 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatching the Phish: Detecting Phishing Attacks using Recurrent Neural Networks (RNNs)
Aug 09, 2019

The emergence of online services in our daily lives has been accompanied by a range of malicious attempts to trick individuals into performing undesired actions, often to the benefit of the adversary. The most popular medium of these attempts is phishing attacks, particularly through emails and websites. In order to defend against such attacks, there is an urgent need for automated mechanisms to identify this malevolent content before it reaches users. Machine learning techniques have gradually become the standard for such classification problems. However, identifying common measurable features of phishing content (e.g., in emails) is notoriously difficult. To address this problem, we engage in a novel study into a phishing content classifier based on a recurrent neural network (RNN), which identifies such features without human input. At this stage, we scope our research to emails, but our approach can be extended to apply to websites. Our results show that the proposed system outperforms state-of-the-art tools. Furthermore, our classifier is efficient and takes into account only the text and, in particular, the textual structure of the email. Since these features are rarely considered in email classification, we argue that our classifier can complement existing classifiers with high information gain.
* 13 pages
A semi-supervised approach to message stance classification
Jan 29, 2019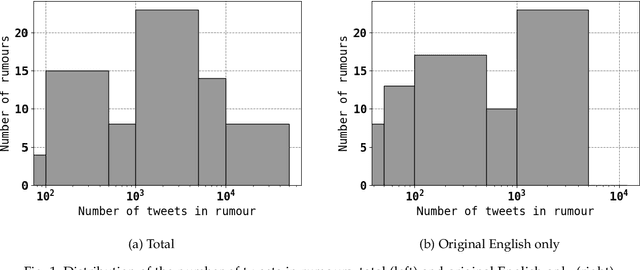
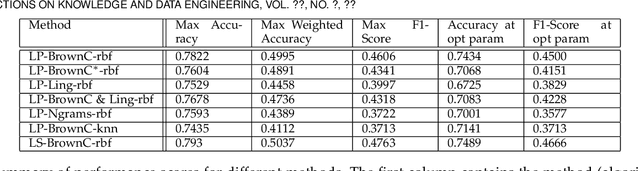
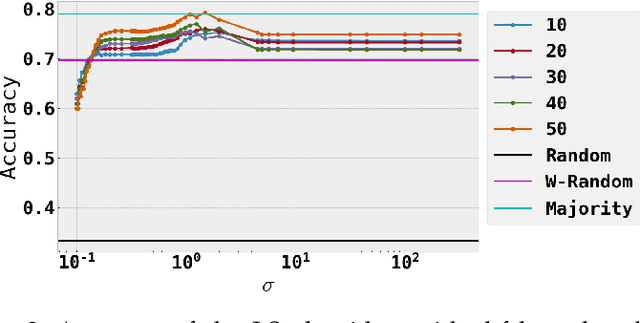
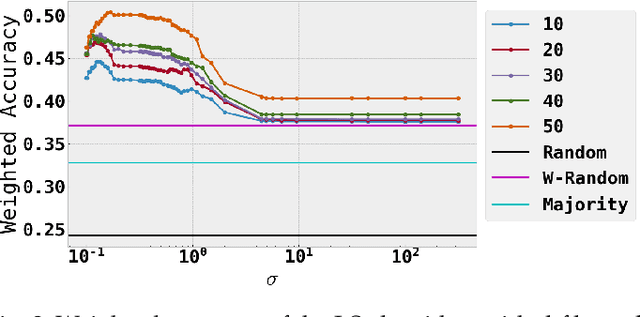
Social media communications are becoming increasingly prevalent; some useful, some false, whether unwittingly or maliciously. An increasing number of rumours daily flood the social networks. Determining their veracity in an autonomous way is a very active and challenging field of research, with a variety of methods proposed. However, most of the models rely on determining the constituent messages' stance towards the rumour, a feature known as the "wisdom of the crowd". Although several supervised machine-learning approaches have been proposed to tackle the message stance classification problem, these have numerous shortcomings. In this paper we argue that semi-supervised learning is more effective than supervised models and use two graph-based methods to demonstrate it. This is not only in terms of classification accuracy, but equally important, in terms of speed and scalability. We use the Label Propagation and Label Spreading algorithms and run experiments on a dataset of 72 rumours and hundreds of thousands messages collected from Twitter. We compare our results on two available datasets to the state-of-the-art to demonstrate our algorithms' performance regarding accuracy, speed and scalability for real-time applications.
* 33 pages, 8 figures, 1 table
Using semantic clustering to support situation awareness on Twitter: The case of World Views
Jul 17, 2018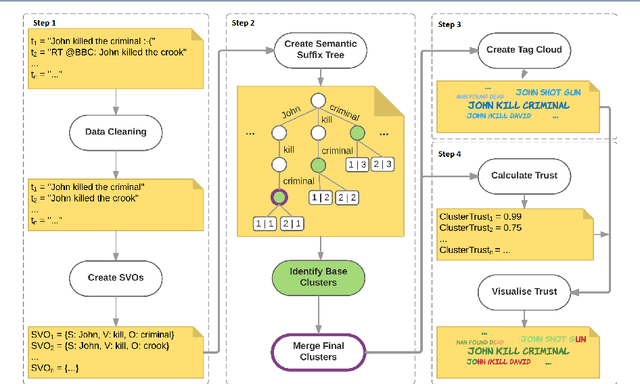



In recent years, situation awareness has been recognised as a critical part of effective decision making, in particular for crisis management. One way to extract value and allow for better situation awareness is to develop a system capable of analysing a dataset of multiple posts, and clustering consistent posts into different views or stories (or, world views). However, this can be challenging as it requires an understanding of the data, including determining what is consistent data, and what data corroborates other data. Attempting to address these problems, this article proposes Subject-Verb-Object Semantic Suffix Tree Clustering (SVOSSTC) and a system to support it, with a special focus on Twitter content. The novelty and value of SVOSSTC is its emphasis on utilising the Subject-Verb-Object (SVO) typology in order to construct semantically consistent world views, in which individuals---particularly those involved in crisis response---might achieve an enhanced picture of a situation from social media data. To evaluate our system and its ability to provide enhanced situation awareness, we tested it against existing approaches, including human data analysis, using a variety of real-world scenarios. The results indicated a noteworthy degree of evidence (e.g., in cluster granularity and meaningfulness) to affirm the suitability and rigour of our approach. Moreover, these results highlight this article's proposals as innovative and practical system contributions to the research field.
Determining the Veracity of Rumours on Twitter
Nov 19, 2016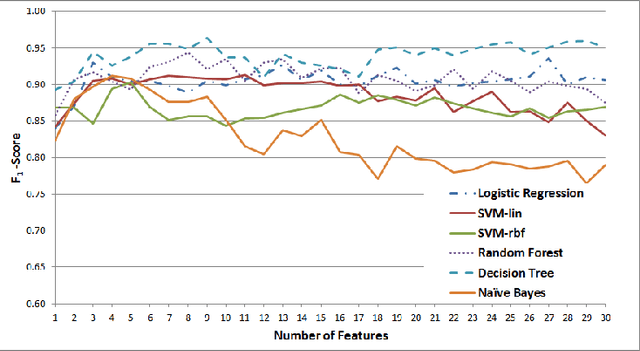

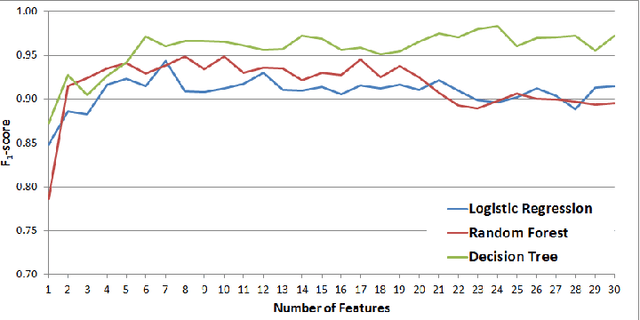
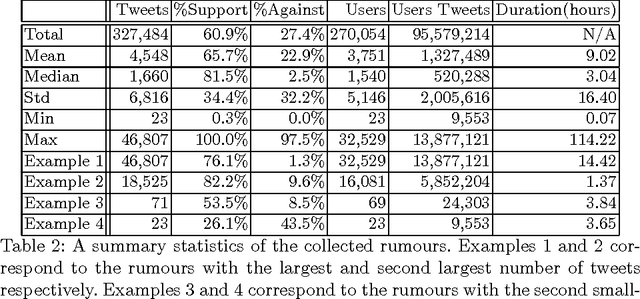
While social networks can provide an ideal platform for up-to-date information from individuals across the world, it has also proved to be a place where rumours fester and accidental or deliberate misinformation often emerges. In this article, we aim to support the task of making sense from social media data, and specifically, seek to build an autonomous message-classifier that filters relevant and trustworthy information from Twitter. For our work, we collected about 100 million public tweets, including users' past tweets, from which we identified 72 rumours (41 true, 31 false). We considered over 80 trustworthiness measures including the authors' profile and past behaviour, the social network connections (graphs), and the content of tweets themselves. We ran modern machine-learning classifiers over those measures to produce trustworthiness scores at various time windows from the outbreak of the rumour. Such time-windows were key as they allowed useful insight into the progression of the rumours. From our findings, we identified that our model was significantly more accurate than similar studies in the literature. We also identified critical attributes of the data that give rise to the trustworthiness scores assigned. Finally we developed a software demonstration that provides a visual user interface to allow the user to examine the analysis.
* 21 pages, 6 figures, 2 tables