 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Autonomous Cyber Operations: A Survey
Oct 11, 2023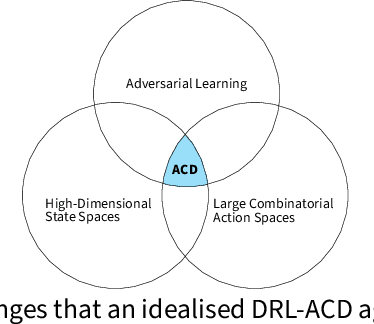
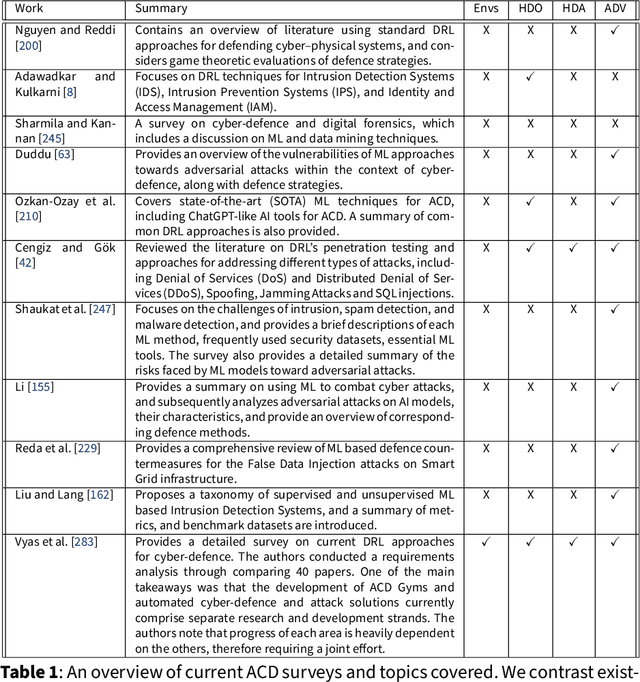
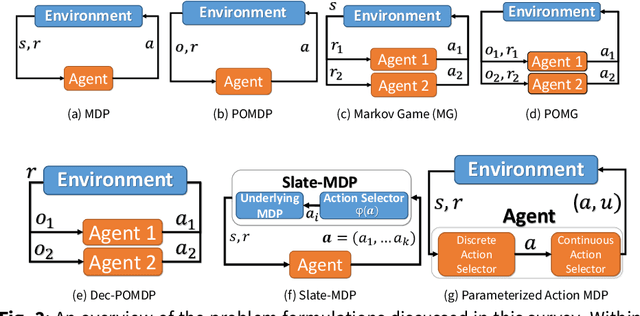
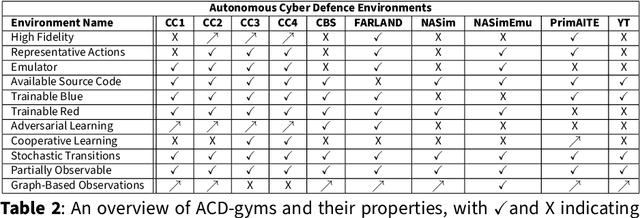
The rapid increase in the number of cyber-attacks in recent years raises the need for principled methods for defending networks against malicious actors. Deep reinforcement learning (DRL) has emerged as a promising approach for mitigating these attacks. However, while DRL has shown much potential for cyber-defence, numerous challenges must be overcome before DRL can be applied to autonomous cyber-operations (ACO) at scale. Principled methods are required for environments that confront learners with very high-dimensional state spaces, large multi-discrete action spaces, and adversarial learning. Recent works have reported success in solving these problems individually. There have also been impressive engineering efforts towards solving all three for real-time strategy games. However, applying DRL to the full ACO problem remains an open challenge. Here, we survey the relevant DRL literature and conceptualize an idealised ACO-DRL agent. We provide: i.) A summary of the domain properties that define the ACO problem; ii.) A comprehensive evaluation of the extent to which domains used for benchmarking DRL approaches are comparable to ACO; iii.) An overview of state-of-the-art approaches for scaling DRL to domains that confront learners with the curse of dimensionality, and; iv.) A survey and critique of current methods for limiting the exploitability of agents within adversarial settings from the perspective of ACO. We conclude with open research questions that we hope will motivate future directions for researchers and practitioners working on ACO.