 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComply: Learning Sentences with Complex Weights inspired by Fruit Fly Olfaction
Feb 03, 2025Biologically inspired neural networks offer alternative avenues to model data distributions. FlyVec is a recent example that draws inspiration from the fruit fly's olfactory circuit to tackle the task of learning word embeddings. Surprisingly, this model performs competitively even against deep learning approaches specifically designed to encode text, and it does so with the highest degree of computational efficiency. We pose the question of whether this performance can be improved further. For this, we introduce Comply. By incorporating positional information through complex weights, we enable a single-layer neural network to learn sequence representations. Our experiments show that Comply not only supersedes FlyVec but also performs on par with significantly larger state-of-the-art models. We achieve this without additional parameters. Comply yields sparse contextual representations of sentences that can be interpreted explicitly from the neuron weights.
VisBERT: Hidden-State Visualizations for Transformers
Nov 09, 2020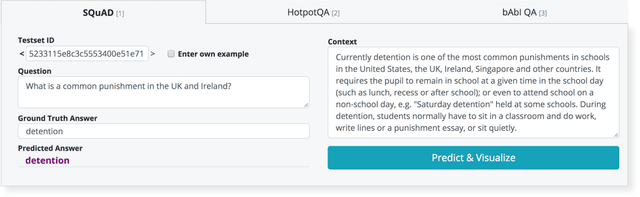
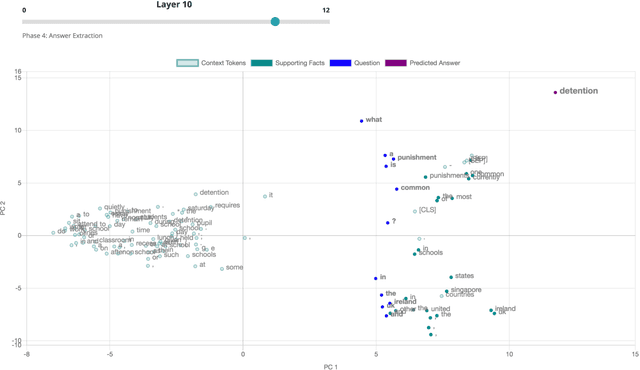
Explainability and interpretability are two important concepts, the absence of which can and should impede the application of well-performing neural networks to real-world problems. At the same time, they are difficult to incorporate into the large, black-box models that achieve state-of-the-art results in a multitude of NLP tasks. Bidirectional Encoder Representations from Transformers (BERT) is one such black-box model. It has become a staple architecture to solve many different NLP tasks and has inspired a number of related Transformer models. Understanding how these models draw conclusions is crucial for both their improvement and application. We contribute to this challenge by presenting VisBERT, a tool for visualizing the contextual token representations within BERT for the task of (multi-hop) Question Answering. Instead of analyzing attention weights, we focus on the hidden states resulting from each encoder block within the BERT model. This way we can observe how the semantic representations are transformed throughout the layers of the model. VisBERT enables users to get insights about the model's internal state and to explore its inference steps or potential shortcomings. The tool allows us to identify distinct phases in BERT's transformations that are similar to a traditional NLP pipeline and offer insights during failed predictions.
* Published in WWW '20: Companion Proceedings of the Web Conference 2020
How Does BERT Answer Questions? A Layer-Wise Analysis of Transformer Representations
Sep 11, 2019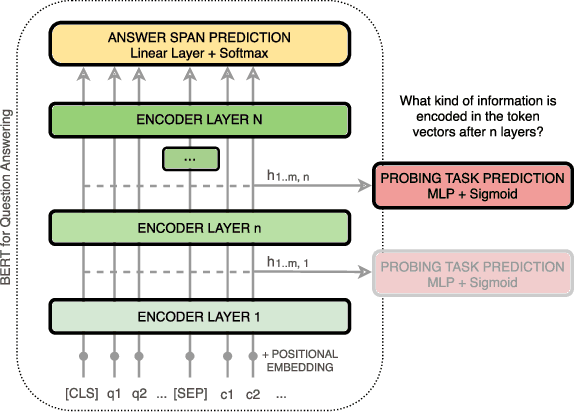


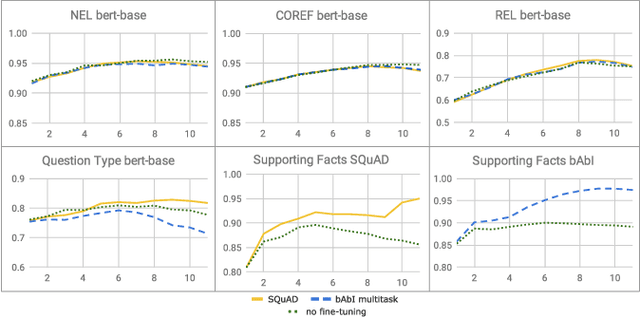
Bidirectional Encoder Representations from Transformers (BERT) reach state-of-the-art results in a variety of Natural Language Processing tasks. However, understanding of their internal functioning is still insufficient and unsatisfactory. In order to better understand BERT and other Transformer-based models, we present a layer-wise analysis of BERT's hidden states. Unlike previous research, which mainly focuses on explaining Transformer models by their attention weights, we argue that hidden states contain equally valuable information. Specifically, our analysis focuses on models fine-tuned on the task of Question Answering (QA) as an example of a complex downstream task. We inspect how QA models transform token vectors in order to find the correct answer. To this end, we apply a set of general and QA-specific probing tasks that reveal the information stored in each representation layer. Our qualitative analysis of hidden state visualizations provides additional insights into BERT's reasoning process. Our results show that the transformations within BERT go through phases that are related to traditional pipeline tasks. The system can therefore implicitly incorporate task-specific information into its token representations. Furthermore, our analysis reveals that fine-tuning has little impact on the models' semantic abilities and that prediction errors can be recognized in the vector representations of even early layers.