 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA semi-supervised approach to message stance classification
Paper and Code
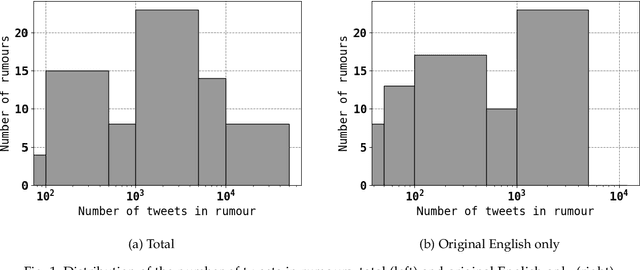
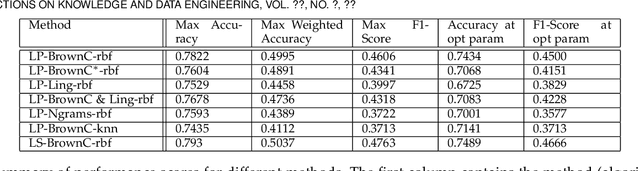
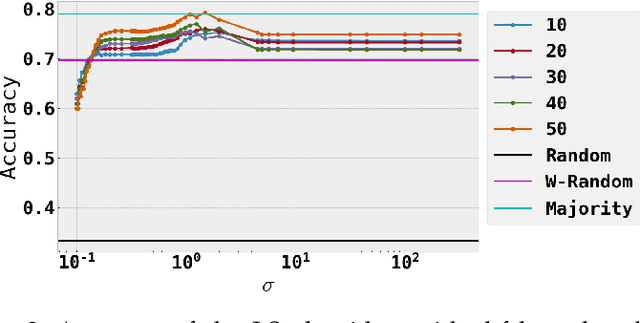
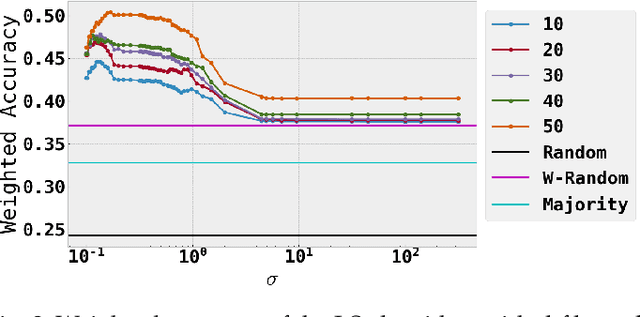
Social media communications are becoming increasingly prevalent; some useful, some false, whether unwittingly or maliciously. An increasing number of rumours daily flood the social networks. Determining their veracity in an autonomous way is a very active and challenging field of research, with a variety of methods proposed. However, most of the models rely on determining the constituent messages' stance towards the rumour, a feature known as the "wisdom of the crowd". Although several supervised machine-learning approaches have been proposed to tackle the message stance classification problem, these have numerous shortcomings. In this paper we argue that semi-supervised learning is more effective than supervised models and use two graph-based methods to demonstrate it. This is not only in terms of classification accuracy, but equally important, in terms of speed and scalability. We use the Label Propagation and Label Spreading algorithms and run experiments on a dataset of 72 rumours and hundreds of thousands messages collected from Twitter. We compare our results on two available datasets to the state-of-the-art to demonstrate our algorithms' performance regarding accuracy, speed and scalability for real-time applications.