 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Game-Theoretic Analysis of Autonomous Cyber-Defence Agents
Jan 31, 2025The recent rise in increasingly sophisticated cyber-attacks raises the need for robust and resilient autonomous cyber-defence (ACD) agents. Given the variety of cyber-attack tactics, techniques and procedures (TTPs) employed, learning approaches that can return generalisable policies are desirable. Meanwhile, the assurance of ACD agents remains an open challenge. We address both challenges via an empirical game-theoretic analysis of deep reinforcement learning (DRL) approaches for ACD using the principled double oracle (DO) algorithm. This algorithm relies on adversaries iteratively learning (approximate) best responses against each others' policies; a computationally expensive endeavour for autonomous cyber operations agents. In this work we introduce and evaluate a theoretically-sound, potential-based reward shaping approach to expedite this process. In addition, given the increasing number of open-source ACD-DRL approaches, we extend the DO formulation to allow for multiple response oracles (MRO), providing a framework for a holistic evaluation of ACD approaches.
Machine Theory of Mind for Autonomous Cyber-Defence
Dec 05, 2024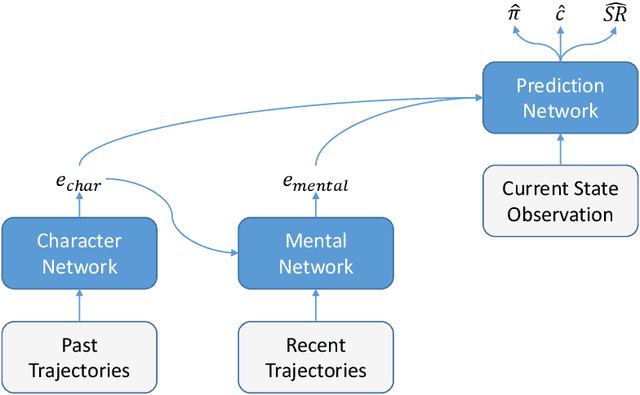
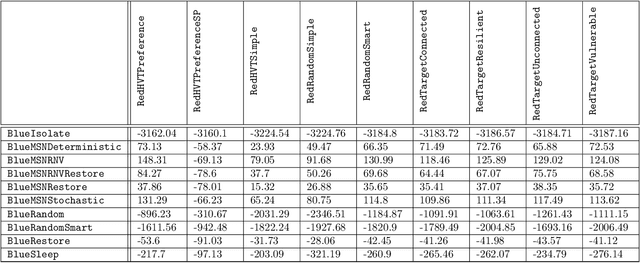
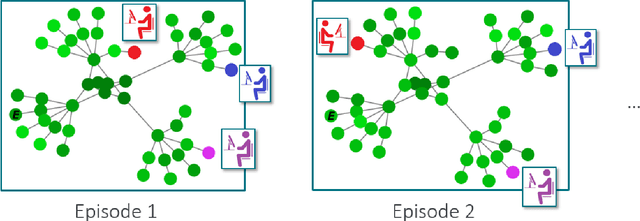
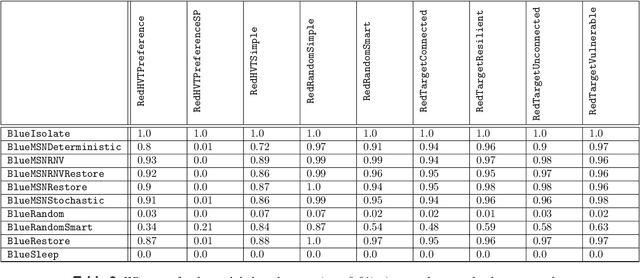
Intelligent autonomous agents hold much potential for the domain of cyber-security. However, due to many state-of-the-art approaches relying on uninterpretable black-box models, there is growing demand for methods that offer stakeholders clear and actionable insights into their latent beliefs and motivations. To address this, we evaluate Theory of Mind (ToM) approaches for Autonomous Cyber Operations. Upon learning a robust prior, ToM models can predict an agent's goals, behaviours, and contextual beliefs given only a handful of past behaviour observations. In this paper, we introduce a novel Graph Neural Network (GNN)-based ToM architecture tailored for cyber-defence, Graph-In, Graph-Out (GIGO)-ToM, which can accurately predict both the targets and attack trajectories of adversarial cyber agents over arbitrary computer network topologies. To evaluate the latter, we propose a novel extension of the Wasserstein distance for measuring the similarity of graph-based probability distributions. Whereas the standard Wasserstein distance lacks a fixed reference scale, we introduce a graph-theoretic normalization factor that enables a standardized comparison between networks of different sizes. We furnish this metric, which we term the Network Transport Distance (NTD), with a weighting function that emphasizes predictions according to custom node features, allowing network operators to explore arbitrary strategic considerations. Benchmarked against a Graph-In, Dense-Out (GIDO)-ToM architecture in an abstract cyber-defence environment, our empirical evaluations show that GIGO-ToM can accurately predict the goals and behaviours of various unseen cyber-attacking agents across a range of network topologies, as well as learn embeddings that can effectively characterize their policies.
Deep Reinforcement Learning for Autonomous Cyber Operations: A Survey
Oct 11, 2023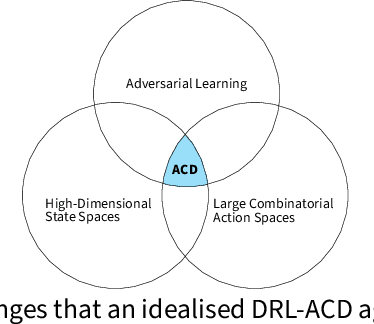
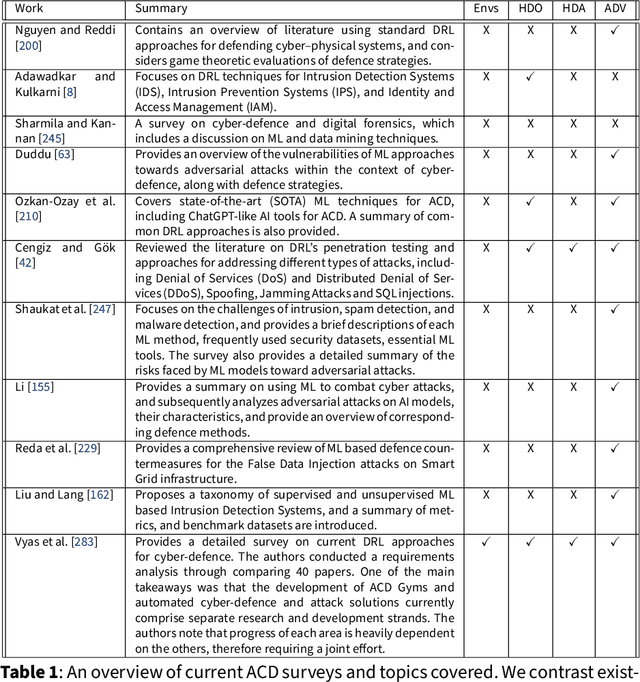
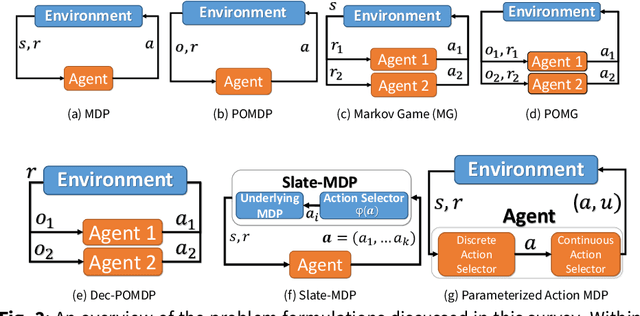
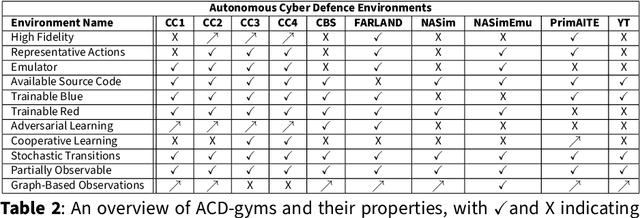
The rapid increase in the number of cyber-attacks in recent years raises the need for principled methods for defending networks against malicious actors. Deep reinforcement learning (DRL) has emerged as a promising approach for mitigating these attacks. However, while DRL has shown much potential for cyber-defence, numerous challenges must be overcome before DRL can be applied to autonomous cyber-operations (ACO) at scale. Principled methods are required for environments that confront learners with very high-dimensional state spaces, large multi-discrete action spaces, and adversarial learning. Recent works have reported success in solving these problems individually. There have also been impressive engineering efforts towards solving all three for real-time strategy games. However, applying DRL to the full ACO problem remains an open challenge. Here, we survey the relevant DRL literature and conceptualize an idealised ACO-DRL agent. We provide: i.) A summary of the domain properties that define the ACO problem; ii.) A comprehensive evaluation of the extent to which domains used for benchmarking DRL approaches are comparable to ACO; iii.) An overview of state-of-the-art approaches for scaling DRL to domains that confront learners with the curse of dimensionality, and; iv.) A survey and critique of current methods for limiting the exploitability of agents within adversarial settings from the perspective of ACO. We conclude with open research questions that we hope will motivate future directions for researchers and practitioners working on ACO.
Determining the Veracity of Rumours on Twitter
Nov 19, 2016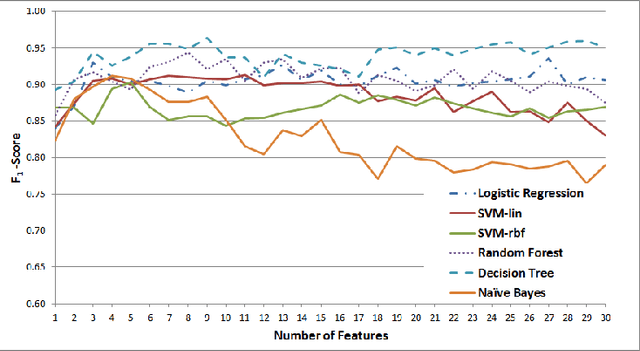

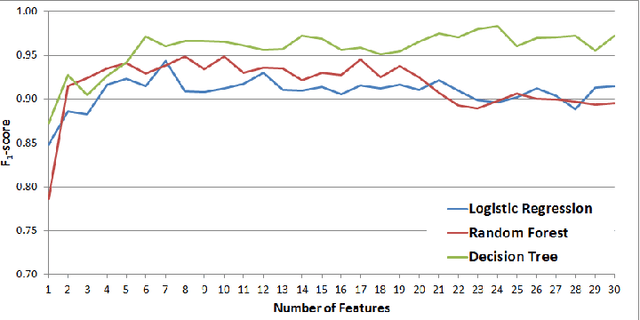
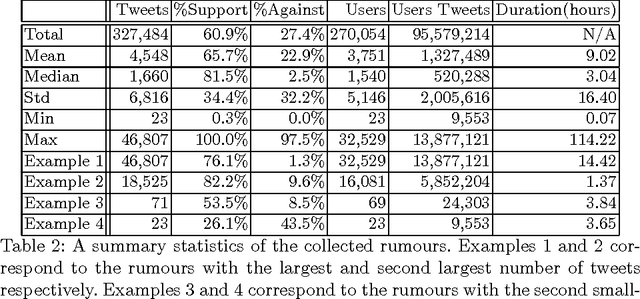
While social networks can provide an ideal platform for up-to-date information from individuals across the world, it has also proved to be a place where rumours fester and accidental or deliberate misinformation often emerges. In this article, we aim to support the task of making sense from social media data, and specifically, seek to build an autonomous message-classifier that filters relevant and trustworthy information from Twitter. For our work, we collected about 100 million public tweets, including users' past tweets, from which we identified 72 rumours (41 true, 31 false). We considered over 80 trustworthiness measures including the authors' profile and past behaviour, the social network connections (graphs), and the content of tweets themselves. We ran modern machine-learning classifiers over those measures to produce trustworthiness scores at various time windows from the outbreak of the rumour. Such time-windows were key as they allowed useful insight into the progression of the rumours. From our findings, we identified that our model was significantly more accurate than similar studies in the literature. We also identified critical attributes of the data that give rise to the trustworthiness scores assigned. Finally we developed a software demonstration that provides a visual user interface to allow the user to examine the analysis.
* 21 pages, 6 figures, 2 tables