 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Accuracy: Investigating Error Types in GPT-4 Responses to USMLE Questions
Apr 20, 2024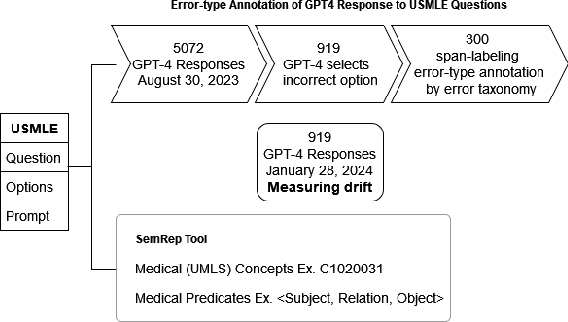
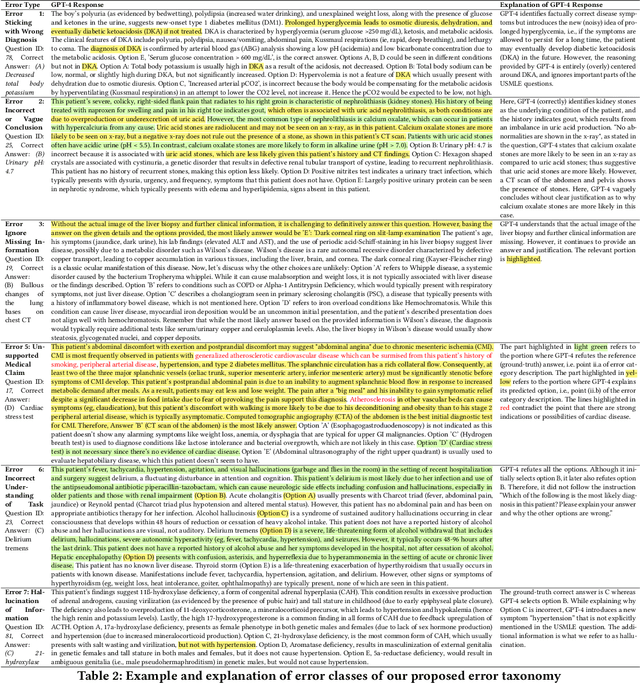
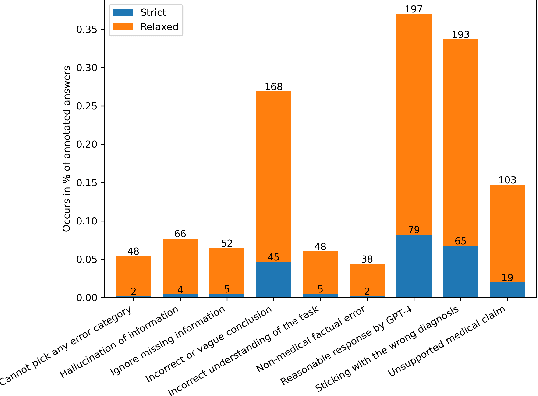

GPT-4 demonstrates high accuracy in medical QA tasks, leading with an accuracy of 86.70%, followed by Med-PaLM 2 at 86.50%. However, around 14% of errors remain. Additionally, current works use GPT-4 to only predict the correct option without providing any explanation and thus do not provide any insight into the thinking process and reasoning used by GPT-4 or other LLMs. Therefore, we introduce a new domain-specific error taxonomy derived from collaboration with medical students. Our GPT-4 USMLE Error (G4UE) dataset comprises 4153 GPT-4 correct responses and 919 incorrect responses to the United States Medical Licensing Examination (USMLE) respectively. These responses are quite long (258 words on average), containing detailed explanations from GPT-4 justifying the selected option. We then launch a large-scale annotation study using the Potato annotation platform and recruit 44 medical experts through Prolific, a well-known crowdsourcing platform. We annotated 300 out of these 919 incorrect data points at a granular level for different classes and created a multi-label span to identify the reasons behind the error. In our annotated dataset, a substantial portion of GPT-4's incorrect responses is categorized as a "Reasonable response by GPT-4," by annotators. This sheds light on the challenge of discerning explanations that may lead to incorrect options, even among trained medical professionals. We also provide medical concepts and medical semantic predications extracted using the SemRep tool for every data point. We believe that it will aid in evaluating the ability of LLMs to answer complex medical questions. We make the resources available at https://github.com/roysoumya/usmle-gpt4-error-taxonomy .
Rites de Passage: Elucidating Displacement to Emplacement of Refugees
May 30, 2022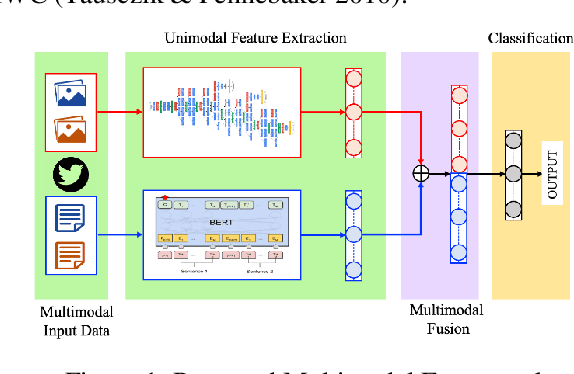



Social media deliberations allow to explore refugee-related is-sues. AI-based studies have investigated refugee issues mostly around a specific event and considered unimodal approaches. Contrarily, we have employed a multimodal architecture for probing the refugee journeys from their home to host nations. We draw insights from Arnold van Gennep's anthropological work 'Les Rites de Passage', which systematically analyzed an individual's transition from one group or society to another. Based on Gennep's separation-transition-incorporation framework, we have identified four phases of refugee journeys: Arrival of Refugees, Temporal stay at Asylums, Rehabilitation, and Integration of Refugees into the host nation. We collected 0.23 million multimodal tweets from April 2020 to March 2021 for testing this proposed frame-work. We find that a combination of transformer-based language models and state-of-the-art image recognition models, such as fusion of BERT+LSTM and InceptionV4, can out-perform unimodal models. Subsequently, to test the practical implication of our proposed model in real-time, we have considered 0.01 million multimodal tweets related to the 2022 Ukrainian refugee crisis. An F1-score of 71.88 % for this 2022 crisis confirms the generalizability of our proposed framework.
Unraveling Social Perceptions & Behaviors towards Migrants on Twitter
Dec 04, 2021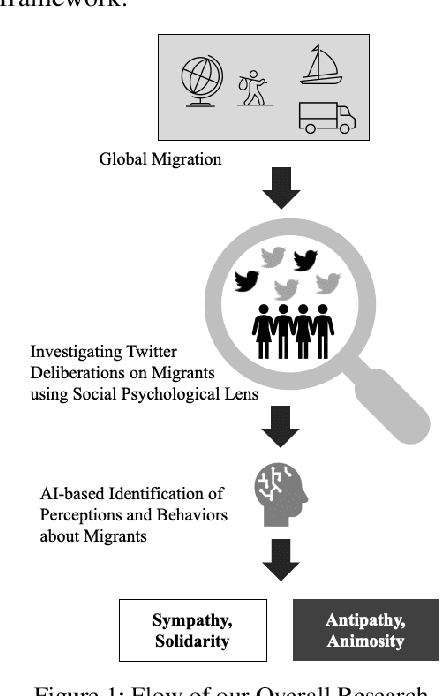

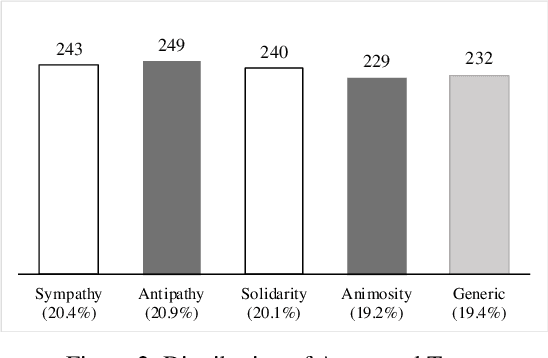
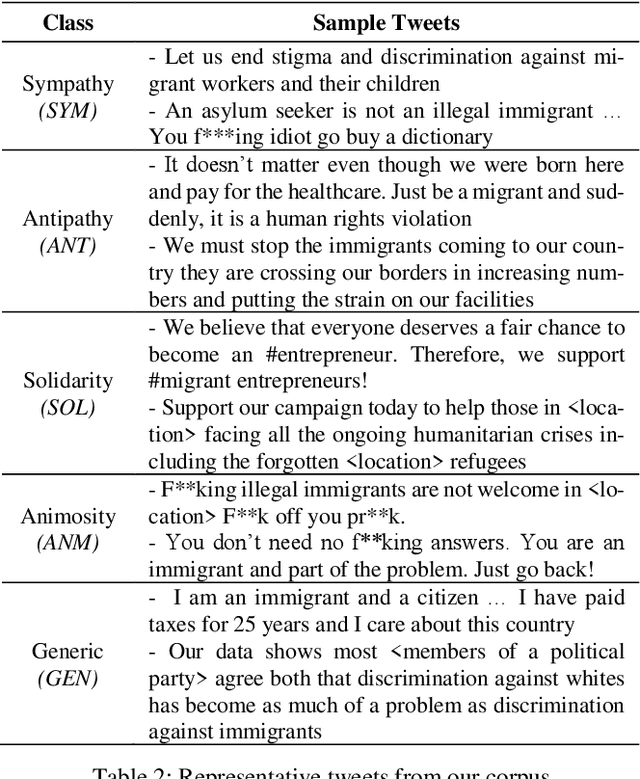
We draw insights from the social psychology literature to identify two facets of Twitter deliberations about migrants, i.e., perceptions about migrants and behaviors towards mi-grants. Our theoretical anchoring helped us in identifying two prevailing perceptions (i.e., sympathy and antipathy) and two dominant behaviors (i.e., solidarity and animosity) of social media users towards migrants. We have employed unsuper-vised and supervised approaches to identify these perceptions and behaviors. In the domain of applied NLP, our study of-fers a nuanced understanding of migrant-related Twitter de-liberations. Our proposed transformer-based model, i.e., BERT + CNN, has reported an F1-score of 0.76 and outper-formed other models. Additionally, we argue that tweets con-veying antipathy or animosity can be broadly considered hate speech towards migrants, but they are not the same. Thus, our approach has fine-tuned the binary hate speech detection task by highlighting the granular differences between perceptual and behavioral aspects of hate speeches.