 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Valuation for Offline Reinforcement Learning
Paper and Code
May 19, 2022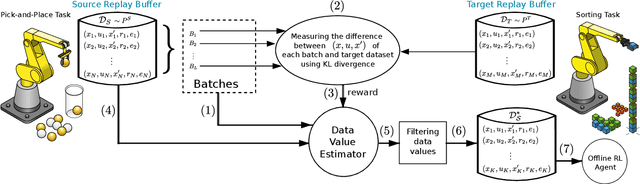
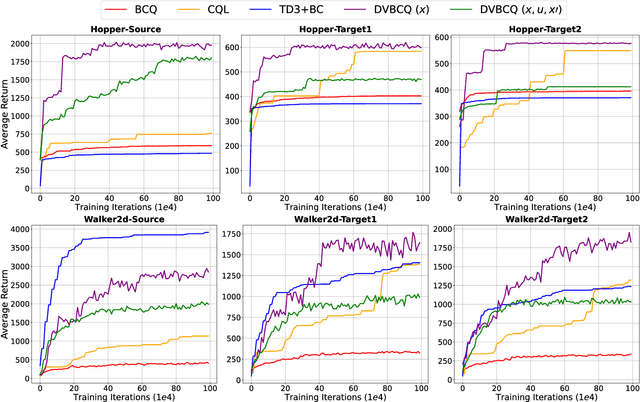
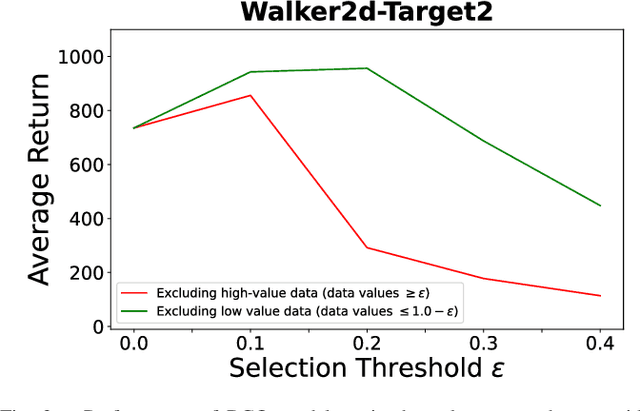
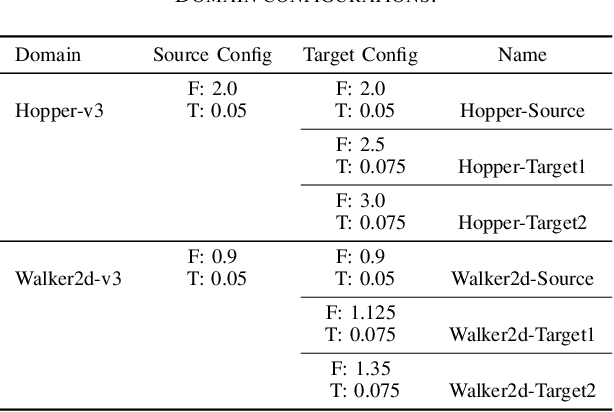
The success of deep reinforcement learning (DRL) hinges on the availability of training data, which is typically obtained via a large number of environment interactions. In many real-world scenarios, costs and risks are associated with gathering these data. The field of offline reinforcement learning addresses these issues through outsourcing the collection of data to a domain expert or a carefully monitored program and subsequently searching for a batch-constrained optimal policy. With the emergence of data markets, an alternative to constructing a dataset in-house is to purchase external data. However, while state-of-the-art offline reinforcement learning approaches have shown a lot of promise, they currently rely on carefully constructed datasets that are well aligned with the intended target domains. This raises questions regarding the transferability and robustness of an offline reinforcement learning agent trained on externally acquired data. In this paper, we empirically evaluate the ability of the current state-of-the-art offline reinforcement learning approaches to coping with the source-target domain mismatch within two MuJoCo environments, finding that current state-of-the-art offline reinforcement learning algorithms underperform in the target domain. To address this, we propose data valuation for offline reinforcement learning (DVORL), which allows us to identify relevant and high-quality transitions, improving the performance and transferability of policies learned by offline reinforcement learning algorithms. The results show that our method outperforms offline reinforcement learning baselines on two MuJoCo environments.