Music, and drumming in particular, provides a strong test case for this approach because many common transformations (quantization, removing voices) have clear semantics, and models for learning to invert them have real-world applications. Focusing on the case of drum set players, we create and release a new dataset for this purpose, containing over 13 hours of recordings by professional drummers aligned with fine-grained timing and dynamics information. We also explore some of the creative potential of these models, including demonstrating improvements on state-of-the-art methods for Humanization (instantiating a performance from a musical score).