 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReview of Low-Voltage Load Forecasting: Methods, Applications, and Recommendations
May 30, 2021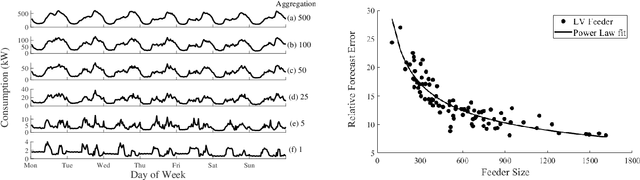

The increased digitalisation and monitoring of the energy system opens up numerous opportunities % and solutions which can help to decarbonise the energy system. Applications on low voltage (LV), localised networks, such as community energy markets and smart storage will facilitate decarbonisation, but they will require advanced control and management. Reliable forecasting will be a necessary component of many of these systems to anticipate key features and uncertainties. Despite this urgent need, there has not yet been an extensive investigation into the current state-of-the-art of low voltage level forecasts, other than at the smart meter level. This paper aims to provide a comprehensive overview of the landscape, current approaches, core applications, challenges and recommendations. Another aim of this paper is to facilitate the continued improvement and advancement in this area. To this end, the paper also surveys some of the most relevant and promising trends. It establishes an open, community-driven list of the known LV level open datasets to encourage further research and development.
Descriptive and Predictive Analysis of Euroleague Basketball Games and the Wisdom of Basketball Crowds
Feb 19, 2020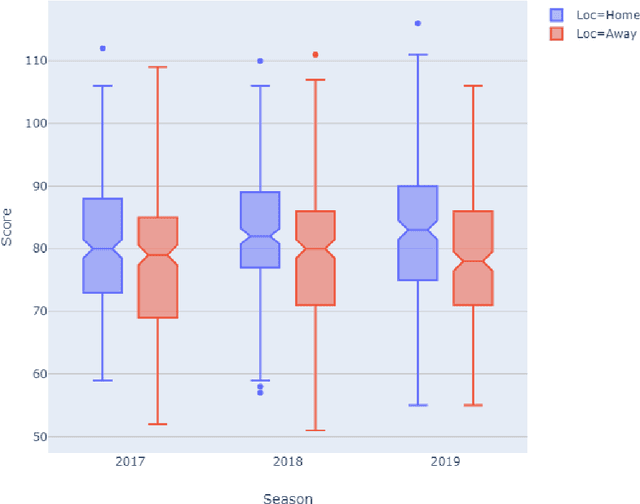
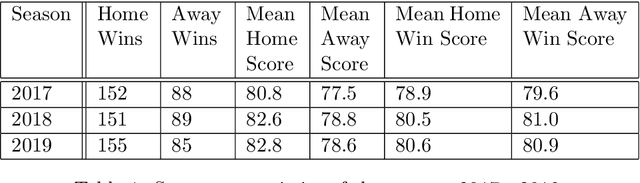
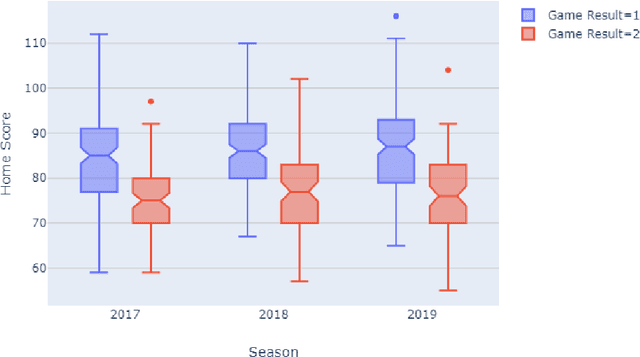

In this study we focus on the prediction of basketball games in the Euroleague competition using machine learning modelling. The prediction is a binary classification problem, predicting whether a match finishes 1 (home win) or 2 (away win). Data is collected from the Euroleague's official website for the seasons 2016-2017, 2017-2018 and 2018-2019, i.e. in the new format era. Features are extracted from matches' data and off-the-shelf supervised machine learning techniques are applied. We calibrate and validate our models. We find that simple machine learning models give accuracy not greater than 67% on the test set, worse than some sophisticated benchmark models. Additionally, the importance of this study lies in the "wisdom of the basketball crowd" and we demonstrate how the predicting power of a collective group of basketball enthusiasts can outperform machine learning models discussed in this study. We argue why the accuracy level of this group of "experts" should be set as the benchmark for future studies in the prediction of (European) basketball games using machine learning.
A semi-supervised approach to message stance classification
Jan 29, 2019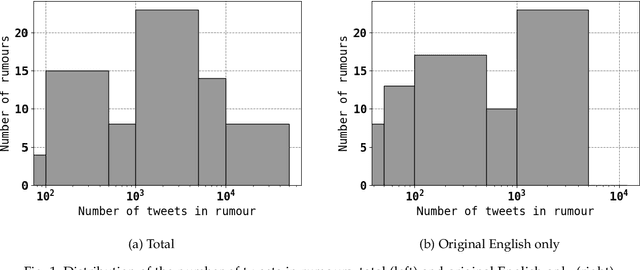
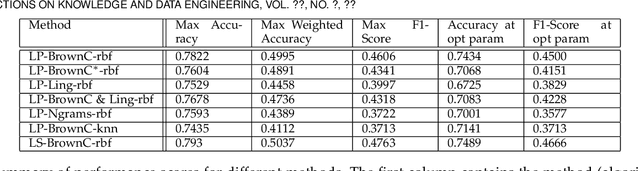
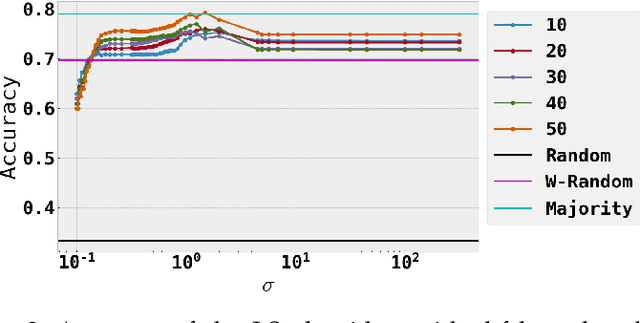
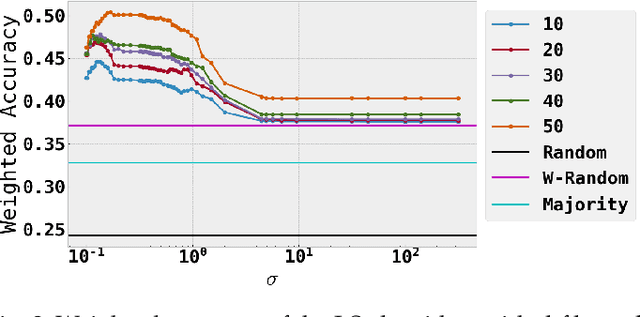
Social media communications are becoming increasingly prevalent; some useful, some false, whether unwittingly or maliciously. An increasing number of rumours daily flood the social networks. Determining their veracity in an autonomous way is a very active and challenging field of research, with a variety of methods proposed. However, most of the models rely on determining the constituent messages' stance towards the rumour, a feature known as the "wisdom of the crowd". Although several supervised machine-learning approaches have been proposed to tackle the message stance classification problem, these have numerous shortcomings. In this paper we argue that semi-supervised learning is more effective than supervised models and use two graph-based methods to demonstrate it. This is not only in terms of classification accuracy, but equally important, in terms of speed and scalability. We use the Label Propagation and Label Spreading algorithms and run experiments on a dataset of 72 rumours and hundreds of thousands messages collected from Twitter. We compare our results on two available datasets to the state-of-the-art to demonstrate our algorithms' performance regarding accuracy, speed and scalability for real-time applications.
* 33 pages, 8 figures, 1 table
Determining the Veracity of Rumours on Twitter
Nov 19, 2016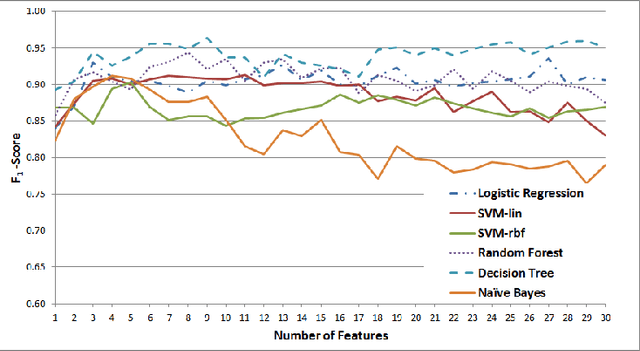

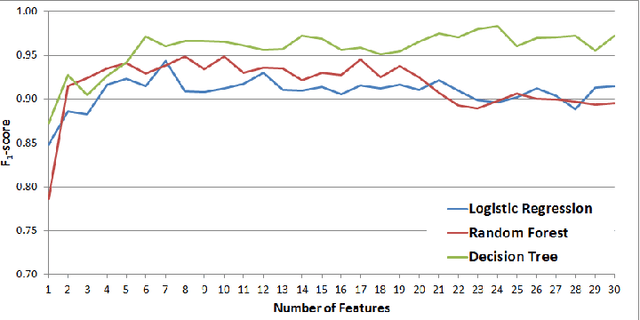
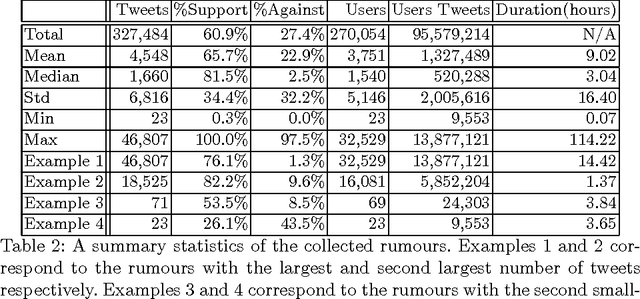
While social networks can provide an ideal platform for up-to-date information from individuals across the world, it has also proved to be a place where rumours fester and accidental or deliberate misinformation often emerges. In this article, we aim to support the task of making sense from social media data, and specifically, seek to build an autonomous message-classifier that filters relevant and trustworthy information from Twitter. For our work, we collected about 100 million public tweets, including users' past tweets, from which we identified 72 rumours (41 true, 31 false). We considered over 80 trustworthiness measures including the authors' profile and past behaviour, the social network connections (graphs), and the content of tweets themselves. We ran modern machine-learning classifiers over those measures to produce trustworthiness scores at various time windows from the outbreak of the rumour. Such time-windows were key as they allowed useful insight into the progression of the rumours. From our findings, we identified that our model was significantly more accurate than similar studies in the literature. We also identified critical attributes of the data that give rise to the trustworthiness scores assigned. Finally we developed a software demonstration that provides a visual user interface to allow the user to examine the analysis.
* 21 pages, 6 figures, 2 tables